 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Hierarchical Neural Options and Abstract World Model
Feb 02, 2026Building agents that can perform new skills by composing existing skills is a long-standing goal of AI agent research. Towards this end, we investigate how to efficiently acquire a sequence of skills, formalized as hierarchical neural options. However, existing model-free hierarchical reinforcement algorithms need a lot of data. We propose a novel method, which we call AgentOWL (Option and World model Learning Agent), that jointly learns -- in a sample efficient way -- an abstract world model (abstracting across both states and time) and a set of hierarchical neural options. We show, on a subset of Object-Centric Atari games, that our method can learn more skills using much less data than baseline methods.
Code World Models for General Game Playing
Oct 06, 2025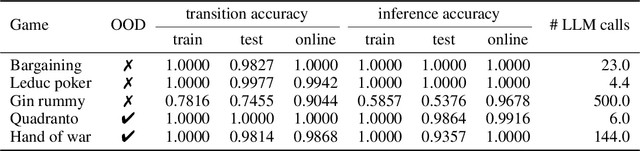

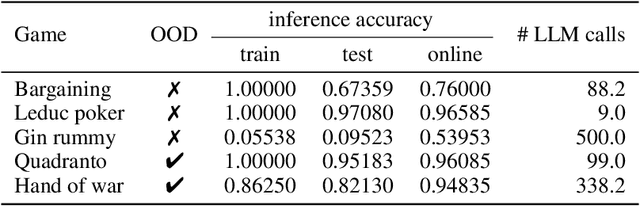
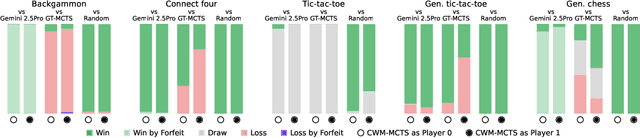
Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
Improving Transformer World Models for Data-Efficient RL
Feb 03, 2025



We present an approach to model-based RL that achieves a new state of the art performance on the challenging Craftax-classic benchmark, an open-world 2D survival game that requires agents to exhibit a wide range of general abilities -- such as strong generalization, deep exploration, and long-term reasoning. With a series of careful design choices aimed at improving sample efficiency, our MBRL algorithm achieves a reward of 67.4% after only 1M environment steps, significantly outperforming DreamerV3, which achieves 53.2%, and, for the first time, exceeds human performance of 65.0%. Our method starts by constructing a SOTA model-free baseline, using a novel policy architecture that combines CNNs and RNNs. We then add three improvements to the standard MBRL setup: (a) "Dyna with warmup", which trains the policy on real and imaginary data, (b) "nearest neighbor tokenizer" on image patches, which improves the scheme to create the transformer world model (TWM) inputs, and (c) "block teacher forcing", which allows the TWM to reason jointly about the future tokens of the next timestep.
