 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDobLIX: A Dual-Objective Learned Index for Log-Structured Merge Trees
Feb 07, 2025



In this paper, we introduce DobLIX, a dual-objective learned index specifically designed for Log-Structured Merge(LSM) tree-based key-value stores. Although traditional learned indexes focus exclusively on optimizing index lookups, they often overlook the impact of data access from storage, resulting in performance bottlenecks. DobLIX addresses this by incorporating a second objective, data access optimization, into the learned index training process. This dual-objective approach ensures that both index lookup efficiency and data access costs are minimized, leading to significant improvements in read performance while maintaining write efficiency in real-world LSM-tree systems. Additionally, DobLIX features a reinforcement learning agent that dynamically tunes the system parameters, allowing it to adapt to varying workloads in real-time. Experimental results using real-world datasets demonstrate that DobLIX reduces indexing overhead and improves throughput by 1.19 to 2.21 times compared to state-of-the-art methods within RocksDB, a widely used LSM-tree-based storage engine.
UpLIF: An Updatable Self-Tuning Learned Index Framework
Aug 07, 2024The emergence of learned indexes has caused a paradigm shift in our perception of indexing by considering indexes as predictive models that estimate keys' positions within a data set, resulting in notable improvements in key search efficiency and index size reduction; however, a significant challenge inherent in learned index modeling is its constrained support for update operations, necessitated by the requirement for a fixed distribution of records. Previous studies have proposed various approaches to address this issue with the drawback of high overhead due to multiple model retraining. In this paper, we present UpLIF, an adaptive self-tuning learned index that adjusts the model to accommodate incoming updates, predicts the distribution of updates for performance improvement, and optimizes its index structure using reinforcement learning. We also introduce the concept of balanced model adjustment, which determines the model's inherent properties (i.e. bias and variance), enabling the integration of these factors into the existing index model without the need for retraining with new data. Our comprehensive experiments show that the system surpasses state-of-the-art indexing solutions (both traditional and ML-based), achieving an increase in throughput of up to 3.12 times with 1000 times less memory usage.
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores
Jul 26, 2024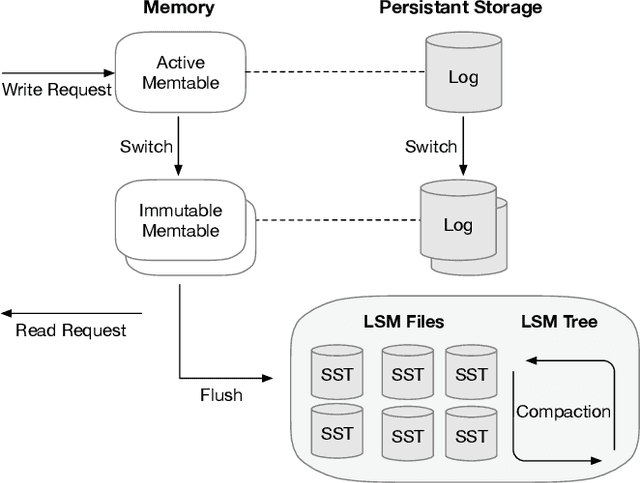
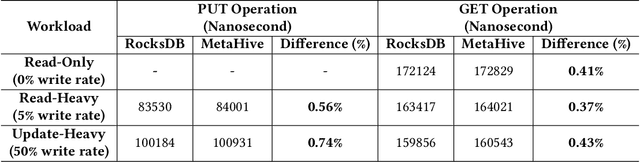
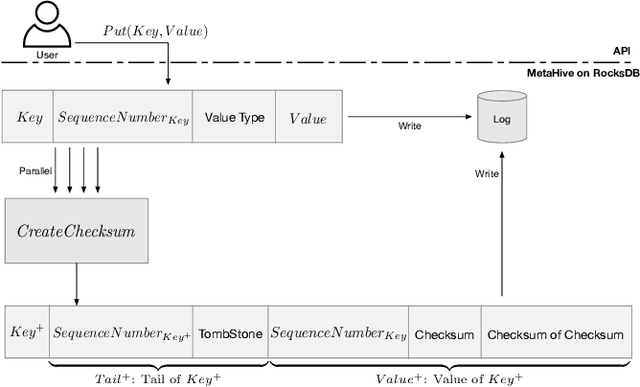
Cloud key-value (KV) stores provide businesses with a cost-effective and adaptive alternative to traditional on-premise data management solutions. KV stores frequently consist of heterogeneous clusters, characterized by varying hardware specifications of the deployment nodes, with each node potentially running a distinct version of the KV store software. This heterogeneity is accompanied by the diverse metadata that they need to manage. In this study, we introduce MetaHive, a cache-optimized approach to managing metadata in heterogeneous KV store clusters. MetaHive disaggregates the original data from its associated metadata to promote independence between them, while maintaining their interconnection during usage. This makes the metadata opaque from the downstream processes and the other KV stores in the cluster. MetaHive also ensures that the KV and metadata entries are stored in the vicinity of each other in memory and storage. This allows MetaHive to optimally utilize the caching mechanism without extra storage read overhead for metadata retrieval. We deploy MetaHive to ensure data integrity in RocksDB and demonstrate its rapid data validation with minimal effect on performance.
