 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Mamba's Selective Memory using Auto-Encoders
Dec 17, 2025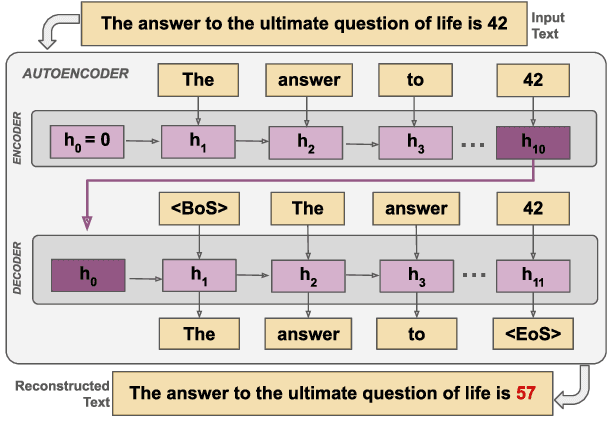
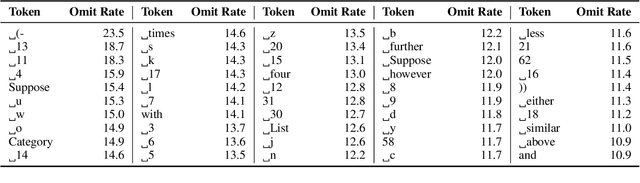
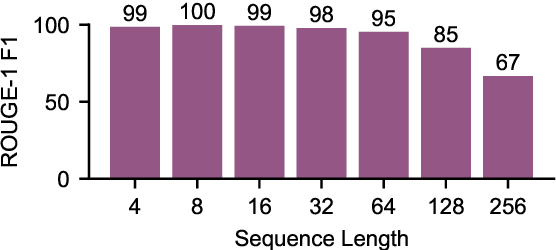
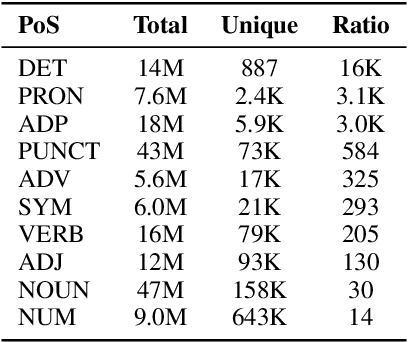
State space models (SSMs) are a promising alternative to transformers for language modeling because they use fixed memory during inference. However, this fixed memory usage requires some information loss in the hidden state when processing long sequences. While prior work has studied the sequence length at which this information loss occurs, it does not characterize the types of information SSM language models (LMs) tend to forget. In this paper, we address this knowledge gap by identifying the types of tokens (e.g., parts of speech, named entities) and sequences (e.g., code, math problems) that are more frequently forgotten by SSM LMs. We achieve this by training an auto-encoder to reconstruct sequences from the SSM's hidden state, and measure information loss by comparing inputs with their reconstructions. We perform experiments using the Mamba family of SSM LMs (130M--1.4B) on sequences ranging from 4--256 tokens. Our results show significantly higher rates of information loss on math-related tokens (e.g., numbers, variables), mentions of organization entities, and alternative dialects to Standard American English. We then examine the frequency that these tokens appear in Mamba's pretraining data and find that less prevalent tokens tend to be the ones Mamba is most likely to forget. By identifying these patterns, our work provides clear direction for future research to develop methods that better control Mamba's ability to retain important information.
MisgenderMender: A Community-Informed Approach to Interventions for Misgendering
Apr 23, 2024

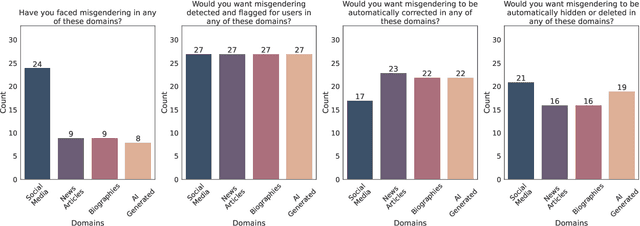

Content Warning: This paper contains examples of misgendering and erasure that could be offensive and potentially triggering. Misgendering, the act of incorrectly addressing someone's gender, inflicts serious harm and is pervasive in everyday technologies, yet there is a notable lack of research to combat it. We are the first to address this lack of research into interventions for misgendering by conducting a survey of gender-diverse individuals in the US to understand perspectives about automated interventions for text-based misgendering. Based on survey insights on the prevalence of misgendering, desired solutions, and associated concerns, we introduce a misgendering interventions task and evaluation dataset, MisgenderMender. We define the task with two sub-tasks: (i) detecting misgendering, followed by (ii) correcting misgendering where misgendering is present in domains where editing is appropriate. MisgenderMender comprises 3790 instances of social media content and LLM-generations about non-cisgender public figures, annotated for the presence of misgendering, with additional annotations for correcting misgendering in LLM-generated text. Using this dataset, we set initial benchmarks by evaluating existing NLP systems and highlighting challenges for future models to address. We release the full dataset, code, and demo at https://tamannahossainkay.github.io/misgendermender/.
MISGENDERED: Limits of Large Language Models in Understanding Pronouns
Jun 06, 2023Content Warning: This paper contains examples of misgendering and erasure that could be offensive and potentially triggering. Gender bias in language technologies has been widely studied, but research has mostly been restricted to a binary paradigm of gender. It is essential also to consider non-binary gender identities, as excluding them can cause further harm to an already marginalized group. In this paper, we comprehensively evaluate popular language models for their ability to correctly use English gender-neutral pronouns (e.g., singular they, them) and neo-pronouns (e.g., ze, xe, thon) that are used by individuals whose gender identity is not represented by binary pronouns. We introduce MISGENDERED, a framework for evaluating large language models' ability to correctly use preferred pronouns, consisting of (i) instances declaring an individual's pronoun, followed by a sentence with a missing pronoun, and (ii) an experimental setup for evaluating masked and auto-regressive language models using a unified method. When prompted out-of-the-box, language models perform poorly at correctly predicting neo-pronouns (averaging 7.6% accuracy) and gender-neutral pronouns (averaging 31.0% accuracy). This inability to generalize results from a lack of representation of non-binary pronouns in training data and memorized associations. Few-shot adaptation with explicit examples in the prompt improves the performance but plateaus at only 45.4% for neo-pronouns. We release the full dataset, code, and demo at https://tamannahossainkay.github.io/misgendered/