 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEBench: A Novel Benchmark for Understanding Mutual Exclusivity Bias in Vision-Language Models
May 26, 2025


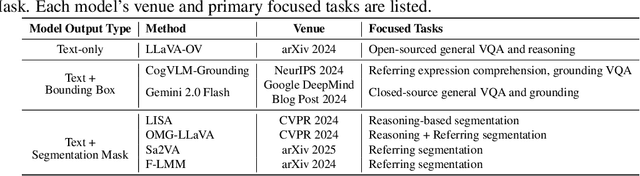
This paper introduces MEBench, a novel benchmark for evaluating mutual exclusivity (ME) bias, a cognitive phenomenon observed in children during word learning. Unlike traditional ME tasks, MEBench further incorporates spatial reasoning to create more challenging and realistic evaluation settings. We assess the performance of state-of-the-art vision-language models (VLMs) on this benchmark using novel evaluation metrics that capture key aspects of ME-based reasoning. To facilitate controlled experimentation, we also present a flexible and scalable data generation pipeline that supports the construction of diverse annotated scenes.
SplatTalk: 3D VQA with Gaussian Splatting
Mar 08, 2025Language-guided 3D scene understanding is important for advancing applications in robotics, AR/VR, and human-computer interaction, enabling models to comprehend and interact with 3D environments through natural language. While 2D vision-language models (VLMs) have achieved remarkable success in 2D VQA tasks, progress in the 3D domain has been significantly slower due to the complexity of 3D data and the high cost of manual annotations. In this work, we introduce SplatTalk, a novel method that uses a generalizable 3D Gaussian Splatting (3DGS) framework to produce 3D tokens suitable for direct input into a pretrained LLM, enabling effective zero-shot 3D visual question answering (3D VQA) for scenes with only posed images. During experiments on multiple benchmarks, our approach outperforms both 3D models trained specifically for the task and previous 2D-LMM-based models utilizing only images (our setting), while achieving competitive performance with state-of-the-art 3D LMMs that additionally utilize 3D inputs.
Symmetry Strikes Back: From Single-Image Symmetry Detection to 3D Generation
Nov 26, 2024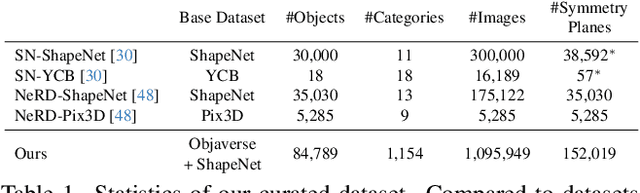
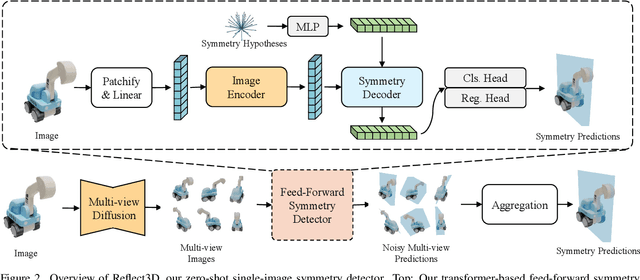
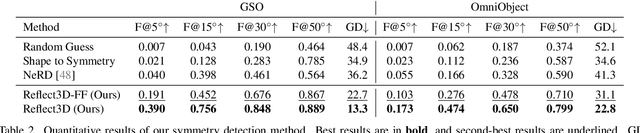
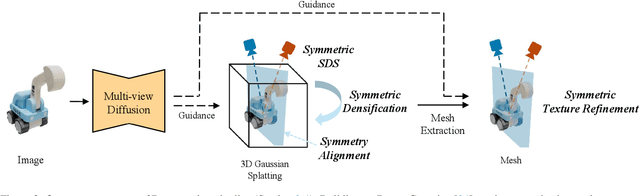
Symmetry is a ubiquitous and fundamental property in the visual world, serving as a critical cue for perception and structure interpretation. This paper investigates the detection of 3D reflection symmetry from a single RGB image, and reveals its significant benefit on single-image 3D generation. We introduce Reflect3D, a scalable, zero-shot symmetry detector capable of robust generalization to diverse and real-world scenarios. Inspired by the success of foundation models, our method scales up symmetry detection with a transformer-based architecture. We also leverage generative priors from multi-view diffusion models to address the inherent ambiguity in single-view symmetry detection. Extensive evaluations on various data sources demonstrate that Reflect3D establishes a new state-of-the-art in single-image symmetry detection. Furthermore, we show the practical benefit of incorporating detected symmetry into single-image 3D generation pipelines through a symmetry-aware optimization process. The integration of symmetry significantly enhances the structural accuracy, cohesiveness, and visual fidelity of the reconstructed 3D geometry and textures, advancing the capabilities of 3D content creation.
Leveraging Object Priors for Point Tracking
Sep 09, 2024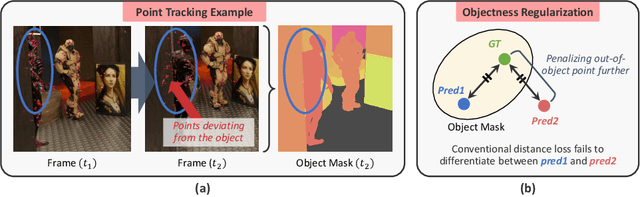
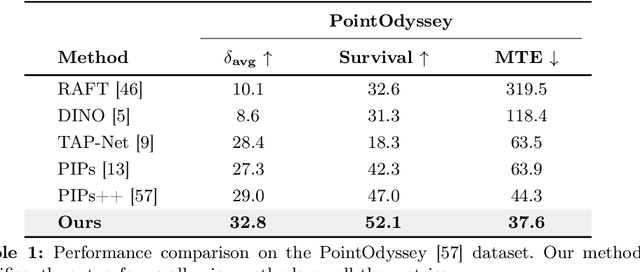
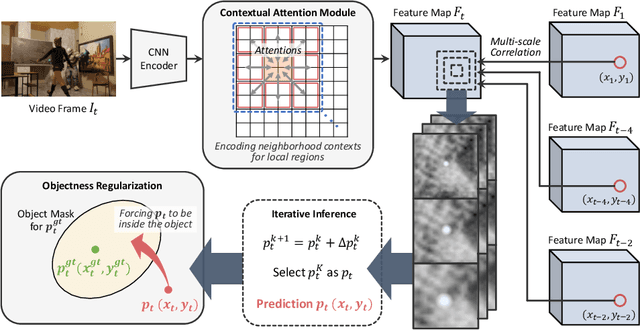

