 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Deep Neural Networks: A Versatile Edge Offloading Algorithm
Paper and Code
Jan 01, 2024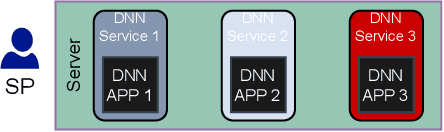
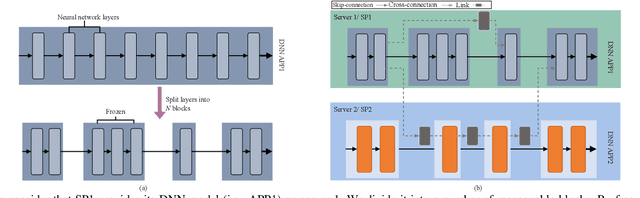
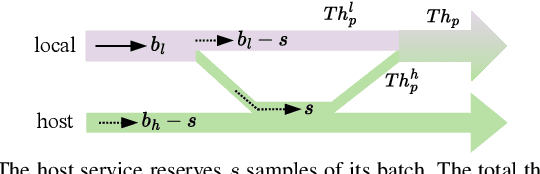
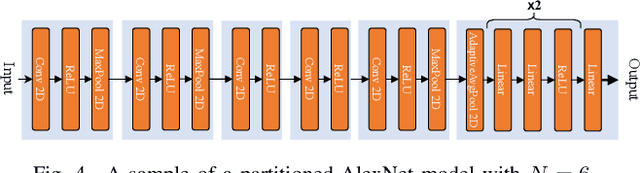
As artificial intelligence (AI) applications continue to expand, there is a growing need for deep neural network (DNN) models. Although DNN models deployed at the edge are promising to provide AI as a service with low latency, their cooperation is yet to be explored. In this paper, we consider the DNN service providers share their computing resources as well as their models' parameters and allow other DNNs to offload their computations without mirroring. We propose a novel algorithm called coordinated DNNs on edge (\textbf{CoDE}) that facilitates coordination among DNN services by creating multi-task DNNs out of individual models. CoDE aims to find the optimal path that results in the lowest possible cost, where the cost reflects the inference delay, model accuracy, and local computation workload. With CoDE, DNN models can make new paths for inference by using their own or other models' parameters. We then evaluate the performance of CoDE through numerical experiments. The results demonstrate a $75\%$ reduction in the local service computation workload while degrading the accuracy by only $2\%$ and having the same inference time in a balanced load condition. Under heavy load, CoDE can further decrease the inference time by $30\%$ while the accuracy is reduced by only $4\%$.