 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushWorld: A benchmark for manipulation planning with tools and movable obstacles
Feb 01, 2023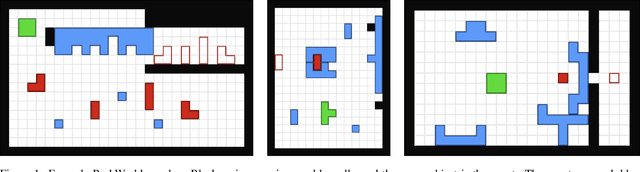

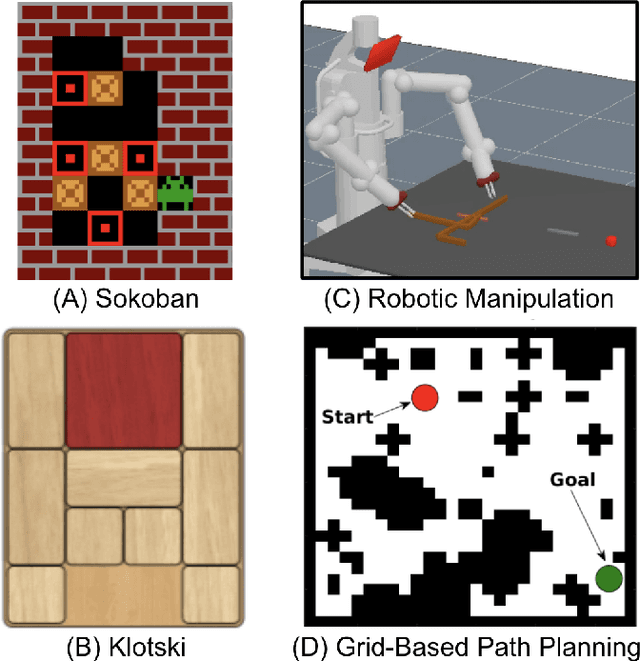
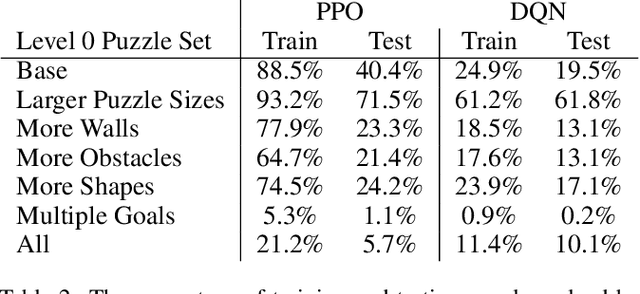
While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for modern algorithms. To date, few algorithms have been evaluated on physical tasks that involve manipulating objects when movable obstacles are present and when tools must be used to perform the manipulation. To promote research on such tasks, we introduce PushWorld, an environment with simplistic physics that requires manipulation planning with both movable obstacles and tools. We provide a benchmark of more than 200 PushWorld puzzles in PDDL and in an OpenAI Gym environment. We evaluate state-of-the-art classical planning and reinforcement learning algorithms on this benchmark, and we find that these baseline results are below human-level performance. We then provide a new classical planning heuristic that solves the most puzzles among the baselines, and although it is 40 times faster than the best baseline planner, it remains below human-level performance.
Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics
Aug 17, 2017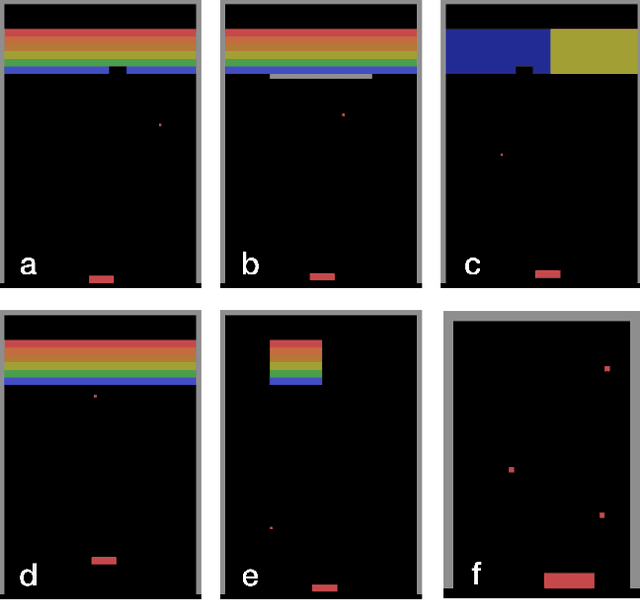

