 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCHiP: Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks
Apr 09, 2024



Large Language Models (LLMs) have been successful at generating robot policy code, but so far these results have been limited to high-level tasks that do not require precise movement. It is an open question how well such approaches work for tasks that require reasoning over contact forces and working within tight success tolerances. We find that, with the right action space, LLMs are capable of successfully generating policies for a variety of contact-rich and high-precision manipulation tasks, even under noisy conditions, such as perceptual errors or grasping inaccuracies. Specifically, we reparameterize the action space to include compliance with constraints on the interaction forces and stiffnesses involved in reaching a target pose. We validate this approach on subtasks derived from the Functional Manipulation Benchmark (FMB) and NIST Task Board Benchmarks. Exposing this action space alongside methods for estimating object poses improves policy generation with an LLM by greater than 3x and 4x when compared to non-compliant action spaces
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024



Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
Teaching Compositionality to CNNs
Jun 14, 2017
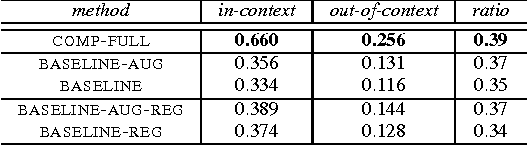
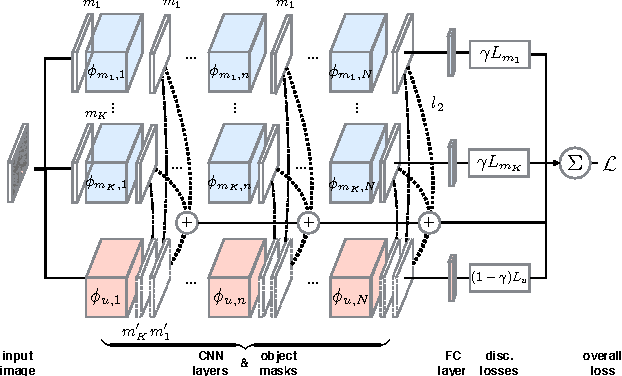
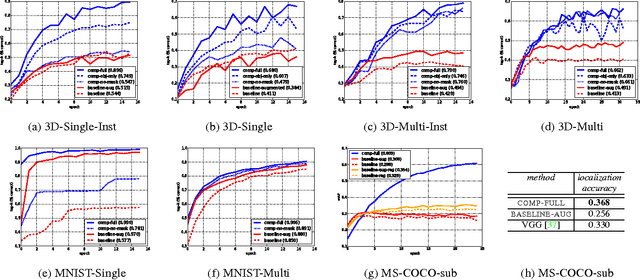
Convolutional neural networks (CNNs) have shown great success in computer vision, approaching human-level performance when trained for specific tasks via application-specific loss functions. In this paper, we propose a method for augmenting and training CNNs so that their learned features are compositional. It encourages networks to form representations that disentangle objects from their surroundings and from each other, thereby promoting better generalization. Our method is agnostic to the specific details of the underlying CNN to which it is applied and can in principle be used with any CNN. As we show in our experiments, the learned representations lead to feature activations that are more localized and improve performance over non-compositional baselines in object recognition tasks.
3D Object Class Detection in the Wild
Mar 17, 2015
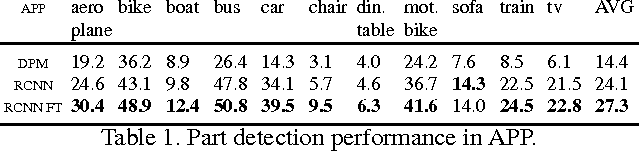


