 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Contextual Anomalies by Discovering Consistent Spatial Regions
Jan 14, 2025We describe a method for modeling spatial context to enable video anomaly detection. The main idea is to discover regions that share similar object-level activities by clustering joint object attributes using Gaussian mixture models. We demonstrate that this straightforward approach, using orders of magnitude fewer parameters than competing models, achieves state-of-the-art performance in the challenging spatial-context-dependent Street Scene dataset. As a side benefit, the high-resolution discovered regions learned by the model also provide explainable normalcy maps for human operators without the need for any pre-trained segmentation model.
Few-Shot 3D Volumetric Segmentation with Multi-Surrogate Fusion
Aug 26, 2024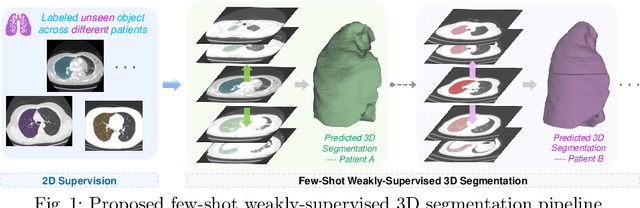
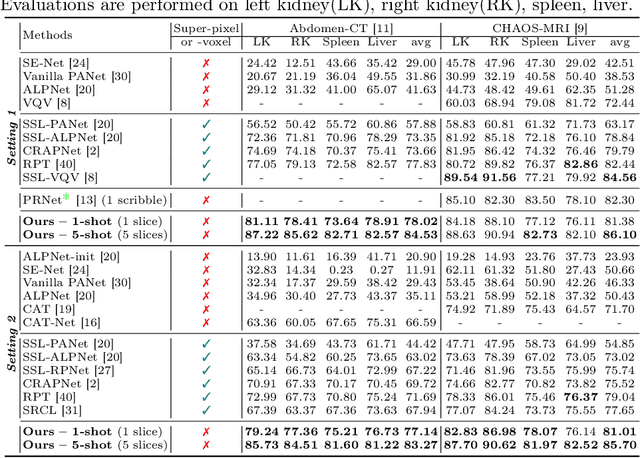
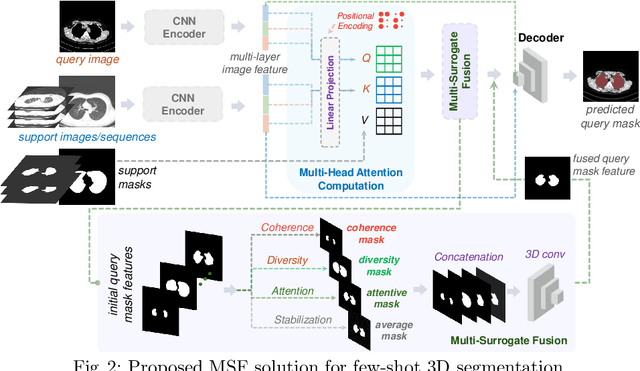
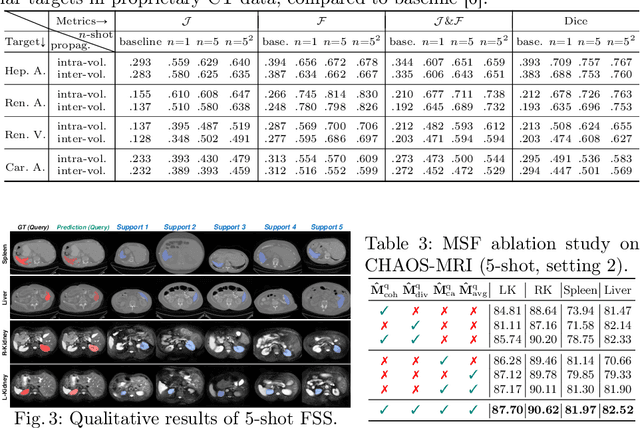
Conventional 3D medical image segmentation methods typically require learning heavy 3D networks (e.g., 3D-UNet), as well as large amounts of in-domain data with accurate pixel/voxel-level labels to avoid overfitting. These solutions are thus extremely time- and labor-expensive, but also may easily fail to generalize to unseen objects during training. To alleviate this issue, we present MSFSeg, a novel few-shot 3D segmentation framework with a lightweight multi-surrogate fusion (MSF). MSFSeg is able to automatically segment unseen 3D objects/organs (during training) provided with one or a few annotated 2D slices or 3D sequence segments, via learning dense query-support organ/lesion anatomy correlations across patient populations. Our proposed MSF module mines comprehensive and diversified morphology correlations between unlabeled and the few labeled slices/sequences through multiple designated surrogates, making it able to generate accurate cross-domain 3D segmentation masks given annotated slices or sequences. We demonstrate the effectiveness of our proposed framework by showing superior performance on conventional few-shot segmentation benchmarks compared to prior art, and remarkable cross-domain cross-volume segmentation performance on proprietary 3D segmentation datasets for challenging entities, i.e., tubular structures, with only limited 2D or 3D labels.
Large Language Models for Automatic Milestone Detection in Group Discussions
Jun 16, 2024Large language models like GPT have proven widely successful on natural language understanding tasks based on written text documents. In this paper, we investigate an LLM's performance on recordings of a group oral communication task in which utterances are often truncated or not well-formed. We propose a new group task experiment involving a puzzle with several milestones that can be achieved in any order. We investigate methods for processing transcripts to detect if, when, and by whom a milestone has been completed. We demonstrate that iteratively prompting GPT with transcription chunks outperforms semantic similarity search methods using text embeddings, and further discuss the quality and randomness of GPT responses under different context window sizes.
Self-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
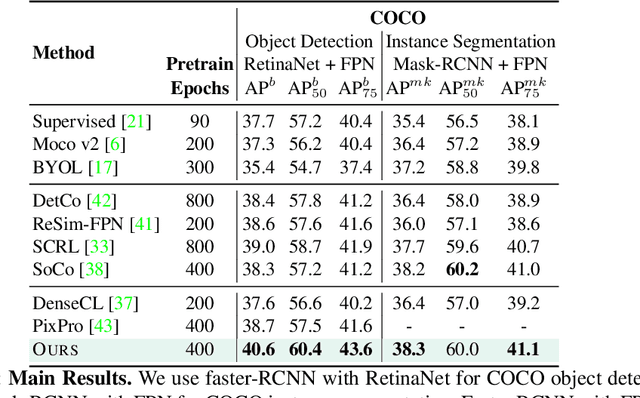
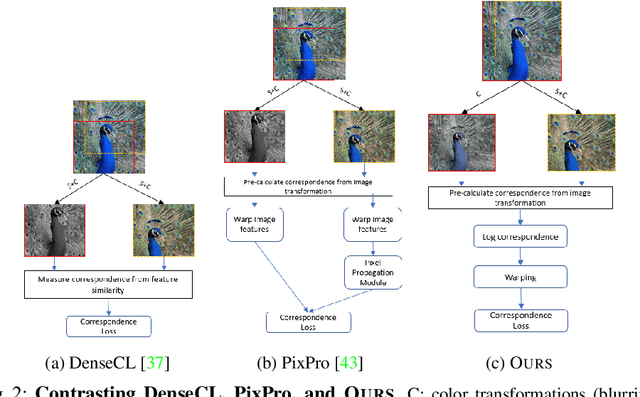
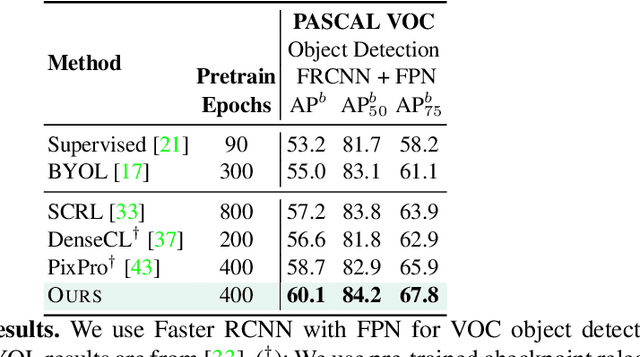
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
Dynamic Distillation Network for Cross-Domain Few-Shot Recognition with Unlabeled Data
Jun 14, 2021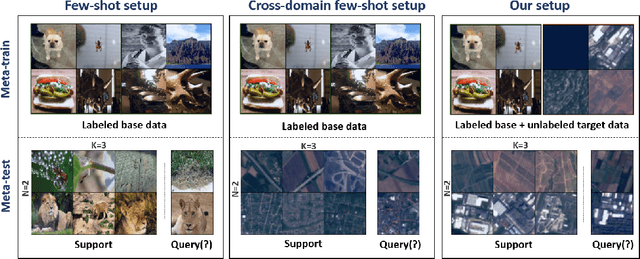
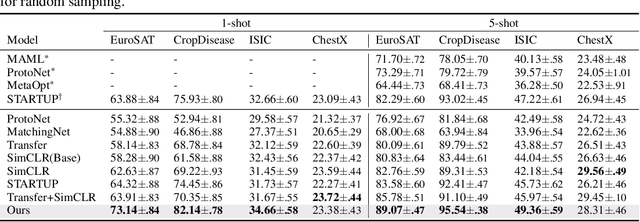