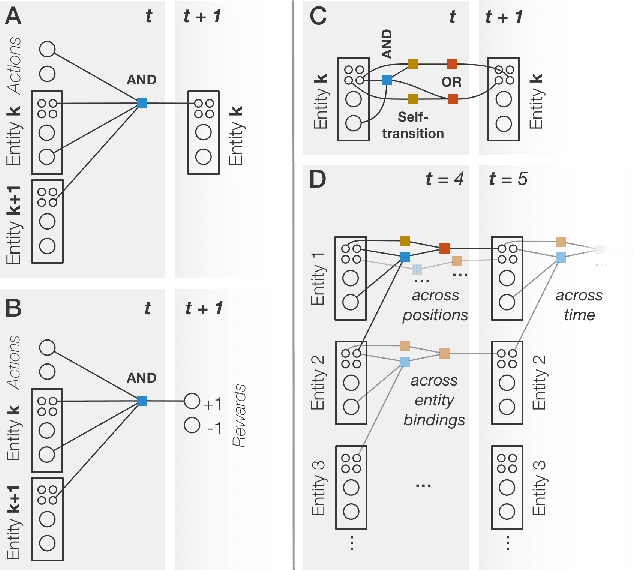
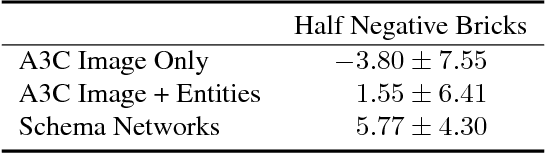
The recent adaptation of deep neural network-based methods to reinforcement learning and planning domains has yielded remarkable progress on individual tasks. Nonetheless, progress on task-to-task transfer remains limited. In pursuit of efficient and robust generalization, we introduce the Schema Network, an object-oriented generative physics simulator capable of disentangling multiple causes of events and reasoning backward through causes to achieve goals. The richly structured architecture of the Schema Network can learn the dynamics of an environment directly from data. We compare Schema Networks with Asynchronous Advantage Actor-Critic and Progressive Networks on a suite of Breakout variations, reporting results on training efficiency and zero-shot generalization, consistently demonstrating faster, more robust learning and better transfer. We argue that generalizing from limited data and learning causal relationships are essential abilities on the path toward generally intelligent systems.
Generative Shape Models: Joint Text Recognition and Segmentation with Very Little Training Data
Nov 09, 2016
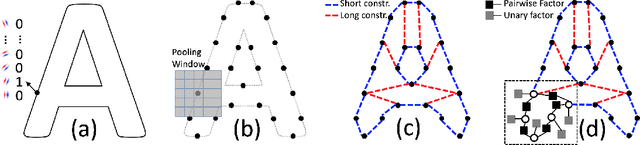
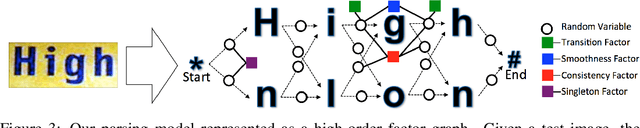

We demonstrate that a generative model for object shapes can achieve state of the art results on challenging scene text recognition tasks, and with orders of magnitude fewer training images than required for competing discriminative methods. In addition to transcribing text from challenging images, our method performs fine-grained instance segmentation of characters. We show that our model is more robust to both affine transformations and non-affine deformations compared to previous approaches.