 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalization for Scalable Short-term Load Forecasting
Jul 15, 2025Forecasting load in power transmission networks is essential across various hierarchical levels, from the system level down to individual points of delivery (PoD). While intuitive and locally accurate, traditional local forecasting models (LFMs) face significant limitations, particularly in handling generalizability, overfitting, data drift, and the cold start problem. These methods also struggle with scalability, becoming computationally expensive and less efficient as the network's size and data volume grow. In contrast, global forecasting models (GFMs) offer a new approach to enhance prediction generalizability, scalability, accuracy, and robustness through globalization and cross-learning. This paper investigates global load forecasting in the presence of data drifts, highlighting the impact of different modeling techniques and data heterogeneity. We explore feature-transforming and target-transforming models, demonstrating how globalization, data heterogeneity, and data drift affect each differently. In addition, we examine the role of globalization in peak load forecasting and its potential for hierarchical forecasting. To address data heterogeneity and the balance between globality and locality, we propose separate time series clustering (TSC) methods, introducing model-based TSC for feature-transforming models and new weighted instance-based TSC for target-transforming models. Through extensive experiments on a real-world dataset of Alberta's electricity load, we demonstrate that global target-transforming models consistently outperform their local counterparts, especially when enriched with global features and clustering techniques. In contrast, global feature-transforming models face challenges in balancing local and global dynamics, often requiring TSC to manage data heterogeneity effectively.
DobLIX: A Dual-Objective Learned Index for Log-Structured Merge Trees
Feb 07, 2025



In this paper, we introduce DobLIX, a dual-objective learned index specifically designed for Log-Structured Merge(LSM) tree-based key-value stores. Although traditional learned indexes focus exclusively on optimizing index lookups, they often overlook the impact of data access from storage, resulting in performance bottlenecks. DobLIX addresses this by incorporating a second objective, data access optimization, into the learned index training process. This dual-objective approach ensures that both index lookup efficiency and data access costs are minimized, leading to significant improvements in read performance while maintaining write efficiency in real-world LSM-tree systems. Additionally, DobLIX features a reinforcement learning agent that dynamically tunes the system parameters, allowing it to adapt to varying workloads in real-time. Experimental results using real-world datasets demonstrate that DobLIX reduces indexing overhead and improves throughput by 1.19 to 2.21 times compared to state-of-the-art methods within RocksDB, a widely used LSM-tree-based storage engine.
UpLIF: An Updatable Self-Tuning Learned Index Framework
Aug 07, 2024The emergence of learned indexes has caused a paradigm shift in our perception of indexing by considering indexes as predictive models that estimate keys' positions within a data set, resulting in notable improvements in key search efficiency and index size reduction; however, a significant challenge inherent in learned index modeling is its constrained support for update operations, necessitated by the requirement for a fixed distribution of records. Previous studies have proposed various approaches to address this issue with the drawback of high overhead due to multiple model retraining. In this paper, we present UpLIF, an adaptive self-tuning learned index that adjusts the model to accommodate incoming updates, predicts the distribution of updates for performance improvement, and optimizes its index structure using reinforcement learning. We also introduce the concept of balanced model adjustment, which determines the model's inherent properties (i.e. bias and variance), enabling the integration of these factors into the existing index model without the need for retraining with new data. Our comprehensive experiments show that the system surpasses state-of-the-art indexing solutions (both traditional and ML-based), achieving an increase in throughput of up to 3.12 times with 1000 times less memory usage.
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores
Jul 26, 2024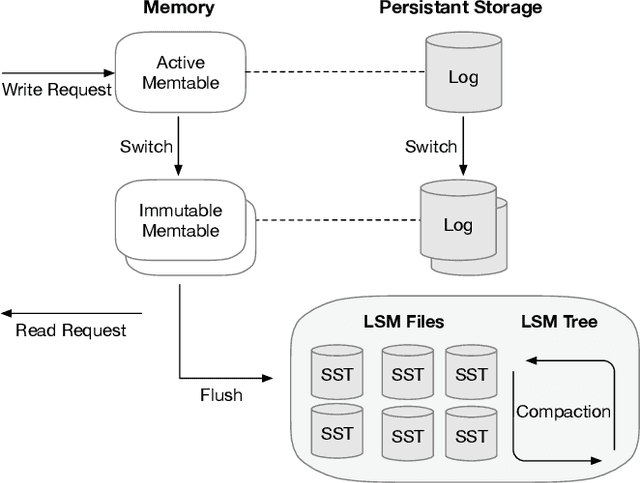
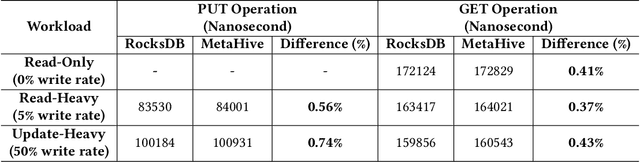
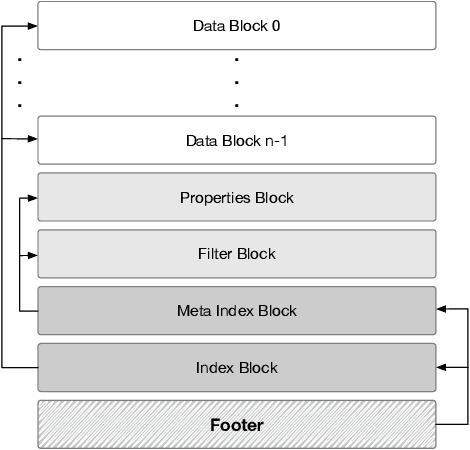
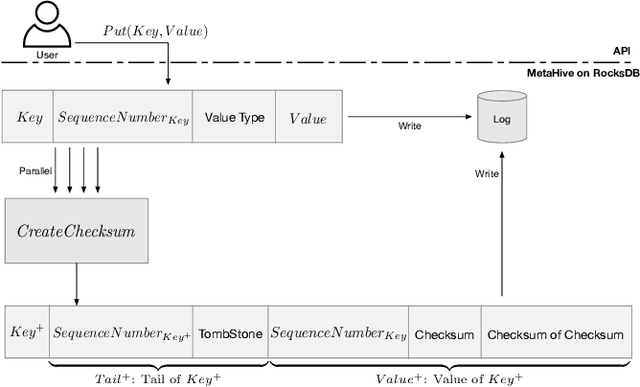
Cloud key-value (KV) stores provide businesses with a cost-effective and adaptive alternative to traditional on-premise data management solutions. KV stores frequently consist of heterogeneous clusters, characterized by varying hardware specifications of the deployment nodes, with each node potentially running a distinct version of the KV store software. This heterogeneity is accompanied by the diverse metadata that they need to manage. In this study, we introduce MetaHive, a cache-optimized approach to managing metadata in heterogeneous KV store clusters. MetaHive disaggregates the original data from its associated metadata to promote independence between them, while maintaining their interconnection during usage. This makes the metadata opaque from the downstream processes and the other KV stores in the cluster. MetaHive also ensures that the KV and metadata entries are stored in the vicinity of each other in memory and storage. This allows MetaHive to optimally utilize the caching mechanism without extra storage read overhead for metadata retrieval. We deploy MetaHive to ensure data integrity in RocksDB and demonstrate its rapid data validation with minimal effect on performance.
* Cloud Databases