 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Deep Research: A Benchmark and Formal Definition
Aug 06, 2025Information tasks such as writing surveys or analytical reports require complex search and reasoning, and have recently been grouped under the umbrella of \textit{deep research} -- a term also adopted by recent models targeting these capabilities. Despite growing interest, the scope of the deep research task remains underdefined and its distinction from other reasoning-intensive problems is poorly understood. In this paper, we propose a formal characterization of the deep research (DR) task and introduce a benchmark to evaluate the performance of DR systems. We argue that the core defining feature of deep research is not the production of lengthy report-style outputs, but rather the high fan-out over concepts required during the search process, i.e., broad and reasoning-intensive exploration. To enable objective evaluation, we define DR using an intermediate output representation that encodes key claims uncovered during search-separating the reasoning challenge from surface-level report generation. Based on this formulation, we propose a diverse, challenging benchmark LiveDRBench with 100 challenging tasks over scientific topics (e.g., datasets, materials discovery, prior art search) and public interest events (e.g., flight incidents, movie awards). Across state-of-the-art DR systems, F1 score ranges between 0.02 and 0.72 for any sub-category. OpenAI's model performs the best with an overall F1 score of 0.55. Analysis of reasoning traces reveals the distribution over the number of referenced sources, branching, and backtracking events executed by current DR systems, motivating future directions for improving their search mechanisms and grounding capabilities. The benchmark is available at https://github.com/microsoft/LiveDRBench.
Building English ASR model with regional language support
Mar 10, 2025
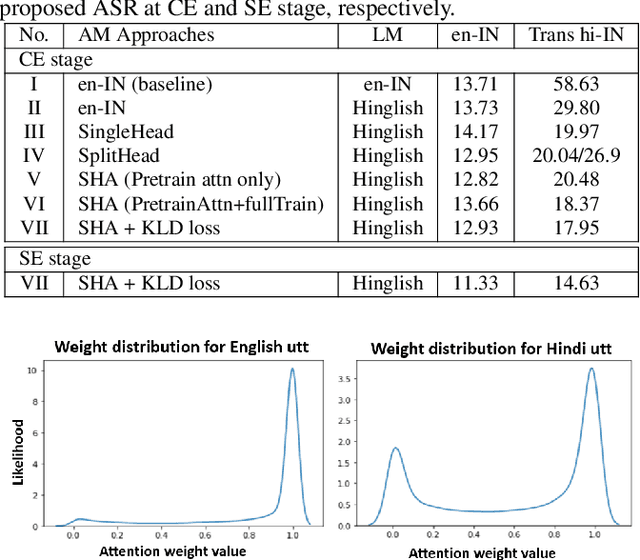

In this paper, we present a novel approach to developing an English Automatic Speech Recognition (ASR) system that can effectively handle Hindi queries, without compromising its performance on English. We propose a novel acoustic model (AM), referred to as SplitHead with Attention (SHA) model, features shared hidden layers across languages and language-specific projection layers combined via a self-attention mechanism. This mechanism estimates the weight for each language based on input data and weighs the corresponding language-specific projection layers accordingly. Additionally, we propose a language modeling approach that interpolates n-gram models from both English and transliterated Hindi text corpora. Our results demonstrate the effectiveness of our approach, with a 69.3% and 5.7% relative reduction in word error rate on Hindi and English test sets respectively when compared to a monolingual English model.