Point tracking is a fundamental problem in computer vision with numerous applications in AR and robotics. A common failure mode in long-term point tracking occurs when the predicted point leaves the object it belongs to and lands on the background or another object. We identify this as the failure to correctly capture objectness properties in learning to track. To address this limitation of prior work, we propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. By capturing objectness cues at training time, we avoid the need to compute object masks during testing. In addition, we leverage contextual attention to enhance the feature representation for capturing objectness at the feature level more effectively. As a result, our approach achieves state-of-the-art performance on three point tracking benchmarks, and we further validate the effectiveness of our components via ablation studies. The source code is available at: https://github.com/RehgLab/tracking_objectness
3x2: 3D Object Part Segmentation by 2D Semantic Correspondences
Jul 12, 2024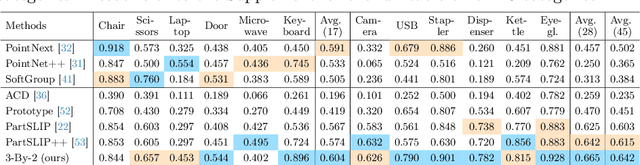

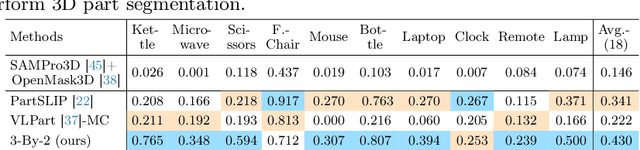
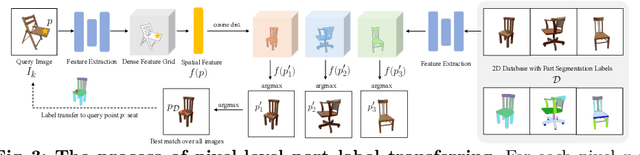
3D object part segmentation is essential in computer vision applications. While substantial progress has been made in 2D object part segmentation, the 3D counterpart has received less attention, in part due to the scarcity of annotated 3D datasets, which are expensive to collect. In this work, we propose to leverage a few annotated 3D shapes or richly annotated 2D datasets to perform 3D object part segmentation. We present our novel approach, termed 3-By-2 that achieves SOTA performance on different benchmarks with various granularity levels. By using features from pretrained foundation models and exploiting semantic and geometric correspondences, we are able to overcome the challenges of limited 3D annotations. Our