 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Holding Back Convnets for Detection?
Aug 18, 2015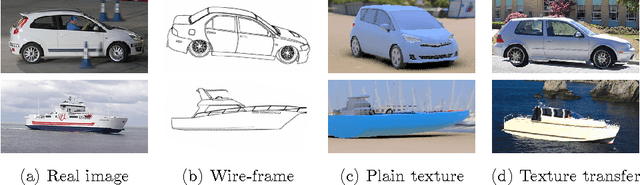
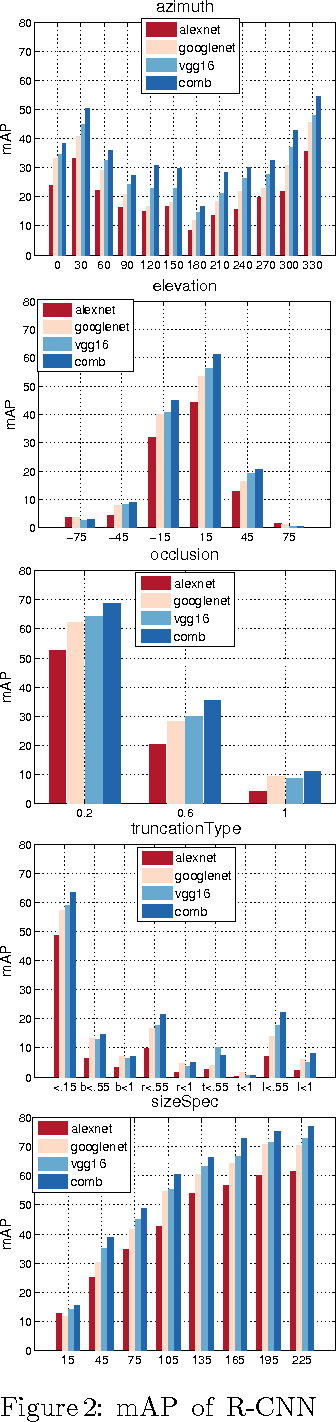
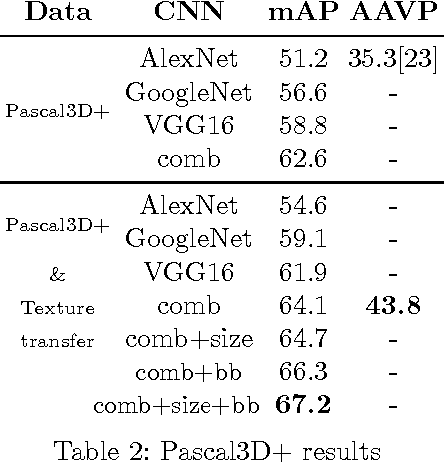
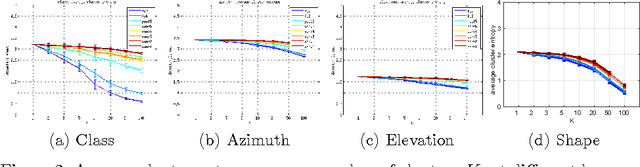
Convolutional neural networks have recently shown excellent results in general object detection and many other tasks. Albeit very effective, they involve many user-defined design choices. In this paper we want to better understand these choices by inspecting two key aspects "what did the network learn?", and "what can the network learn?". We exploit new annotations (Pascal3D+), to enable a new empirical analysis of the R-CNN detector. Despite common belief, our results indicate that existing state-of-the-art convnet architectures are not invariant to various appearance factors. In fact, all considered networks have similar weak points which cannot be mitigated by simply increasing the training data (architectural changes are needed). We show that overall performance can improve when using image renderings for data augmentation. We report the best known results on the Pascal3D+ detection and view-point estimation tasks.
3D Object Class Detection in the Wild
Mar 17, 2015
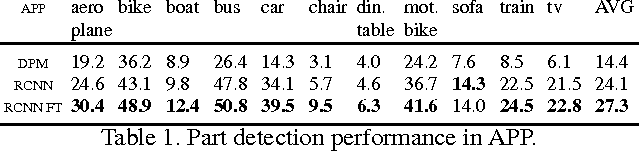


Object class detection has been a synonym for 2D bounding box localization for the longest time, fueled by the success of powerful statistical learning techniques, combined with robust image representations. Only recently, there has been a growing interest in revisiting the promise of computer vision from the early days: to precisely delineate the contents of a visual scene, object by object, in 3D. In this paper, we draw from recent advances in object detection and 2D-3D object lifting in order to design an object class detector that is particularly tailored towards 3D object class detection. Our 3D object class detection method consists of several stages gradually enriching the object detection output with object viewpoint, keypoints and 3D shape estimates. Following careful design, in each stage it constantly improves the performance and achieves state-ofthe-art performance in simultaneous 2D bounding box and viewpoint estimation on the challenging Pascal3D+ dataset.
Multi-View Priors for Learning Detectors from Sparse Viewpoint Data
Feb 16, 2014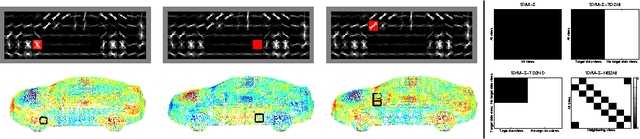
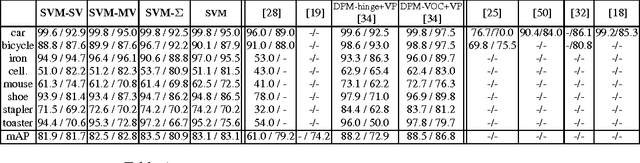
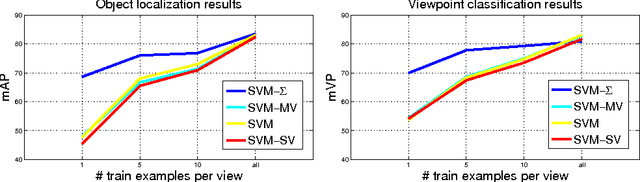
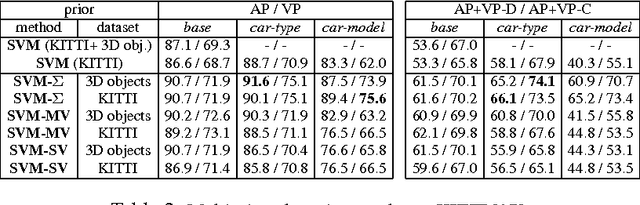
While the majority of today's object class models provide only 2D bounding boxes, far richer output hypotheses are desirable including viewpoint, fine-grained category, and 3D geometry estimate. However, models trained to provide richer output require larger amounts of training data, preferably well covering the relevant aspects such as viewpoint and fine-grained categories. In this paper, we address this issue from the perspective of transfer learning, and design an object class model that explicitly leverages correlations between visual features. Specifically, our model represents prior distributions over permissible multi-view detectors in a parametric way -- the priors are learned once from training data of a source object class, and can later be used to facilitate the learning of a detector for a target class. As we show in our experiments, this transfer is not only beneficial for detectors based on basic-level category representations, but also enables the robust learning of detectors that represent classes at finer levels of granularity, where training data is typically even scarcer and more unbalanced. As a result, we report largely improved performance in simultaneous 2D object localization and viewpoint estimation on a recent dataset of challenging street scenes.