Most existing works in few-shot learning rely on meta-learning the network on a large base dataset which is typically from the same domain as the target dataset. We tackle the problem of cross-domain few-shot learning where there is a large shift between the base and target domain. The problem of cross-domain few-shot recognition with unlabeled target data is largely unaddressed in the literature. STARTUP was the first method that tackles this problem using self-training. However, it uses a fixed teacher pretrained on a labeled base dataset to create soft labels for the unlabeled target samples. As the base dataset and unlabeled dataset are from different domains, projecting the target images in the class-domain of the base dataset with a fixed pretrained model might be sub-optimal. We propose a simple dynamic distillation-based approach to facilitate unlabeled images from the novel/base dataset. We impose consistency regularization by calculating predictions from the weakly-augmented versions of the unlabeled images from a teacher network and matching it with the strongly augmented versions of the same images from a student network. The parameters of the teacher network are updated as exponential moving average of the parameters of the student network. We show that the proposed network learns representation that can be easily adapted to the target domain even though it has not been trained with target-specific classes during the pretraining phase. Our model outperforms the current state-of-the art method by 4.4% for 1-shot and 3.6% for 5-shot classification in the BSCD-FSL benchmark, and also shows competitive performance on traditional in-domain few-shot learning task. Our code will be available at: https://github.com/asrafulashiq/dynamic-cdfsl.
A Hybrid Attention Mechanism for Weakly-Supervised Temporal Action Localization
Jan 11, 2021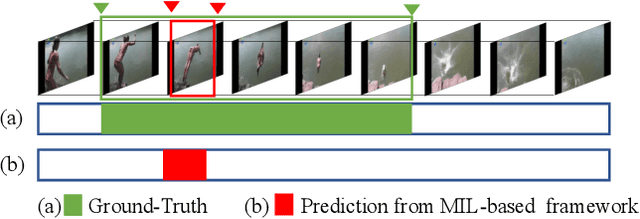


