 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Statistical Learning of Simplices: Unmixing Problem Revisited
Oct 18, 2018
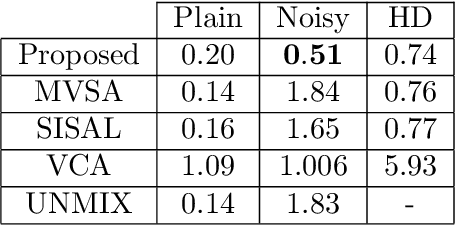
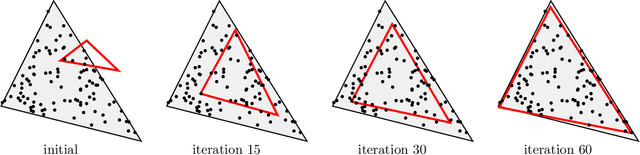
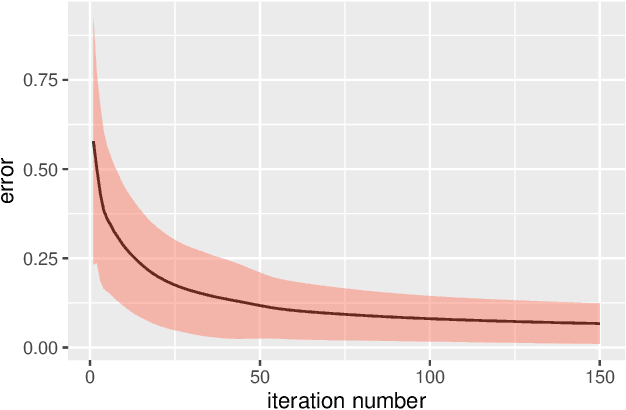
Learning of high-dimensional simplices from uniformly-sampled observations, generally known as the "unmixing problem", is a long-studied task in computer science. More recently, a significant interest is focused on this problem from other areas, such as computational biology and remote sensing. In this paper, we have studied the Probably Approximately Correct (PAC)-learnability of simplices with a focus on sample complexity. Our analysis shows that a sufficient sample size for PAC-learning of $K$-simplices is only $O\left(K^2\log K\right)$, yielding a huge improvement over the existing results, i.e. $O\left(K^{22}\right)$. Moreover, a novel continuously-relaxed optimization scheme is proposed which is guaranteed to achieve a PAC-approximation of the simplex, followed by a corresponding scalable algorithm whose performance is extensively tested on synthetic and real-world datasets. Experimental results show that not only being comparable to other existing strategies on noiseless samples, our method is superior to the state-of-the-art in noisy cases. The overall proposed framework is backed with solid theoretical guarantees and provides a rigorous framework for future research in this area.