 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProToken: Token-Level Attribution for Federated Large Language Models
Jan 27, 2026Federated Learning (FL) enables collaborative training of Large Language Models (LLMs) across distributed data sources while preserving privacy. However, when federated LLMs are deployed in critical applications, it remains unclear which client(s) contributed to specific generated responses, hindering debugging, malicious client identification, fair reward allocation, and trust verification. We present ProToken, a novel Provenance methodology for Token-level attribution in federated LLMs that addresses client attribution during autoregressive text generation while maintaining FL privacy constraints. ProToken leverages two key insights to enable provenance at each token: (1) transformer architectures concentrate task-specific signals in later blocks, enabling strategic layer selection for computational tractability, and (2) gradient-based relevance weighting filters out irrelevant neural activations, focusing attribution on neurons that directly influence token generation. We evaluate ProToken across 16 configurations spanning four LLM architectures (Gemma, Llama, Qwen, SmolLM) and four domains (medical, financial, mathematical, coding). ProToken achieves 98% average attribution accuracy in correctly localizing responsible client(s), and maintains high accuracy when the number of clients are scaled, validating its practical viability for real-world deployment settings.
Toward Adaptive Grid Resilience: A Gradient-Free Meta-RL Framework for Critical Load Restoration
Jan 16, 2026Restoring critical loads after extreme events demands adaptive control to maintain distribution-grid resilience, yet uncertainty in renewable generation, limited dispatchable resources, and nonlinear dynamics make effective restoration difficult. Reinforcement learning (RL) can optimize sequential decisions under uncertainty, but standard RL often generalizes poorly and requires extensive retraining for new outage configurations or generation patterns. We propose a meta-guided gradient-free RL (MGF-RL) framework that learns a transferable initialization from historical outage experiences and rapidly adapts to unseen scenarios with minimal task-specific tuning. MGF-RL couples first-order meta-learning with evolutionary strategies, enabling scalable policy search without gradient computation while accommodating nonlinear, constrained distribution-system dynamics. Experiments on IEEE 13-bus and IEEE 123-bus test systems show that MGF-RL outperforms standard RL, MAML-based meta-RL, and model predictive control across reliability, restoration speed, and adaptation efficiency under renewable forecast errors. MGF-RL generalizes to unseen outages and renewable patterns while requiring substantially fewer fine-tuning episodes than conventional RL. We also provide sublinear regret bounds that relate adaptation efficiency to task similarity and environmental variation, supporting the empirical gains and motivating MGF-RL for real-time load restoration in renewable-rich distribution grids.
How Accurately Do Large Language Models Understand Code?
Apr 09, 2025
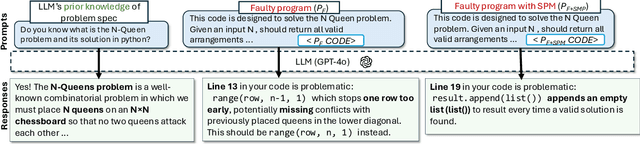


Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.
Advancing Semantic Caching for LLMs with Domain-Specific Embeddings and Synthetic Data
Apr 03, 2025This report investigates enhancing semantic caching effectiveness by employing specialized, fine-tuned embedding models. Semantic caching relies on embedding similarity rather than exact key matching, presenting unique challenges in balancing precision, query latency, and computational efficiency. We propose leveraging smaller, domain-specific embedding models, fine-tuned with targeted real-world and synthetically generated datasets. Our empirical evaluations demonstrate that compact embedding models fine-tuned for just one epoch on specialized datasets significantly surpass both state-of-the-art open-source and proprietary alternatives in precision and recall. Moreover, we introduce a novel synthetic data generation pipeline for the semantic cache that mitigates the challenge of limited domain-specific annotated data, further boosting embedding performance. Our approach effectively balances computational overhead and accuracy, establishing a viable and efficient strategy for practical semantic caching implementations.
Privacy-Aware Semantic Cache for Large Language Models
Mar 05, 2024Large Language Models (LLMs) like ChatGPT, Google Bard, Claude, and Llama 2 have revolutionized natural language processing and search engine dynamics. However, these models incur exceptionally high computational costs. For instance, GPT-3 consists of 175 billion parameters and inference on these models also demands billions of floating-point operations. Caching is a natural solution to reduce LLM inference costs on repeated queries. However, existing caching methods are incapable of finding semantic similarities among LLM queries, leading to unacceptable false hit-and-miss rates. This paper introduces MeanCache, a semantic cache for LLMs that identifies semantically similar queries to determine cache hit or miss. Using MeanCache, the response to a user's semantically similar query can be retrieved from a local cache rather than re-querying the LLM, thus reducing costs, service provider load, and environmental impact. MeanCache leverages Federated Learning (FL) to collaboratively train a query similarity model in a distributed manner across numerous users without violating privacy. By placing a local cache in each user's device and using FL, MeanCache reduces the latency and costs and enhances model performance, resulting in lower cache false hit rates. Our experiments, benchmarked against the GPTCache, reveal that MeanCache attains an approximately 17% higher F-score and a 20% increase in precision during semantic cache hit-and-miss decisions. Furthermore, MeanCache reduces the storage requirement by 83% and accelerates semantic cache hit-and-miss decisions by 11%, while still surpassing GPTCache.
ProvFL: Client-Driven Interpretability of Global Model Predictions in Federated Learning
Dec 21, 2023