CAVE: Classifying Abnormalities in Video Capsule Endoscopy
Oct 26, 2024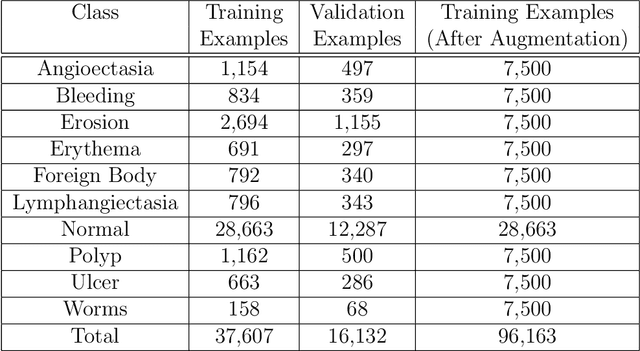
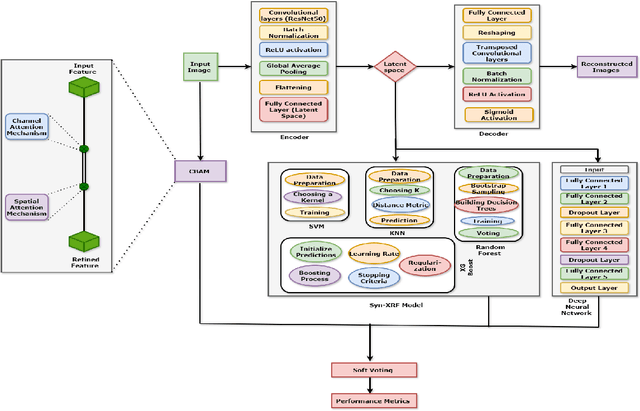
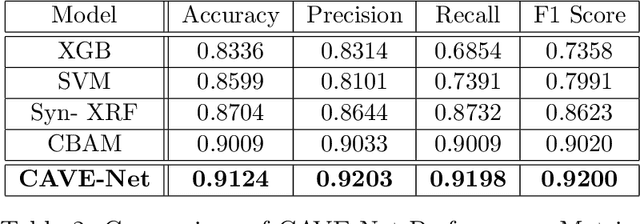
In this study, we explore an ensemble-based approach to improve classification accuracy in complex image datasets. Utilizing a Convolutional Block Attention Module (CBAM) alongside a Deep Neural Network (DNN) we leverage the unique feature-extraction capabilities of each model to enhance the overall accuracy. Additional models, such as Random Forest, XGBoost, Support Vector Machine (SVM), and K-Nearest Neighbors (KNN), are introduced to further diversify the predictive power of our ensemble. By leveraging these methods, the proposed approach provides robust feature discrimination and improved classification results. Experimental evaluations demonstrate that the ensemble achieves higher accuracy and robustness across challenging and imbalanced classes, showing significant promise for broader applications in computer vision tasks.
Unsupervised Language agnostic WER Standardization
Mar 09, 2023



Word error rate (WER) is a standard metric for the evaluation of Automated Speech Recognition (ASR) systems. However, WER fails to provide a fair evaluation of human perceived quality in presence of spelling variations, abbreviations, or compound words arising out of agglutination. Multiple spelling variations might be acceptable based on locale/geography, alternative abbreviations, borrowed words, and transliteration of code-mixed words from a foreign language to the target language script. Similarly, in case of agglutination, often times the agglutinated, as well as the split forms, are acceptable. Previous work handled this problem by using manually identified normalization pairs and applying them to both the transcription and the hypothesis before computing WER. In this paper, we propose an automatic WER normalization system consisting of two modules: spelling normalization and segmentation normalization. The proposed system is unsupervised and language agnostic, and therefore scalable. Experiments with ASR on 35K utterances across four languages yielded an average WER reduction of 13.28%. Human judgements of these automatically identified normalization pairs show that our WER-normalized evaluation is highly consistent with the perceived quality of ASR output.
