 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Sound Localization via Iterative Contrastive Learning
Paper and Code
Apr 01, 2021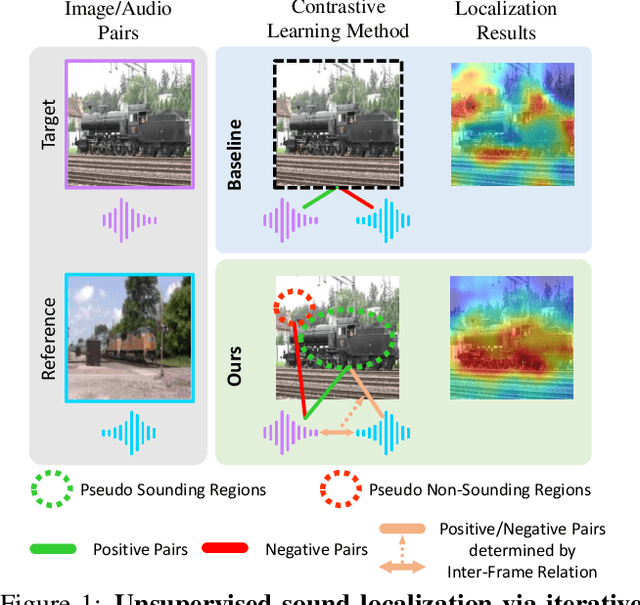
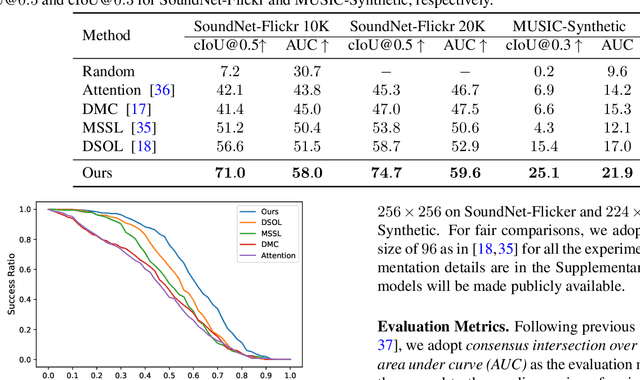

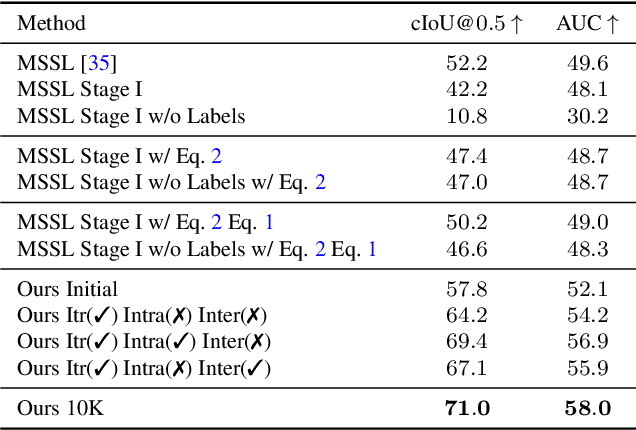
Sound localization aims to find the source of the audio signal in the visual scene. However, it is labor-intensive to annotate the correlations between the signals sampled from the audio and visual modalities, thus making it difficult to supervise the learning of a machine for this task. In this work, we propose an iterative contrastive learning framework that requires no data annotations. At each iteration, the proposed method takes the 1) localization results in images predicted in the previous iteration, and 2) semantic relationships inferred from the audio signals as the pseudo-labels. We then use the pseudo-labels to learn the correlation between the visual and audio signals sampled from the same video (intra-frame sampling) as well as the association between those extracted across videos (inter-frame relation). Our iterative strategy gradually encourages the localization of the sounding objects and reduces the correlation between the non-sounding regions and the reference audio. Quantitative and qualitative experimental results demonstrate that the proposed framework performs favorably against existing unsupervised and weakly-supervised methods on the sound localization task.