Weakly supervised temporal action localization is a challenging vision task due to the absence of ground-truth temporal locations of actions in the training videos. With only video-level supervision during training, most existing methods rely on a Multiple Instance Learning (MIL) framework to predict the start and end frame of each action category in a video. However, the existing MIL-based approach has a major limitation of only capturing the most discriminative frames of an action, ignoring the full extent of an activity. Moreover, these methods cannot model background activity effectively, which plays an important role in localizing foreground activities. In this paper, we present a novel framework named HAM-Net with a hybrid attention mechanism which includes temporal soft, semi-soft and hard attentions to address these issues. Our temporal soft attention module, guided by an auxiliary background class in the classification module, models the background activity by introducing an "action-ness" score for each video snippet. Moreover, our temporal semi-soft and hard attention modules, calculating two attention scores for each video snippet, help to focus on the less discriminative frames of an action to capture the full action boundary. Our proposed approach outperforms recent state-of-the-art methods by at least 2.2% mAP at IoU threshold 0.5 on the THUMOS14 dataset, and by at least 1.3% mAP at IoU threshold 0.75 on the ActivityNet1.2 dataset. Code can be found at: https://github.com/asrafulashiq/hamnet.
Towards Visually Explaining Similarity Models
Aug 13, 2020



We consider the problem of visually explaining similarity models, i.e., explaining why a model predicts two images to be similar in addition to producing a scalar score. While much recent work in visual model interpretability has focused on gradient-based attention, these methods rely on a classification module to generate visual explanations. Consequently, they cannot readily explain other kinds of models that do not use or need classification-like loss functions (e.g., similarity models trained with a metric learning loss). In this work, we bridge this crucial gap, presenting the first method to generate gradient-based visual explanations for image similarity predictors. By relying solely on the learned feature embedding, we show that our approach can be applied to any kind of CNN-based similarity architecture, an important step towards generic visual explainability. We show that our resulting visual explanations serve more than just interpretability; they can be infused into the model learning process itself with new trainable constraints based on our similarity explanations. We show that the resulting similarity models perform, and can be visually explained, better than the corresponding baseline models trained without our explanation constraints. We demonstrate our approach using extensive experiments on three different kinds of tasks: generic image retrieval, person re-identification, and low-shot semantic segmentation.
Weakly Supervised Temporal Action Localization Using Deep Metric Learning
Jan 21, 2020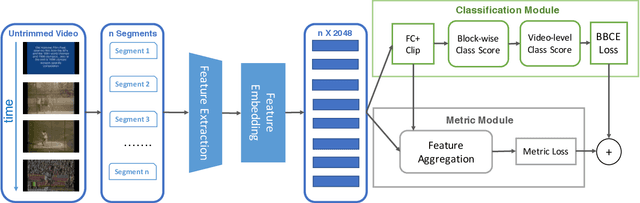
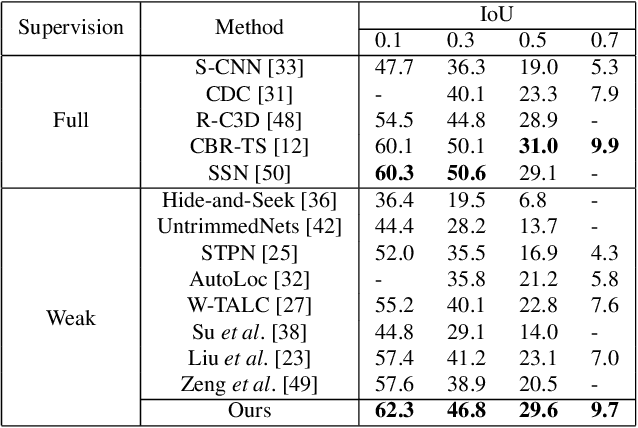