approach leverages available 2D labels, enabling effective 3D object part segmentation. Our method 3-By-2 can accommodate various part taxonomies and granularities, demonstrating interesting part label transfer ability across different object categories. Project website: \url{https://ngailapdi.github.io/projects/3by2/}.
ZeroShape: Regression-based Zero-shot Shape Reconstruction
Jan 16, 2024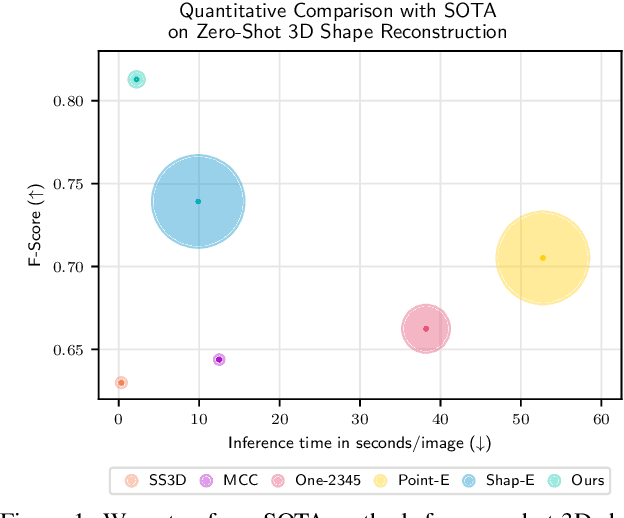
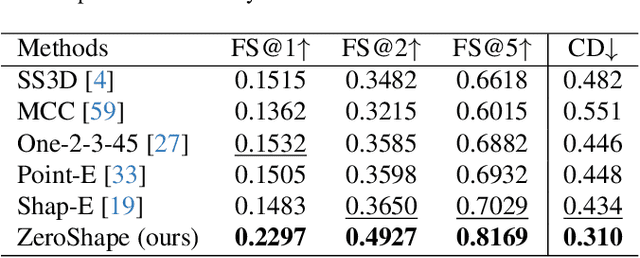

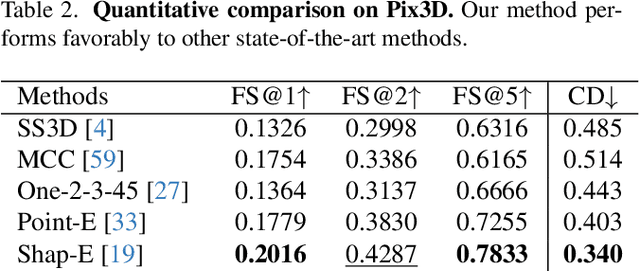
We study the problem of single-image zero-shot 3D shape reconstruction. Recent works learn zero-shot shape reconstruction through generative modeling of 3D assets, but these models are computationally expensive at train and inference time. In contrast, the traditional approach to this problem is regression-based, where deterministic models are trained to directly regress the object shape. Such regression methods possess much higher computational efficiency than generative methods. This raises a natural question: is generative modeling necessary for high performance, or conversely, are regression-based approaches still competitive? To answer this, we design a strong regression-based model, called ZeroShape, based on the converging findings in this field and a novel insight. We also curate a large real-world evaluation benchmark, with objects from three different real-world 3D datasets. This evaluation benchmark is more diverse and an order of magnitude larger than what prior works use to quantitatively evaluate their models, aiming at reducing the evaluation variance in our field. We show that ZeroShape not only achieves superior performance over state-of-the-art methods, but also demonstrates significantly higher computational and data efficiency.
Low-shot Object Learning with Mutual Exclusivity Bias
Dec 06, 2023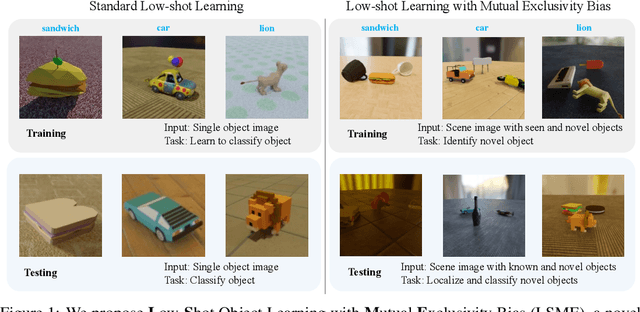