Diffusion Model Predictive Control
Oct 07, 2024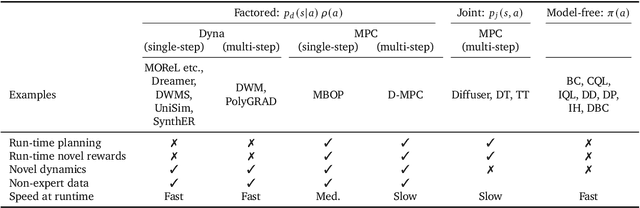
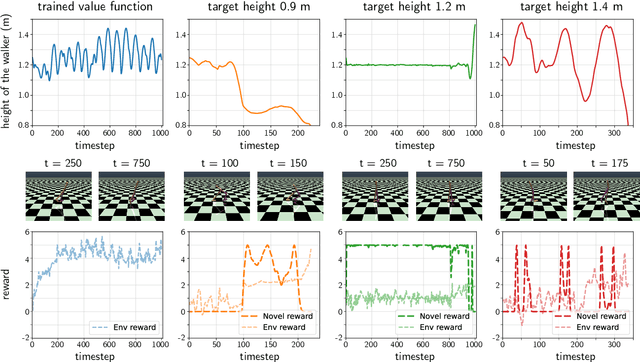
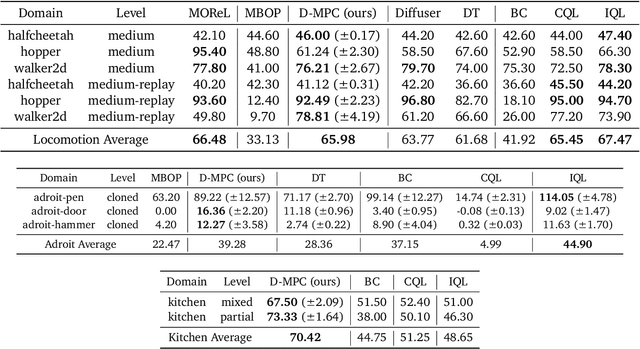
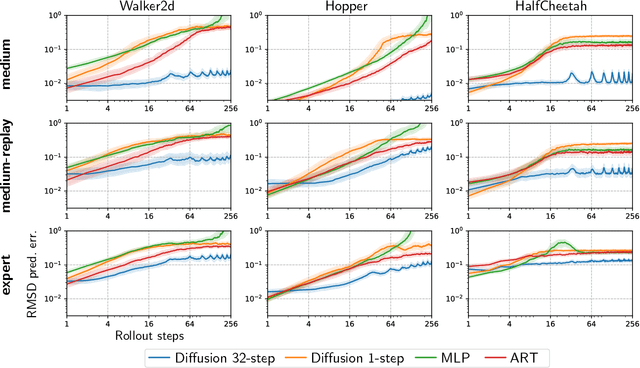
We propose Diffusion Model Predictive Control (D-MPC), a novel MPC approach that learns a multi-step action proposal and a multi-step dynamics model, both using diffusion models, and combines them for use in online MPC. On the popular D4RL benchmark, we show performance that is significantly better than existing model-based offline planning methods using MPC and competitive with state-of-the-art (SOTA) model-based and model-free reinforcement learning methods. We additionally illustrate D-MPC's ability to optimize novel reward functions at run time and adapt to novel dynamics, and highlight its advantages compared to existing diffusion-based planning baselines.
DMC-VB: A Benchmark for Representation Learning for Control with Visual Distractors
Sep 26, 2024



Learning from previously collected data via behavioral cloning or offline reinforcement learning (RL) is a powerful recipe for scaling generalist agents by avoiding the need for expensive online learning. Despite strong generalization in some respects, agents are often remarkably brittle to minor visual variations in control-irrelevant factors such as the background or camera viewpoint. In this paper, we present theDeepMind Control Visual Benchmark (DMC-VB), a dataset collected in the DeepMind Control Suite to evaluate the robustness of offline RL agents for solving continuous control tasks from visual input in the presence of visual distractors. In contrast to prior works, our dataset (a) combines locomotion and navigation tasks of varying difficulties, (b) includes static and dynamic visual variations, (c) considers data generated by policies with different skill levels, (d) systematically returns pairs of state and pixel observation, (e) is an order of magnitude larger, and (f) includes tasks with hidden goals. Accompanying our dataset, we propose three benchmarks to evaluate representation learning methods for pretraining, and carry out experiments on several recently proposed methods. First, we find that pretrained representations do not help policy learning on DMC-VB, and we highlight a large representation gap between policies learned on pixel observations and on states. Second, we demonstrate when expert data is limited, policy learning can benefit from representations pretrained on (a) suboptimal data, and (b) tasks with stochastic hidden goals. Our dataset and benchmark code to train and evaluate agents are available at: https://github.com/google-deepmind/dmc_vision_benchmark.