* Cloud Databases
Unlabeled Out-Of-Domain Data Improves Generalization
Sep 29, 2023We propose a novel framework for incorporating unlabeled data into semi-supervised classification problems, where scenarios involving the minimization of either i) adversarially robust or ii) non-robust loss functions have been considered. Notably, we allow the unlabeled samples to deviate slightly (in total variation sense) from the in-domain distribution. The core idea behind our framework is to combine Distributionally Robust Optimization (DRO) with self-supervised training. As a result, we also leverage efficient polynomial-time algorithms for the training stage. From a theoretical standpoint, we apply our framework on the classification problem of a mixture of two Gaussians in $\mathbb{R}^d$, where in addition to the $m$ independent and labeled samples from the true distribution, a set of $n$ (usually with $n\gg m$) out of domain and unlabeled samples are gievn as well. Using only the labeled data, it is known that the generalization error can be bounded by $\propto\left(d/m\right)^{1/2}$. However, using our method on both isotropic and non-isotropic Gaussian mixture models, one can derive a new set of analytically explicit and non-asymptotic bounds which show substantial improvement on the generalization error compared ERM. Our results underscore two significant insights: 1) out-of-domain samples, even when unlabeled, can be harnessed to narrow the generalization gap, provided that the true data distribution adheres to a form of the "cluster assumption", and 2) the semi-supervised learning paradigm can be regarded as a special case of our framework when there are no distributional shifts. We validate our claims through experiments conducted on a variety of synthetic and real-world datasets.
On sampling from data with duplicate records
Aug 24, 2020
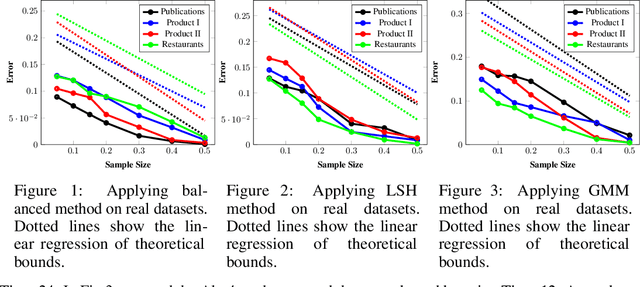
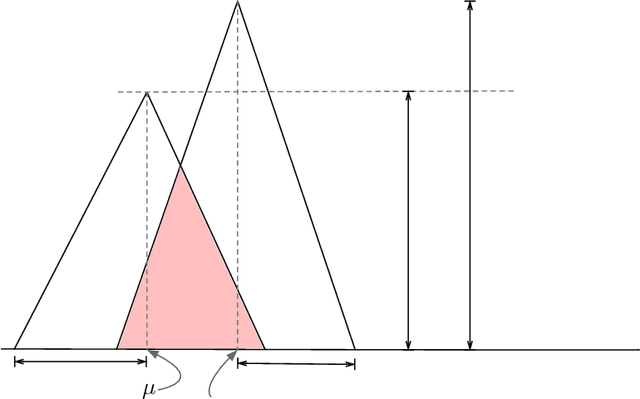
Data deduplication is the task of detecting records in a database that correspond to the same real-world entity. Our goal is to develop a procedure that samples uniformly from the set of entities present in the database in the presence of duplicates. We accomplish this by a two-stage process. In the first step, we estimate the frequencies of all the entities in the database. In the second step, we use rejection sampling to obtain a (approximately) uniform sample from the set of entities. However, efficiently estimating the frequency of all the entities is a non-trivial task and not attainable in the general case. Hence, we consider various natural properties of the data under which such frequency estimation (and consequently uniform sampling) is possible. Under each of those assumptions, we provide sampling algorithms and give proofs of the complexity (both statistical and computational) of our approach. We complement our study by conducting extensive experiments on both real and synthetic datasets.
