 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Domain Adaptation via Manifold-Constrained Distributionally Robust Optimization
Oct 17, 2024

The aim of this paper is to address the challenge of gradual domain adaptation within a class of manifold-constrained data distributions. In particular, we consider a sequence of $T\ge2$ data distributions $P_1,\ldots,P_T$ undergoing a gradual shift, where each pair of consecutive measures $P_i,P_{i+1}$ are close to each other in Wasserstein distance. We have a supervised dataset of size $n$ sampled from $P_0$, while for the subsequent distributions in the sequence, only unlabeled i.i.d. samples are available. Moreover, we assume that all distributions exhibit a known favorable attribute, such as (but not limited to) having intra-class soft/hard margins. In this context, we propose a methodology rooted in Distributionally Robust Optimization (DRO) with an adaptive Wasserstein radius. We theoretically show that this method guarantees the classification error across all $P_i$s can be suitably bounded. Our bounds rely on a newly introduced {\it {compatibility}} measure, which fully characterizes the error propagation dynamics along the sequence. Specifically, for inadequately constrained distributions, the error can exponentially escalate as we progress through the gradual shifts. Conversely, for appropriately constrained distributions, the error can be demonstrated to be linear or even entirely eradicated. We have substantiated our theoretical findings through several experimental results.
Unlabeled Out-Of-Domain Data Improves Generalization
Sep 29, 2023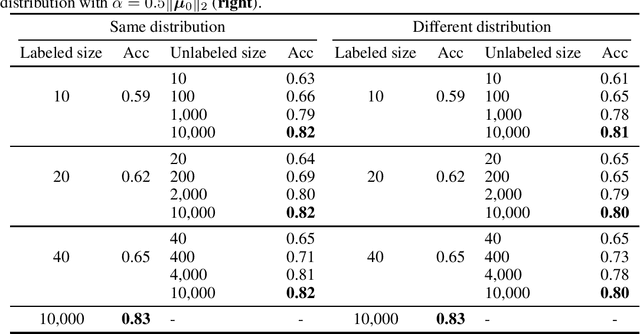
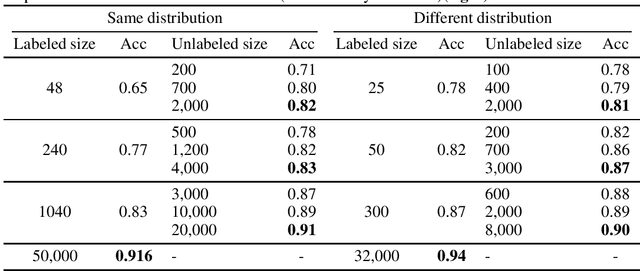
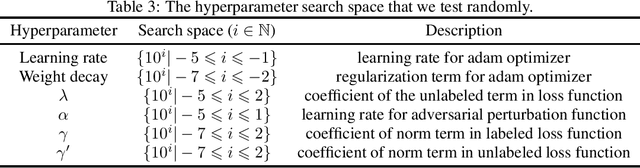
We propose a novel framework for incorporating unlabeled data into semi-supervised classification problems, where scenarios involving the minimization of either i) adversarially robust or ii) non-robust loss functions have been considered. Notably, we allow the unlabeled samples to deviate slightly (in total variation sense) from the in-domain distribution. The core idea behind our framework is to combine Distributionally Robust Optimization (DRO) with self-supervised training. As a result, we also leverage efficient polynomial-time algorithms for the training stage. From a theoretical standpoint, we apply our framework on the classification problem of a mixture of two Gaussians in $\mathbb{R}^d$, where in addition to the $m$ independent and labeled samples from the true distribution, a set of $n$ (usually with $n\gg m$) out of domain and unlabeled samples are gievn as well. Using only the labeled data, it is known that the generalization error can be bounded by $\propto\left(d/m\right)^{1/2}$. However, using our method on both isotropic and non-isotropic Gaussian mixture models, one can derive a new set of analytically explicit and non-asymptotic bounds which show substantial improvement on the generalization error compared ERM. Our results underscore two significant insights: 1) out-of-domain samples, even when unlabeled, can be harnessed to narrow the generalization gap, provided that the true data distribution adheres to a form of the "cluster assumption", and 2) the semi-supervised learning paradigm can be regarded as a special case of our framework when there are no distributional shifts. We validate our claims through experiments conducted on a variety of synthetic and real-world datasets.
Sample Complexity Bounds for Learning High-dimensional Simplices in Noisy Regimes
Sep 09, 2022In this paper, we propose a sample complexity bound for learning a simplex from noisy samples. A dataset of size $n$ is given which includes i.i.d. samples drawn from a uniform distribution over an unknown arbitrary simplex in $\mathbb{R}^K$, where samples are assumed to be corrupted by an additive Gaussian noise of an arbitrary magnitude. We propose a strategy which outputs a simplex having, with high probability, a total variation distance of $\epsilon + O\left(\mathrm{SNR}^{-1}\right)$ from the true simplex, for any $\epsilon>0$. We prove that to arrive this close to the true simplex, it is sufficient to have $n\ge\tilde{O}\left(K^2/\epsilon^2\right)$ samples. Here, SNR stands for the signal-to-noise ratio which can be viewed as the ratio of the diameter of the simplex to the standard deviation of the noise. Our proofs are based on recent advancements in sample compression techniques, which have already shown promises in deriving tight bounds for density estimation in high-dimensional Gaussian mixture models.