Learning Cognitive Maps from Transformer Representations for Efficient Planning in Partially Observed Environments
Jan 11, 2024Despite their stellar performance on a wide range of tasks, including in-context tasks only revealed during inference, vanilla transformers and variants trained for next-token predictions (a) do not learn an explicit world model of their environment which can be flexibly queried and (b) cannot be used for planning or navigation. In this paper, we consider partially observed environments (POEs), where an agent receives perceptually aliased observations as it navigates, which makes path planning hard. We introduce a transformer with (multiple) discrete bottleneck(s), TDB, whose latent codes learn a compressed representation of the history of observations and actions. After training a TDB to predict the future observation(s) given the history, we extract interpretable cognitive maps of the environment from its active bottleneck(s) indices. These maps are then paired with an external solver to solve (constrained) path planning problems. First, we show that a TDB trained on POEs (a) retains the near perfect predictive performance of a vanilla transformer or an LSTM while (b) solving shortest path problems exponentially faster. Second, a TDB extracts interpretable representations from text datasets, while reaching higher in-context accuracy than vanilla sequence models. Finally, in new POEs, a TDB (a) reaches near-perfect in-context accuracy, (b) learns accurate in-context cognitive maps (c) solves in-context path planning problems.
Graphical Models with Attention for Context-Specific Independence and an Application to Perceptual Grouping
Dec 06, 2021
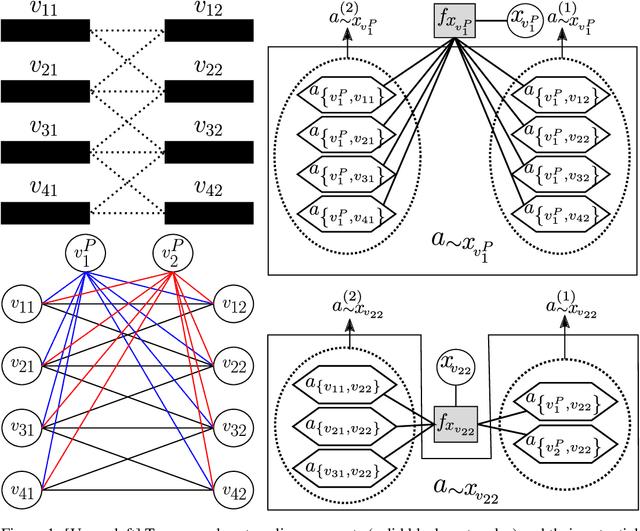

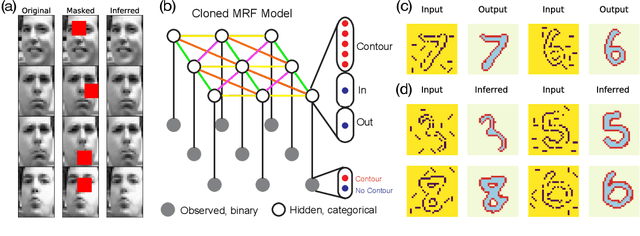
Discrete undirected graphical models, also known as Markov Random Fields (MRFs), can flexibly encode probabilistic interactions of multiple variables, and have enjoyed successful applications to a wide range of problems. However, a well-known yet little studied limitation of discrete MRFs is that they cannot capture context-specific independence (CSI). Existing methods require carefully developed theories and purpose-built inference methods, which limit their applications to only small-scale problems. In this paper, we propose the Markov Attention Model (MAM), a family of discrete MRFs that incorporates an attention mechanism. The attention mechanism allows variables to dynamically attend to some other variables while ignoring the rest, and enables capturing of CSIs in MRFs. A MAM is formulated as an MRF, allowing it to benefit from the rich set of existing MRF inference methods and scale to large models and datasets. To demonstrate MAM's capabilities to capture CSIs at scale, we apply MAMs to capture an important type of CSI that is present in a symbolic approach to recurrent computations in perceptual grouping. Experiments on two recently proposed synthetic perceptual grouping tasks and on realistic images demonstrate the advantages of MAMs in sample-efficiency, interpretability and generalizability when compared with strong recurrent neural network baselines, and validate MAM's capabilities to efficiently capture CSIs at scale.
