 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLM-Based Test Generation Under Software Evolution
Mar 24, 2026Large Language Models (LLMs) are increasingly used for automated unit test generation. However, it remains unclear whether these tests reflect genuine reasoning about program behavior or simply reproduce superficial patterns learned during training. If the latter dominates, LLM-generated tests may exhibit weaknesses such as reduced coverage, missed regressions, and undetected faults. Understanding how LLMs generate tests and how those tests respond to code evolution is therefore essential. We present a large-scale empirical study of LLM-based test generation under program changes. Using an automated mutation-driven framework, we analyze how generated tests react to semantic-altering changes (SAC) and semantic-preserving changes (SPC) across eight LLMs and 22,374 program variants. LLMs achieve strong baseline results, reaching 79% line coverage and 76% branch coverage with fully passing test suites on the original programs. However, performance degrades as programs evolve. Under SACs, the pass rate of newly generated tests drops to 66%, and branch coverage declines to 60%. More than 99% of failing SAC tests pass on the original program while executing the modified region, indicating residual alignment with the original behavior rather than adaptation to updated semantics. Performance also declines under SPCs despite unchanged functionality: pass rates fall to 79% and branch coverage to 69%. Although SPC edits preserve semantics, they often introduce larger syntactic changes, leading to instability in generated test suites. Models generate more new tests while discarding many baseline tests, suggesting sensitivity to lexical changes rather than true semantic impact. Overall, our results indicate that current LLM-based test generation relies heavily on surface-level cues and struggles to maintain regression awareness as programs evolve.
How Accurately Do Large Language Models Understand Code?
Apr 09, 2025
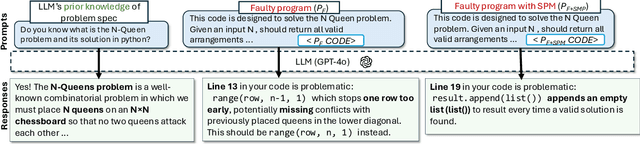


Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.