 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
Hybrid Learning and Optimization-Based Dynamic Scheduling for DL Workloads on Heterogeneous GPU Clusters
Dec 11, 2025Modern cloud platforms increasingly host large-scale deep learning (DL) workloads, demanding high-throughput, low-latency GPU scheduling. However, the growing heterogeneity of GPU clusters and limited visibility into application characteristics pose major challenges for existing schedulers, which often rely on offline profiling or application-specific assumptions. We present RLTune, an application-agnostic reinforcement learning (RL)-based scheduling framework that dynamically prioritizes and allocates DL jobs on heterogeneous GPU clusters. RLTune integrates RL-driven prioritization with MILP-based job-to-node mapping to optimize system-wide objectives such as job completion time (JCT), queueing delay, and resource utilization. Trained on large-scale production traces from Microsoft Philly, Helios, and Alibaba, RLTune improves GPU utilization by up to 20%, reduces queueing delay by up to 81%, and shortens JCT by as much as 70 percent. Unlike prior approaches, RLTune generalizes across diverse workloads without requiring per-job profiling, making it practical for cloud providers to deploy at scale for more efficient, fair, and sustainable DL workload management.
10Cache: Heterogeneous Resource-Aware Tensor Caching and Migration for LLM Training
Nov 18, 2025


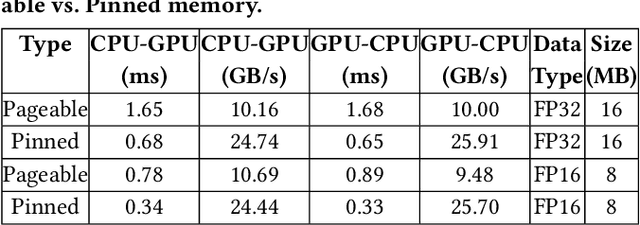
Training large language models (LLMs) in the cloud faces growing memory bottlenecks due to the limited capacity and high cost of GPUs. While GPU memory offloading to CPU and NVMe has made large-scale training more feasible, existing approaches suffer from high tensor migration latency and suboptimal device memory utilization, ultimately increasing training time and cloud costs. To address these challenges, we present 10Cache, a resource-aware tensor caching and migration system that accelerates LLM training by intelligently coordinating memory usage across GPU, CPU, and NVMe tiers. 10Cache profiles tensor execution order to construct prefetch policies, allocates memory buffers in pinned memory based on tensor size distributions, and reuses memory buffers to minimize allocation overhead. Designed for cloud-scale deployments, 10Cache improves memory efficiency and reduces reliance on high-end GPUs. Across diverse LLM workloads, it achieves up to 2x speedup in training time, improves GPU cache hit rate by up to 86.6x, and increases CPU/GPU memory utilization by up to 2.15x and 1.33x, respectively, compared to state-of-the-art offloading methods. These results demonstrate that 10Cache is a practical and scalable solution for optimizing LLM training throughput and resource efficiency in cloud environments.
How Accurately Do Large Language Models Understand Code?
Apr 09, 2025
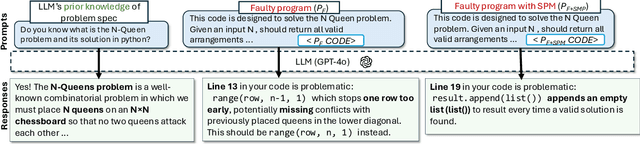


Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.
LADs: Leveraging LLMs for AI-Driven DevOps
Feb 28, 2025
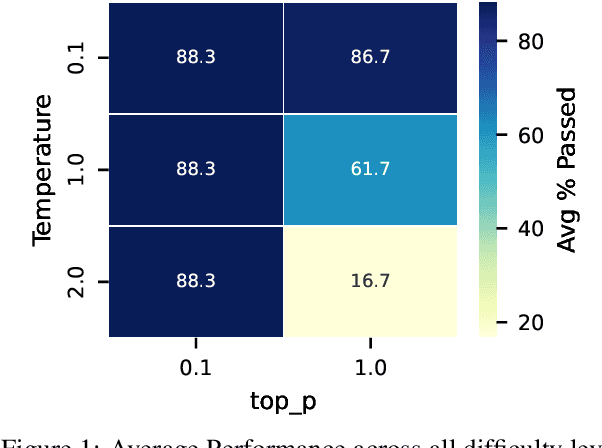
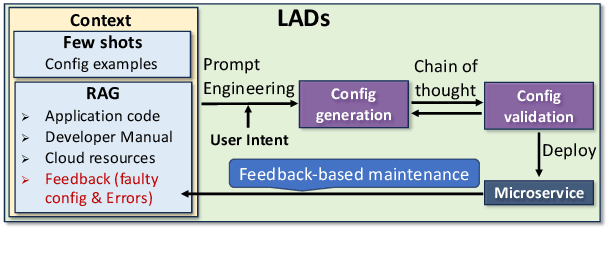

Automating cloud configuration and deployment remains a critical challenge due to evolving infrastructures, heterogeneous hardware, and fluctuating workloads. Existing solutions lack adaptability and require extensive manual tuning, leading to inefficiencies and misconfigurations. We introduce LADs, the first LLM-driven framework designed to tackle these challenges by ensuring robustness, adaptability, and efficiency in automated cloud management. Instead of merely applying existing techniques, LADs provides a principled approach to configuration optimization through in-depth analysis of what optimization works under which conditions. By leveraging Retrieval-Augmented Generation, Few-Shot Learning, Chain-of-Thought, and Feedback-Based Prompt Chaining, LADs generates accurate configurations and learns from deployment failures to iteratively refine system settings. Our findings reveal key insights into the trade-offs between performance, cost, and scalability, helping practitioners determine the right strategies for different deployment scenarios. For instance, we demonstrate how prompt chaining-based adaptive feedback loops enhance fault tolerance in multi-tenant environments and how structured log analysis with example shots improves configuration accuracy. Through extensive evaluations, LADs reduces manual effort, optimizes resource utilization, and improves system reliability. By open-sourcing LADs, we aim to drive further innovation in AI-powered DevOps automation.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
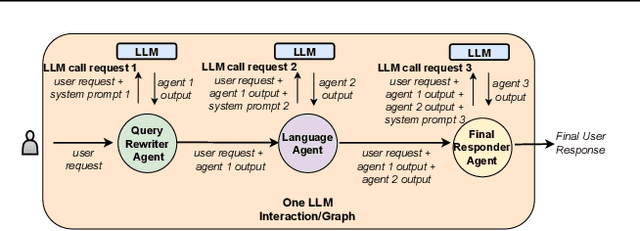
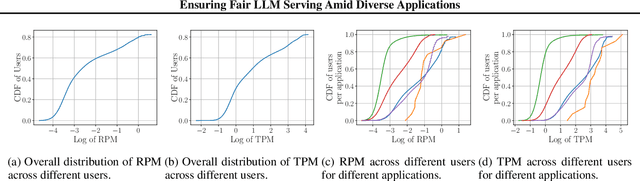
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.