 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C^3$: Confidence Calibration Model Cascade for Inference-Efficient Cross-Lingual Natural Language Understanding
Paper and Code
Feb 25, 2024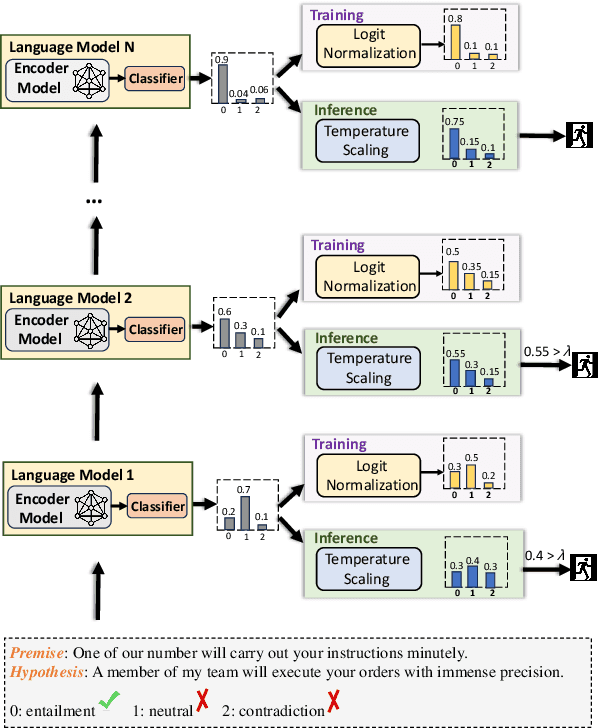
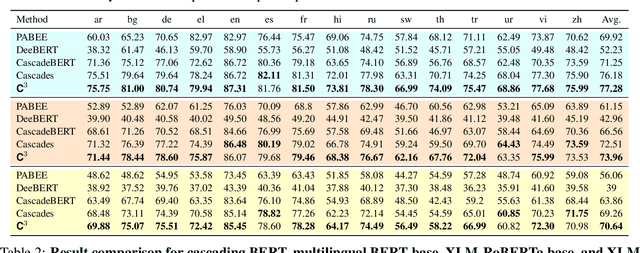

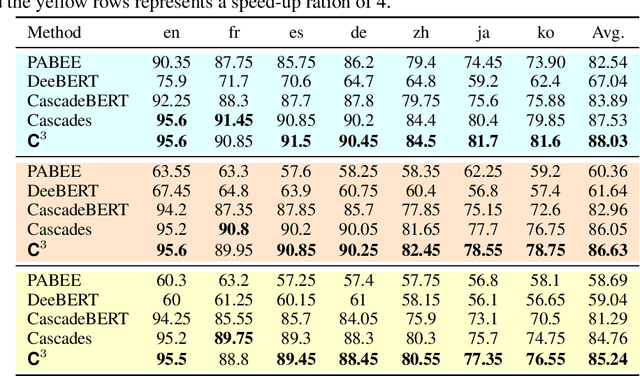
Cross-lingual natural language understanding (NLU) is a critical task in natural language processing (NLP). Recent advancements have seen multilingual pre-trained language models (mPLMs) significantly enhance the performance of these tasks. However, mPLMs necessitate substantial resources and incur high computational costs during inference, posing challenges for deployment in real-world and real-time systems. Existing model cascade methods seek to enhance inference efficiency by greedily selecting the lightest model capable of processing the current input from a variety of models, based on model confidence scores. Nonetheless, deep models tend to exhibit overconfidence, and confidence distributions vary across languages. This leads to the emission of confident but incorrect predictions by smaller models, hindering their ability to generalize effectively across test languages. In this study, we introduce a confidence calibration model cascade ($C^3$) method. This approach, simple yet effective, involves calibration prior to cascade inference, thereby enhancing cascade accuracy through more reliable predictions. Extensive experiments conducted on three cross-lingual benchmarks demonstrate that $C^3$ significantly outperforms all state-of-the-art baselines.