 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMIXER: End-to-end Multimodal X-ray Generation via Self-supervision
Jul 10, 2020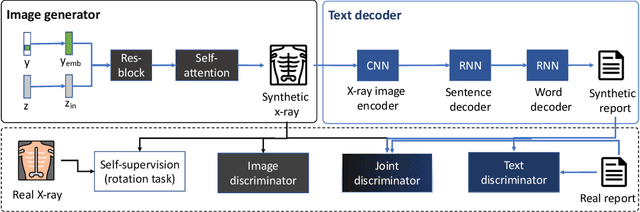

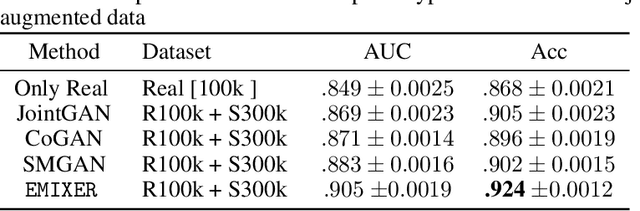

Deep generative models have enabled the automated synthesis of high-quality data for diverse applications. However, the most effective generative models are specialized to data from a single domain (e.g., images or text). Real-world applications such as healthcare require multi-modal data from multiple domains (e.g., both images and corresponding text), which are difficult to acquire due to limited availability and privacy concerns and are much harder to synthesize. To tackle this joint synthesis challenge, we propose an End-to-end MultImodal X-ray genERative model (EMIXER) for jointly synthesizing x-ray images and corresponding free-text reports, all conditional on diagnosis labels. EMIXER is an conditional generative adversarial model by 1) generating an image based on a label, 2) encoding the image to a hidden embedding, 3) producing the corresponding text via a hierarchical decoder from the image embedding, and 4) a joint discriminator for assessing both the image and the corresponding text. EMIXER also enables self-supervision to leverage vast amount of unlabeled data. Extensive experiments with real X-ray reports data illustrate how data augmentation using synthesized multimodal samples can improve the performance of a variety of supervised tasks including COVID-19 X-ray classification with very limited samples. The quality of generated images and reports are also confirmed by radiologists. We quantitatively show that EMIXER generated synthetic datasets can augment X-ray image classification, report generation models to achieve 5.94% and 6.9% improvement on models trained only on real data samples. Taken together, our results highlight the promise of state of generative models to advance clinical machine learning.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019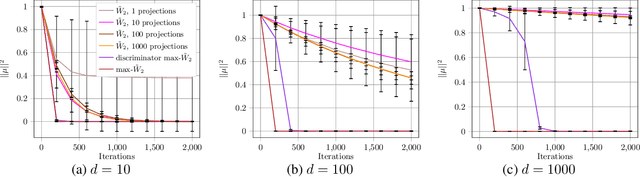

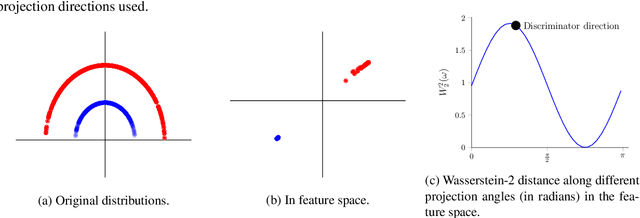

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.