Query Training: Learning and inference for directed and undirected graphical models
Jun 18, 2020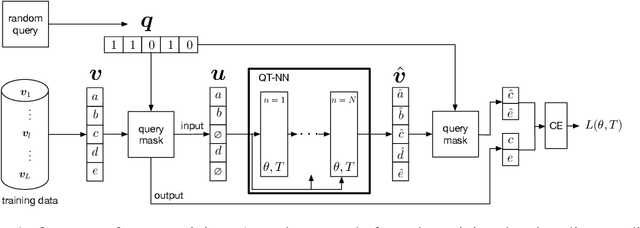
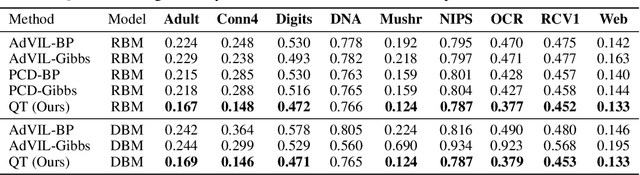
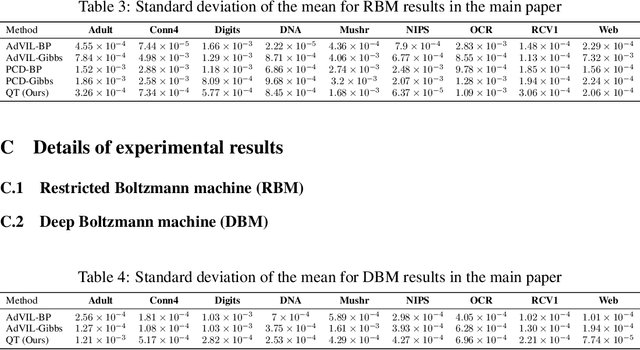
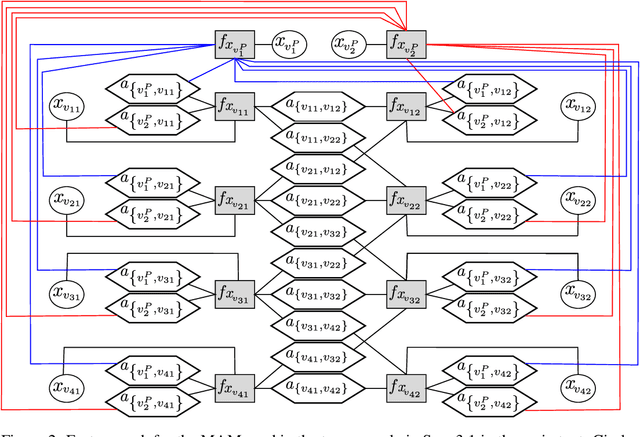
Probabilistic graphical models (PGMs) provide a compact representation of knowledge that can be queried in a flexible way: after learning the parameters of a graphical model, new probabilistic queries can be answered at test time without retraining. However, learning undirected graphical models is notoriously hard due to the intractability of the partition function. For directed models, a popular approach is to use variational autoencoders, but there is no systematic way to choose the encoder architecture given the PGM, and the encoder only amortizes inference for a single probabilistic query (i.e., new queries require separate training). We introduce Query Training (QT), a systematic method to turn any PGM structure (directed or not, with or without hidden variables) into a trainable inference network. This single network can approximate any inference query. We demonstrate experimentally that QT can be used to learn a challenging 8-connected grid Markov random field with hidden variables and that it consistently outperforms the state-of-the-art AdVIL when tested on three undirected models across multiple datasets.
