 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Paper and Code

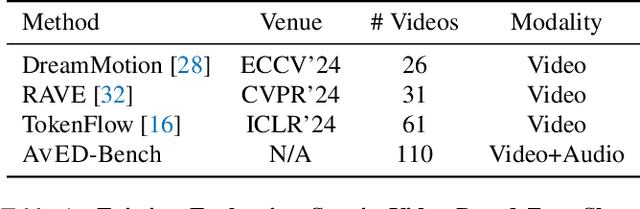
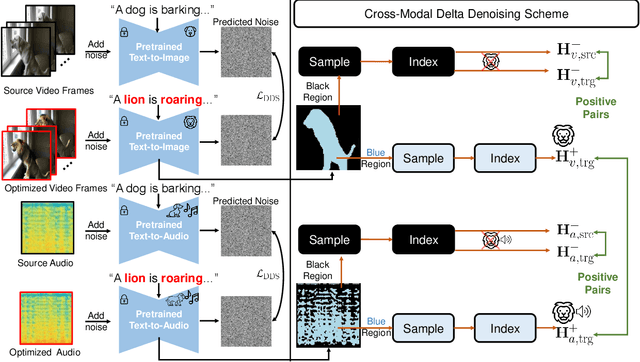
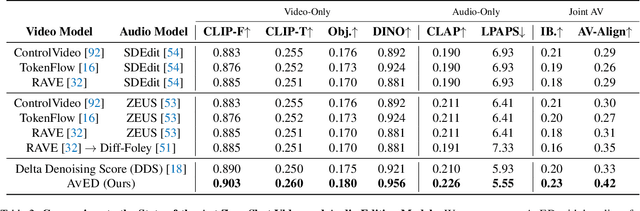
In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html