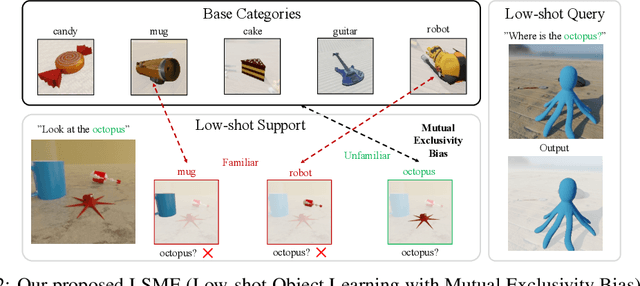
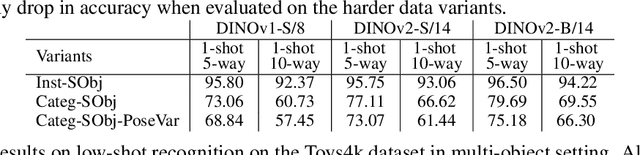
This paper introduces Low-shot Object Learning with Mutual Exclusivity Bias (LSME), the first computational framing of mutual exclusivity bias, a phenomenon commonly observed in infants during word learning. We provide a novel dataset, comprehensive baselines, and a state-of-the-art method to enable the ML community to tackle this challenging learning task. The goal of LSME is to analyze an RGB image of a scene containing multiple objects and correctly associate a previously-unknown object instance with a provided category label. This association is then used to perform low-shot learning to test category generalization. We provide a data generation pipeline for the LSME problem and conduct a thorough analysis of the factors that contribute to its difficulty. Additionally, we evaluate the performance of multiple baselines, including state-of-the-art foundation models. Finally, we present a baseline approach that outperforms state-of-the-art models in terms of low-shot accuracy.
ShapeClipper: Scalable 3D Shape Learning from Single-View Images via Geometric and CLIP-based Consistency
Apr 13, 2023

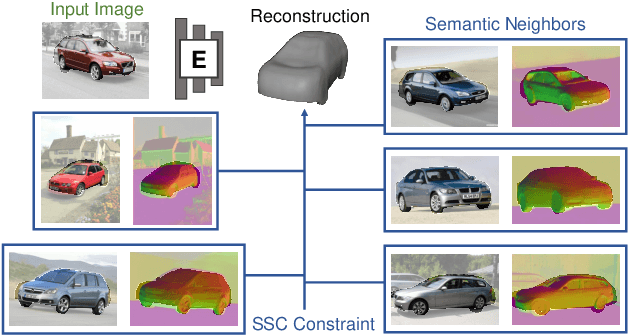
We present ShapeClipper, a novel method that reconstructs 3D object shapes from real-world single-view RGB images. Instead of relying on laborious 3D, multi-view or camera pose annotation, ShapeClipper learns shape reconstruction from a set of single-view segmented images. The key idea is to facilitate shape learning via CLIP-based shape consistency, where we encourage objects with similar CLIP encodings to share similar shapes. We also leverage off-the-shelf normals as an additional geometric constraint so the model can learn better bottom-up reasoning of detailed surface geometry. These two novel consistency constraints, when used to regularize our model, improve its ability to learn both global shape structure and local geometric details. We evaluate our method over three challenging real-world datasets, Pix3D, Pascal3D+, and OpenImages, where we achieve superior performance over state-of-the-art methods.
Learning Dense Object Descriptors from Multiple Views for Low-shot Category Generalization
Nov 28, 2022A hallmark of the deep learning era for computer vision is the successful use of large-scale labeled datasets to train feature representations for tasks ranging from object recognition and semantic segmentation to optical flow estimation and novel view synthesis of 3D scenes. In this work, we aim to learn dense discriminative object representations for low-shot category recognition without requiring any category labels. To this end, we propose Deep Object Patch Encodings (DOPE), which can be trained from multiple views of object instances without any category or semantic object part labels. To train DOPE, we assume access to sparse depths, foreground masks and known cameras, to obtain pixel-level correspondences between views of an object, and use this to formulate a self-supervised learning task to learn discriminative object patches. We find that DOPE can directly be used for low-shot classification of novel categories using local-part matching, and is competitive with and outperforms supervised and self-supervised learning baselines. Code and data available at https://github.com/rehg-lab/dope_selfsup.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022

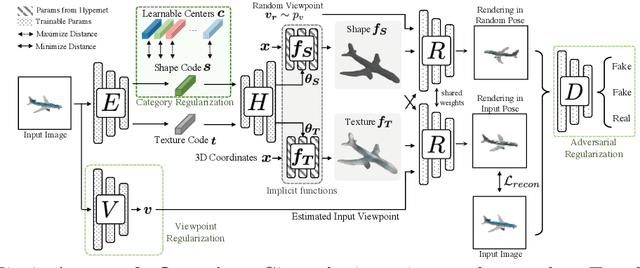
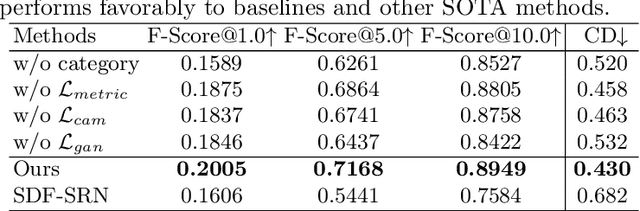
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.