Object class detection has been a synonym for 2D bounding box localization for the longest time, fueled by the success of powerful statistical learning techniques, combined with robust image representations. Only recently, there has been a growing interest in revisiting the promise of computer vision from the early days: to precisely delineate the contents of a visual scene, object by object, in 3D. In this paper, we draw from recent advances in object detection and 2D-3D object lifting in order to design an object class detector that is particularly tailored towards 3D object class detection. Our 3D object class detection method consists of several stages gradually enriching the object detection output with object viewpoint, keypoints and 3D shape estimates. Following careful design, in each stage it constantly improves the performance and achieves state-ofthe-art performance in simultaneous 2D bounding box and viewpoint estimation on the challenging Pascal3D+ dataset.
Towards Scene Understanding with Detailed 3D Object Representations
Nov 18, 2014
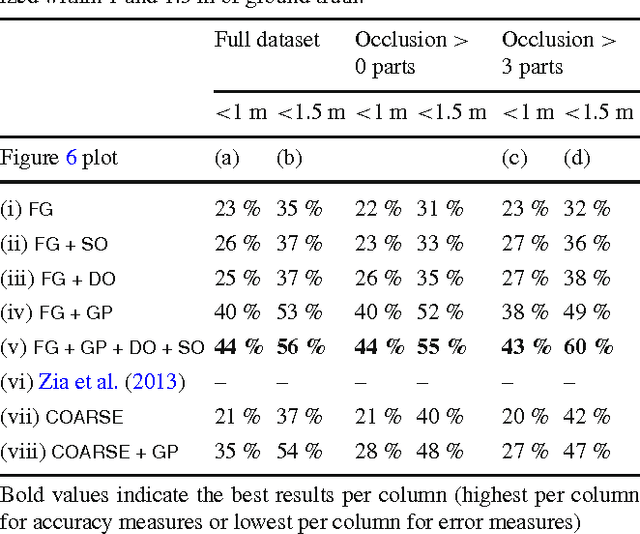


Current approaches to semantic image and scene understanding typically employ rather simple object representations such as 2D or 3D bounding boxes. While such coarse models are robust and allow for reliable object detection, they discard much of the information about objects' 3D shape and pose, and thus do not lend themselves well to higher-level reasoning. Here, we propose to base scene understanding on a high-resolution object representation. An object class - in our case cars - is modeled as a deformable 3D wireframe, which enables fine-grained modeling at the level of individual vertices and faces. We augment that model to explicitly include vertex-level occlusion, and embed all instances in a common coordinate frame, in order to infer and exploit object-object interactions. Specifically, from a single view we jointly estimate the shapes and poses of multiple objects in a common 3D frame. A ground plane in that frame is estimated by consensus among different objects, which significantly stabilizes monocular 3D pose estimation. The fine-grained model, in conjunction with the explicit 3D scene model, further allows one to infer part-level occlusions between the modeled objects, as well as occlusions by other, unmodeled scene elements. To demonstrate the benefits of such detailed object class models in the context of scene understanding we systematically evaluate our approach on the challenging KITTI street scene dataset. The experiments show that the model's ability to utilize image evidence at the level of individual parts improves monocular 3D pose estimation w.r.t. both location and (continuous) viewpoint.
Multi-View Priors for Learning Detectors from Sparse Viewpoint Data
Feb 16, 2014
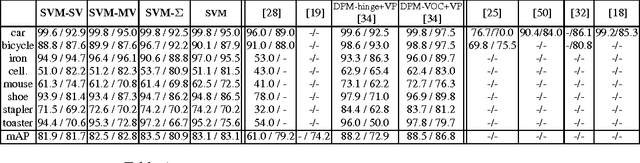
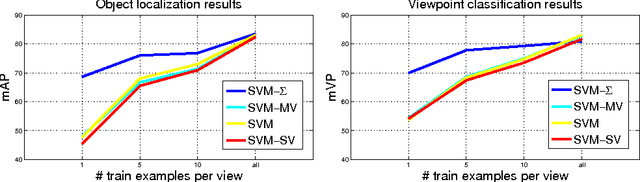
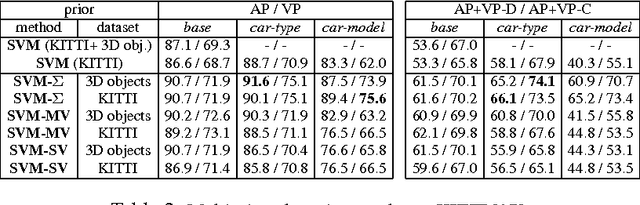
While the majority of today's object class models provide only 2D bounding boxes, far richer output hypotheses are desirable including viewpoint, fine-grained category, and 3D geometry estimate. However, models trained to provide richer output require larger amounts of training data, preferably well covering the relevant aspects such as viewpoint and fine-grained categories. In this paper, we address this issue from the perspective of transfer learning, and design an object class model that explicitly leverages correlations between visual features. Specifically, our model represents prior distributions over permissible multi-view detectors in a parametric way -- the priors are learned once from training data of a source object class, and can later be used to facilitate the learning of a detector for a target class. As we show in our experiments, this transfer is not only beneficial for detectors based on basic-level category representations, but also enables the robust learning of detectors that represent classes at finer levels of granularity, where training data is typically even scarcer and more unbalanced. As a result, we report largely improved performance in simultaneous 2D object localization and viewpoint estimation on a recent dataset of challenging street scenes.