 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical compositional feature learning
Oct 26, 2017



We introduce the hierarchical compositional network (HCN), a directed generative model able to discover and disentangle, without supervision, the building blocks of a set of binary images. The building blocks are binary features defined hierarchically as a composition of some of the features in the layer immediately below, arranged in a particular manner. At a high level, HCN is similar to a sigmoid belief network with pooling. Inference and learning in HCN are very challenging and existing variational approximations do not work satisfactorily. A main contribution of this work is to show that both can be addressed using max-product message passing (MPMP) with a particular schedule (no EM required). Also, using MPMP as an inference engine for HCN makes new tasks simple: adding supervision information, classifying images, or performing inpainting all correspond to clamping some variables of the model to their known values and running MPMP on the rest. When used for classification, fast inference with HCN has exactly the same functional form as a convolutional neural network (CNN) with linear activations and binary weights. However, HCN's features are qualitatively very different.
Teaching Compositionality to CNNs
Jun 14, 2017
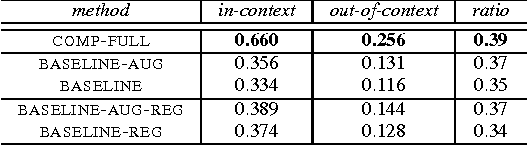
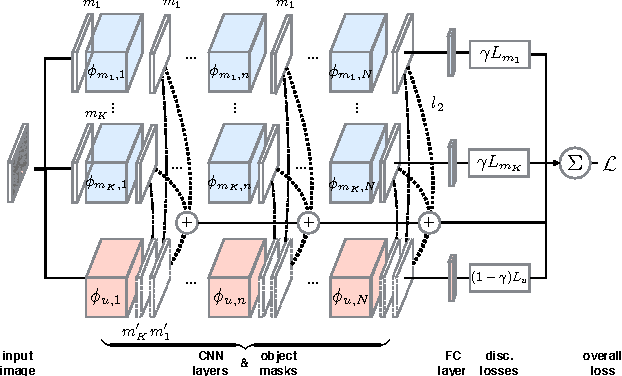
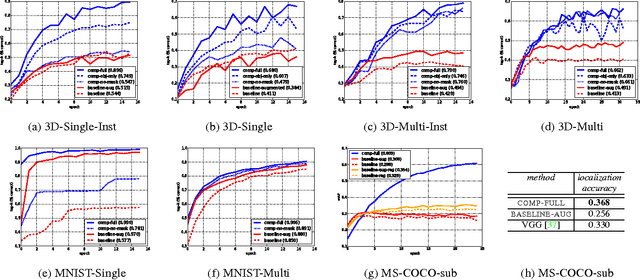
Convolutional neural networks (CNNs) have shown great success in computer vision, approaching human-level performance when trained for specific tasks via application-specific loss functions. In this paper, we propose a method for augmenting and training CNNs so that their learned features are compositional. It encourages networks to form representations that disentangle objects from their surroundings and from each other, thereby promoting better generalization. Our method is agnostic to the specific details of the underlying CNN to which it is applied and can in principle be used with any CNN. As we show in our experiments, the learned representations lead to feature activations that are more localized and improve performance over non-compositional baselines in object recognition tasks.
Generative Shape Models: Joint Text Recognition and Segmentation with Very Little Training Data
Nov 09, 2016
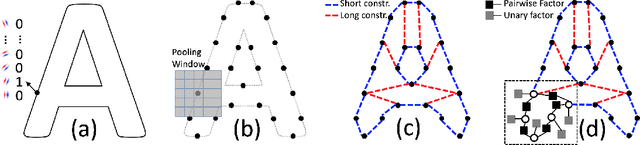
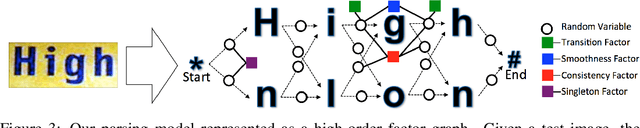

We demonstrate that a generative model for object shapes can achieve state of the art results on challenging scene text recognition tasks, and with orders of magnitude fewer training images than required for competing discriminative methods. In addition to transcribing text from challenging images, our method performs fine-grained instance segmentation of characters. We show that our model is more robust to both affine transformations and non-affine deformations compared to previous approaches.
A backward pass through a CNN using a generative model of its activations
Nov 08, 2016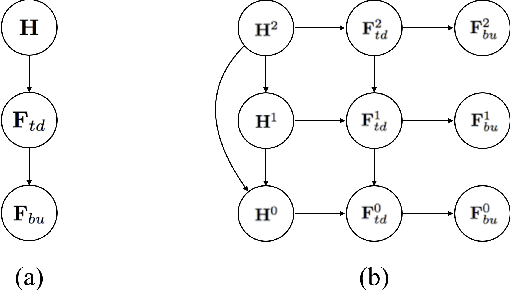



Neural networks have shown to be a practical way of building a very complex mapping between a pre-specified input space and output space. For example, a convolutional neural network (CNN) mapping an image into one of a thousand object labels is approaching human performance in this particular task. However the mapping (neural network) does not automatically lend itself to other forms of queries, for example, to detect/reconstruct object instances, to enforce top-down signal on ambiguous inputs, or to recover object instances from occlusion. One way to address these queries is a backward pass through the network that fuses top-down and bottom-up information. In this paper, we show a way of building such a backward pass by defining a generative model of the neural network's activations. Approximate inference of the model would naturally take the form of a backward pass through the CNN layers, and it addresses the aforementioned queries in a unified framework.