Learning undirected models via query training
Dec 05, 2019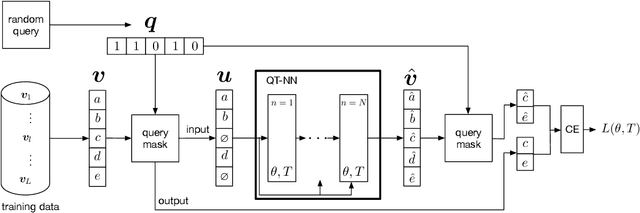

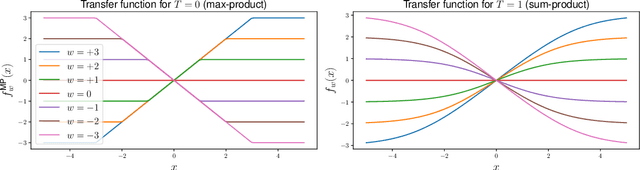
Typical amortized inference in variational autoencoders is specialized for a single probabilistic query. Here we propose an inference network architecture that generalizes to unseen probabilistic queries. Instead of an encoder-decoder pair, we can train a single inference network directly from data, using a cost function that is stochastic not only over samples, but also over queries. We can use this network to perform the same inference tasks as we would in an undirected graphical model with hidden variables, without having to deal with the intractable partition function. The results can be mapped to the learning of an actual undirected model, which is a notoriously hard problem. Our network also marginalizes nuisance variables as required. We show that our approach generalizes to unseen probabilistic queries on also unseen test data, providing fast and flexible inference. Experiments show that this approach outperforms or matches PCD and AdVIL on 9 benchmark datasets.
Learning higher-order sequential structure with cloned HMMs
May 15, 2019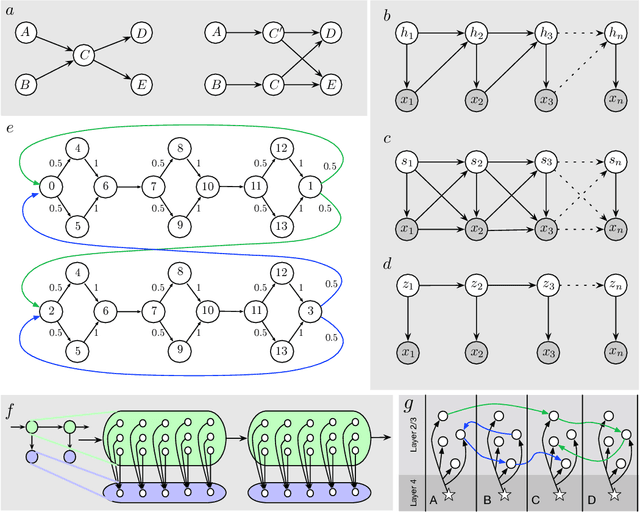



Variable order sequence modeling is an important problem in artificial and natural intelligence. While overcomplete Hidden Markov Models (HMMs), in theory, have the capacity to represent long-term temporal structure, they often fail to learn and converge to local minima. We show that by constraining HMMs with a simple sparsity structure inspired by biology, we can make it learn variable order sequences efficiently. We call this model cloned HMM (CHMM) because the sparsity structure enforces that many hidden states map deterministically to the same emission state. CHMMs with over 1 billion parameters can be efficiently trained on GPUs without being severely affected by the credit diffusion problem of standard HMMs. Unlike n-grams and sequence memoizers, CHMMs can model temporal dependencies at arbitrarily long distances and recognize contexts with 'holes' in them. Compared to Recurrent Neural Networks and their Long Short-Term Memory extensions (LSTMs), CHMMs are generative models that can natively deal with uncertainty. Moreover, CHMMs return a higher-order graph that represents the temporal structure of the data which can be useful for community detection, and for building hierarchical models. Our experiments show that CHMMs can beat n-grams, sequence memoizers, and LSTMs on character-level language modeling tasks. CHMMs can be a viable alternative to these methods in some tasks that require variable order sequence modeling and the handling of uncertainty.