Federated Learning (FL) trains a collaborative machine learning model by aggregating multiple privately trained clients' models over several training rounds. Such a long, continuous action of model aggregations poses significant challenges in reasoning about the origin and composition of such a global model. Regardless of the quality of the global model or if it has a fault, understanding the model's origin is equally important for debugging, interpretability, and explainability in federated learning. FL application developers often question: (1) what clients contributed towards a global model and (2) if a global model predicts a label, which clients are responsible for it? We introduce, neuron provenance, a fine-grained lineage capturing mechanism that tracks the flow of information between the individual participating clients in FL and the final global model. We operationalize this concept in ProvFL that functions on two key principles. First, recognizing that monitoring every neuron of every client's model statically is ineffective and noisy due to the uninterpretable nature of individual neurons, ProvFL dynamically isolates influential and sensitive neurons in the global model, significantly reducing the search space. Second, as multiple clients' models are fused in each round to form a global model, tracking each client's contribution becomes challenging. ProvFL leverages the invertible nature of fusion algorithms to precisely isolate each client's contribution derived from selected neurons. When asked to localize the clients responsible for the given behavior (i.e., prediction) of the global model, ProvFL successfully localizes them with an average provenance accuracy of 97%. Additionally, ProvFL outperforms the state-of-the-art FL fault localization approach by an average margin of 50%.
FedDefender: Backdoor Attack Defense in Federated Learning
Jul 02, 2023



Federated Learning (FL) is a privacy-preserving distributed machine learning technique that enables individual clients (e.g., user participants, edge devices, or organizations) to train a model on their local data in a secure environment and then share the trained model with an aggregator to build a global model collaboratively. In this work, we propose FedDefender, a defense mechanism against targeted poisoning attacks in FL by leveraging differential testing. Our proposed method fingerprints the neuron activations of clients' models on the same input and uses differential testing to identify a potentially malicious client containing a backdoor. We evaluate FedDefender using MNIST and FashionMNIST datasets with 20 and 30 clients, and our results demonstrate that FedDefender effectively mitigates such attacks, reducing the attack success rate (ASR) to 10\% without deteriorating the global model performance.
FedDebug: Systematic Debugging for Federated Learning Applications
Jan 09, 2023

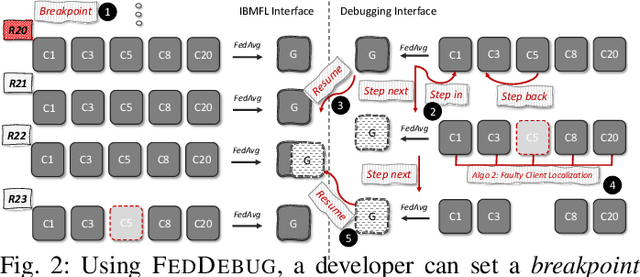

In Federated Learning (FL), clients train a model locally and share it with a central aggregator to build a global model. Impermissibility to access client's data and collaborative training makes FL appealing for applications with data-privacy concerns such as medical imaging. However, these FL characteristics pose unprecedented challenges for debugging. When a global model's performance deteriorates, finding the round and the clients responsible is a major pain point. Developers resort to trial-and-error debugging with subsets of clients, hoping to increase the accuracy or let future FL rounds retune the model, which are time-consuming and costly. We design a systematic fault localization framework, FedDebug, that advances the FL debugging on two novel fronts. First, FedDebug enables interactive debugging of realtime collaborative training in FL by leveraging record and replay techniques to construct a simulation that mirrors live FL. FedDebug's {\em breakpoint} can help inspect an FL state (round, client, and global model) and seamlessly move between rounds and clients' models, enabling a fine-grained step-by-step inspection. Second, FedDebug automatically identifies the client responsible for lowering global model's performance without any testing data and labels--both are essential for existing debugging techniques. FedDebug's strengths come from adapting differential testing in conjunction with neurons activations to determine the precise client deviating from normal behavior. FedDebug achieves 100\% to find a single client and 90.3\% accuracy to find multiple faulty clients. FedDebug's interactive debugging incurs 1.2\% overhead during training, while it localizes a faulty client in only 2.1\% of a round's training time. With FedDebug, we bring effective debugging practices to federated learning, improving the quality and productivity of FL application developers.