Record fusion: A learning approach
Jun 18, 2020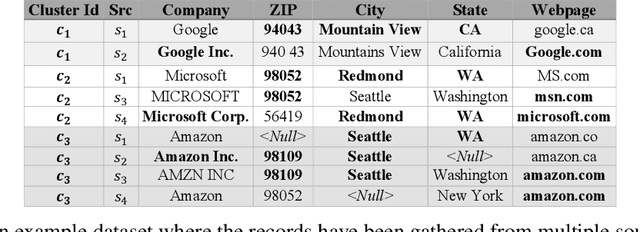
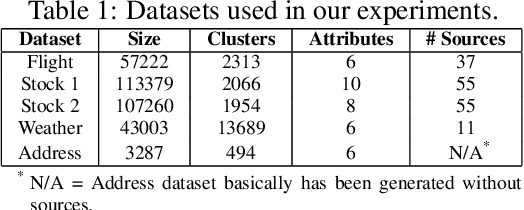
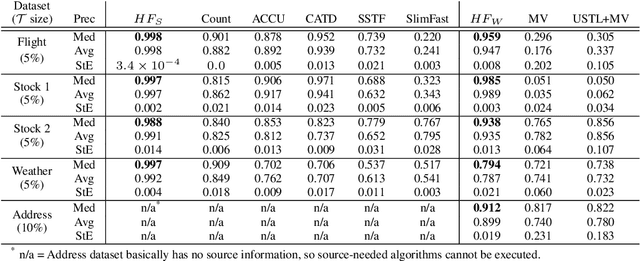
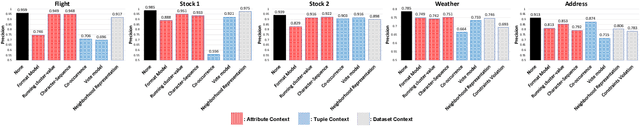
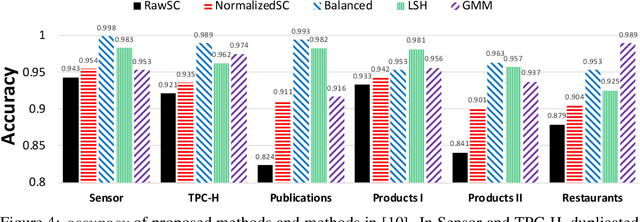
Record fusion is the task of aggregating multiple records that correspond to the same real-world entity in a database. We can view record fusion as a machine learning problem where the goal is to predict the "correct" value for each attribute for each entity. Given a database, we use a combination of attribute-level, recordlevel, and database-level signals to construct a feature vector for each cell (or (row, col)) of that database. We use this feature vector alongwith the ground-truth information to learn a classifier for each of the attributes of the database. Our learning algorithm uses a novel stagewise additive model. At each stage, we construct a new feature vector by combining a part of the original feature vector with features computed by the predictions from the previous stage. We then learn a softmax classifier over the new feature space. This greedy stagewise approach can be viewed as a deep model where at each stage, we are adding more complicated non-linear transformations of the original feature vector. We show that our approach fuses records with an average precision of ~98% when source information of records is available, and ~94% without source information across a diverse array of real-world datasets. We compare our approach to a comprehensive collection of data fusion and entity consolidation methods considered in the literature. We show that our approach can achieve an average precision improvement of ~20%/~45% with/without source information respectively.
Approximate Inference in Structured Instances with Noisy Categorical Observations
Jul 06, 2019



We study the problem of recovering the latent ground truth labeling of a structured instance with categorical random variables in the presence of noisy observations. We present a new approximate algorithm for graphs with categorical variables that achieves low Hamming error in the presence of noisy vertex and edge observations. Our main result shows a logarithmic dependency of the Hamming error to the number of categories of the random variables. Our approach draws connections to correlation clustering with a fixed number of clusters. Our results generalize the works of Globerson et al. (2015) and Foster et al. (2018), who study the hardness of structured prediction under binary labels, to the case of categorical labels.