 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\texttt{Range-Arithmetic}: Verifiable Deep Learning Inference on an Untrusted Party
May 23, 2025Verifiable computing (VC) has gained prominence in decentralized machine learning systems, where resource-intensive tasks like deep neural network (DNN) inference are offloaded to external participants due to blockchain limitations. This creates a need to verify the correctness of outsourced computations without re-execution. We propose \texttt{Range-Arithmetic}, a novel framework for efficient and verifiable DNN inference that transforms non-arithmetic operations, such as rounding after fixed-point matrix multiplication and ReLU, into arithmetic steps verifiable using sum-check protocols and concatenated range proofs. Our approach avoids the complexity of Boolean encoding, high-degree polynomials, and large lookup tables while remaining compatible with finite-field-based proof systems. Experimental results show that our method not only matches the performance of existing approaches, but also reduces the computational cost of verifying the results, the computational effort required from the untrusted party performing the DNN inference, and the communication overhead between the two sides.
Gradual Domain Adaptation via Manifold-Constrained Distributionally Robust Optimization
Oct 17, 2024

The aim of this paper is to address the challenge of gradual domain adaptation within a class of manifold-constrained data distributions. In particular, we consider a sequence of $T\ge2$ data distributions $P_1,\ldots,P_T$ undergoing a gradual shift, where each pair of consecutive measures $P_i,P_{i+1}$ are close to each other in Wasserstein distance. We have a supervised dataset of size $n$ sampled from $P_0$, while for the subsequent distributions in the sequence, only unlabeled i.i.d. samples are available. Moreover, we assume that all distributions exhibit a known favorable attribute, such as (but not limited to) having intra-class soft/hard margins. In this context, we propose a methodology rooted in Distributionally Robust Optimization (DRO) with an adaptive Wasserstein radius. We theoretically show that this method guarantees the classification error across all $P_i$s can be suitably bounded. Our bounds rely on a newly introduced {\it {compatibility}} measure, which fully characterizes the error propagation dynamics along the sequence. Specifically, for inadequately constrained distributions, the error can exponentially escalate as we progress through the gradual shifts. Conversely, for appropriately constrained distributions, the error can be demonstrated to be linear or even entirely eradicated. We have substantiated our theoretical findings through several experimental results.
Coordinated Deep Neural Networks: A Versatile Edge Offloading Algorithm
Jan 01, 2024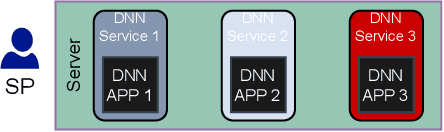
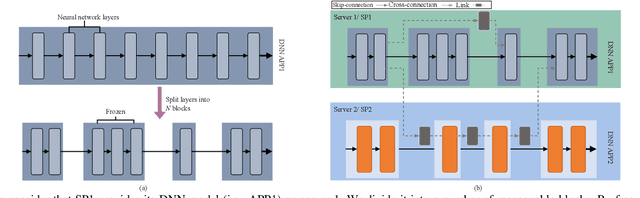
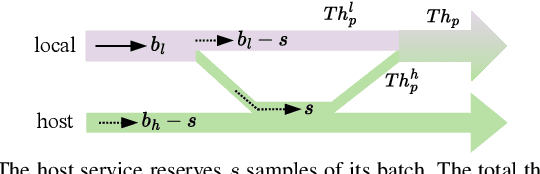
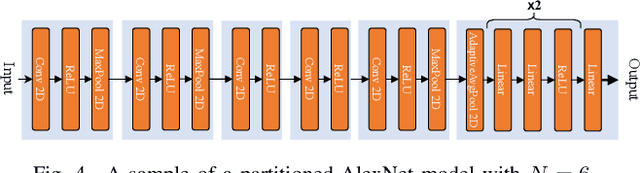
As artificial intelligence (AI) applications continue to expand, there is a growing need for deep neural network (DNN) models. Although DNN models deployed at the edge are promising to provide AI as a service with low latency, their cooperation is yet to be explored. In this paper, we consider the DNN service providers share their computing resources as well as their models' parameters and allow other DNNs to offload their computations without mirroring. We propose a novel algorithm called coordinated DNNs on edge (\textbf{CoDE}) that facilitates coordination among DNN services by creating multi-task DNNs out of individual models. CoDE aims to find the optimal path that results in the lowest possible cost, where the cost reflects the inference delay, model accuracy, and local computation workload. With CoDE, DNN models can make new paths for inference by using their own or other models' parameters. We then evaluate the performance of CoDE through numerical experiments. The results demonstrate a $75\%$ reduction in the local service computation workload while degrading the accuracy by only $2\%$ and having the same inference time in a balanced load condition. Under heavy load, CoDE can further decrease the inference time by $30\%$ while the accuracy is reduced by only $4\%$.