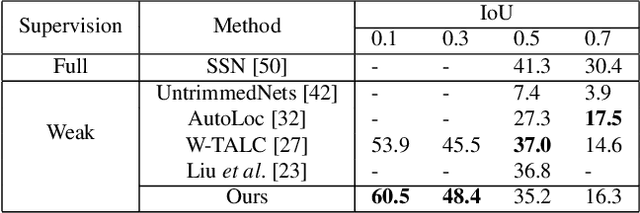
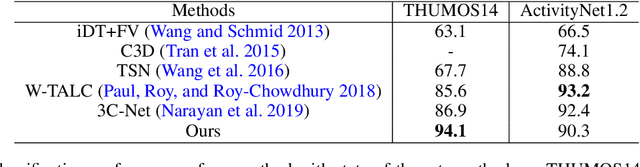
Temporal action localization is an important step towards video understanding. Most current action localization methods depend on untrimmed videos with full temporal annotations of action instances. However, it is expensive and time-consuming to annotate both action labels and temporal boundaries of videos. To this end, we propose a weakly supervised temporal action localization method that only requires video-level action instances as supervision during training. We propose a classification module to generate action labels for each segment in the video, and a deep metric learning module to learn the similarity between different action instances. We jointly optimize a balanced binary cross-entropy loss and a metric loss using a standard backpropagation algorithm. Extensive experiments demonstrate the effectiveness of both of these components in temporal localization. We evaluate our algorithm on two challenging untrimmed video datasets: THUMOS14 and ActivityNet1.2. Our approach improves the current state-of-the-art result for THUMOS14 by 6.5% mAP at IoU threshold 0.5, and achieves competitive performance for ActivityNet1.2.
Towards Visually Explaining Variational Autoencoders
Nov 18, 2019

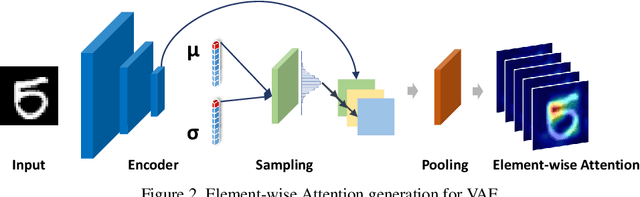

Recent advances in Convolutional Neural Network (CNN) model interpretability have led to impressive progress in visualizing and understanding model predictions. In particular, gradient-based visual attention methods have driven much recent effort in using visual attention maps as a means for visual explanations. A key problem, however, is these methods are designed for classification and categorization tasks, and their extension to explaining generative models, \eg, variational autoencoders (VAE) is not trivial. In this work, we take a step towards bridging this crucial gap, proposing the first technique to visually explain VAEs by means of gradient-based attention. We present methods to generate visual attention from the learned latent space, and also demonstrate such attention explanations serve more than just explaining VAE predictions. We show how these attention maps can be used to localize anomalies in images, demonstrating state-of-the-art performance on the MVTec-AD dataset. We also show how they can be infused into model training, helping bootstrap the VAE into learning improved latent space disentanglement, demonstrated on the Dsprites dataset.
Learning Similarity Attention
Nov 18, 2019



We consider the problem of learning similarity functions. While there has been substantial progress in learning suitable distance metrics, these techniques in general lack decision reasoning, i.e., explaining why the input set of images is similar or dissimilar. In this work, we solve this key problem by proposing the first method to generate generic visual similarity explanations with gradient-based attention. We demonstrate that our technique is agnostic to the specific similarity model type, e.g., we show applicability to Siamese, triplet, and quadruplet models. Furthermore, we make our proposed similarity attention a principled part of the learning process, resulting in a new paradigm for learning similarity functions. We demonstrate that our learning mechanism results in more generalizable, as well as explainable, similarity models. Finally, we demonstrate the generality of our framework by means of experiments on a variety of tasks, including image retrieval, person re-identification, and low-shot semantic segmentation.