Unlabeled Out-Of-Domain Data Improves Generalization
Sep 29, 2023We propose a novel framework for incorporating unlabeled data into semi-supervised classification problems, where scenarios involving the minimization of either i) adversarially robust or ii) non-robust loss functions have been considered. Notably, we allow the unlabeled samples to deviate slightly (in total variation sense) from the in-domain distribution. The core idea behind our framework is to combine Distributionally Robust Optimization (DRO) with self-supervised training. As a result, we also leverage efficient polynomial-time algorithms for the training stage. From a theoretical standpoint, we apply our framework on the classification problem of a mixture of two Gaussians in $\mathbb{R}^d$, where in addition to the $m$ independent and labeled samples from the true distribution, a set of $n$ (usually with $n\gg m$) out of domain and unlabeled samples are gievn as well. Using only the labeled data, it is known that the generalization error can be bounded by $\propto\left(d/m\right)^{1/2}$. However, using our method on both isotropic and non-isotropic Gaussian mixture models, one can derive a new set of analytically explicit and non-asymptotic bounds which show substantial improvement on the generalization error compared ERM. Our results underscore two significant insights: 1) out-of-domain samples, even when unlabeled, can be harnessed to narrow the generalization gap, provided that the true data distribution adheres to a form of the "cluster assumption", and 2) the semi-supervised learning paradigm can be regarded as a special case of our framework when there are no distributional shifts. We validate our claims through experiments conducted on a variety of synthetic and real-world datasets.
Sample Complexity Bounds for Learning High-dimensional Simplices in Noisy Regimes
Sep 09, 2022In this paper, we propose a sample complexity bound for learning a simplex from noisy samples. A dataset of size $n$ is given which includes i.i.d. samples drawn from a uniform distribution over an unknown arbitrary simplex in $\mathbb{R}^K$, where samples are assumed to be corrupted by an additive Gaussian noise of an arbitrary magnitude. We propose a strategy which outputs a simplex having, with high probability, a total variation distance of $\epsilon + O\left(\mathrm{SNR}^{-1}\right)$ from the true simplex, for any $\epsilon>0$. We prove that to arrive this close to the true simplex, it is sufficient to have $n\ge\tilde{O}\left(K^2/\epsilon^2\right)$ samples. Here, SNR stands for the signal-to-noise ratio which can be viewed as the ratio of the diameter of the simplex to the standard deviation of the noise. Our proofs are based on recent advancements in sample compression techniques, which have already shown promises in deriving tight bounds for density estimation in high-dimensional Gaussian mixture models.
On Statistical Learning of Simplices: Unmixing Problem Revisited
Oct 18, 2018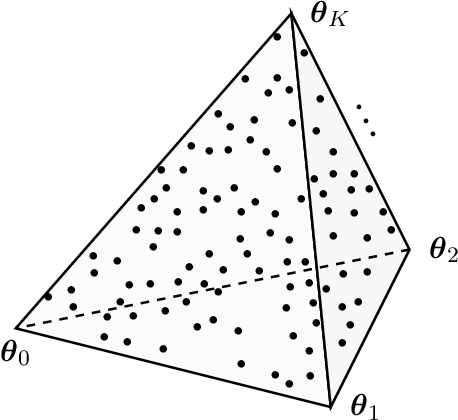
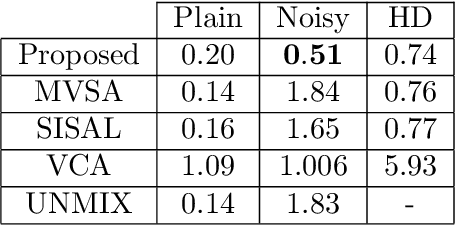
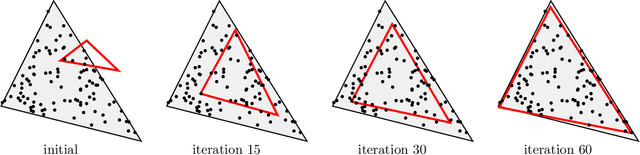
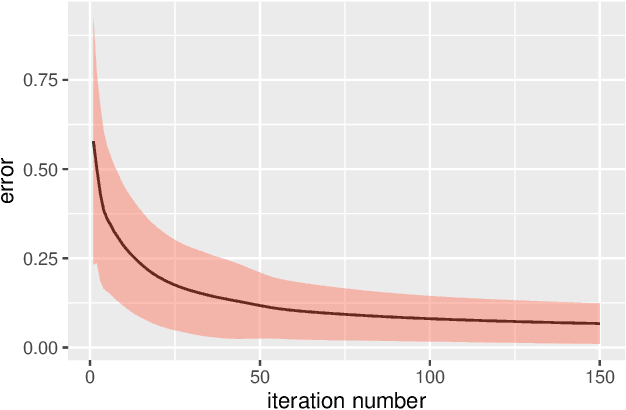
Learning of high-dimensional simplices from uniformly-sampled observations, generally known as the "unmixing problem", is a long-studied task in computer science. More recently, a significant interest is focused on this problem from other areas, such as computational biology and remote sensing. In this paper, we have studied the Probably Approximately Correct (PAC)-learnability of simplices with a focus on sample complexity. Our analysis shows that a sufficient sample size for PAC-learning of $K$-simplices is only $O\left(K^2\log K\right)$, yielding a huge improvement over the existing results, i.e. $O\left(K^{22}\right)$. Moreover, a novel continuously-relaxed optimization scheme is proposed which is guaranteed to achieve a PAC-approximation of the simplex, followed by a corresponding scalable algorithm whose performance is extensively tested on synthetic and real-world datasets. Experimental results show that not only being comparable to other existing strategies on noiseless samples, our method is superior to the state-of-the-art in noisy cases. The overall proposed framework is backed with solid theoretical guarantees and provides a rigorous framework for future research in this area.