Unsupervised Contextualized Document Representation
Sep 22, 2021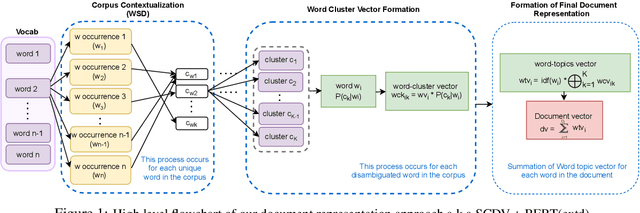
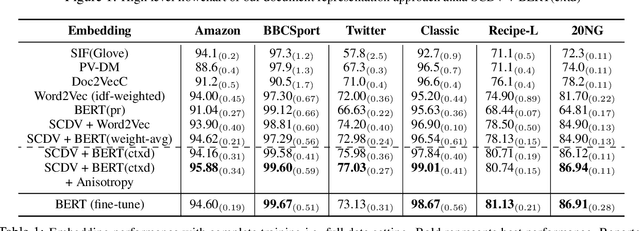
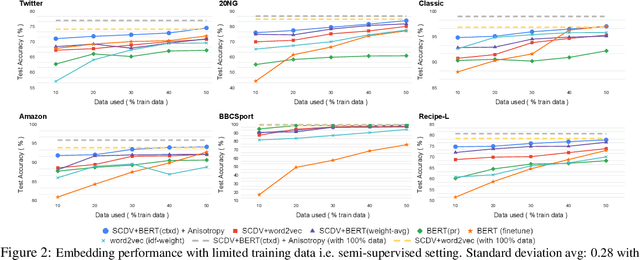
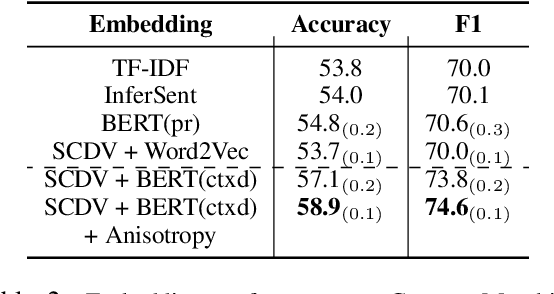
Several NLP tasks need the effective representation of text documents. Arora et. al., 2017 demonstrate that simple weighted averaging of word vectors frequently outperforms neural models. SCDV (Mekala et. al., 2017) further extends this from sentences to documents by employing soft and sparse clustering over pre-computed word vectors. However, both techniques ignore the polysemy and contextual character of words. In this paper, we address this issue by proposing SCDV+BERT(ctxd), a simple and effective unsupervised representation that combines contextualized BERT (Devlin et al., 2019) based word embedding for word sense disambiguation with SCDV soft clustering approach. We show that our embeddings outperform original SCDV, pre-train BERT, and several other baselines on many classification datasets. We also demonstrate our embeddings effectiveness on other tasks, such as concept matching and sentence similarity. In addition, we show that SCDV+BERT(ctxd) outperforms fine-tune BERT and different embedding approaches in scenarios with limited data and only few shots examples.
BreakingBERT@IITK at SemEval-2021 Task 9 : Statement Verification and Evidence Finding with Tables
Apr 10, 2021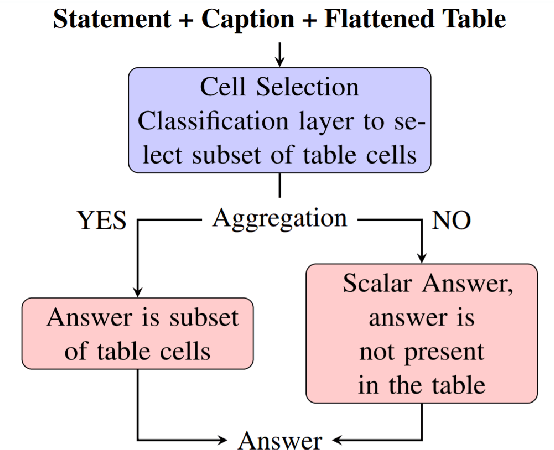
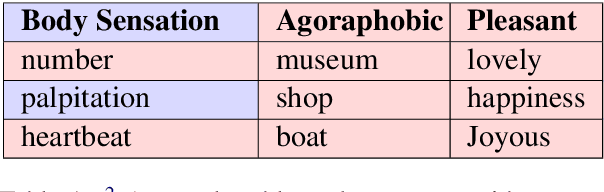

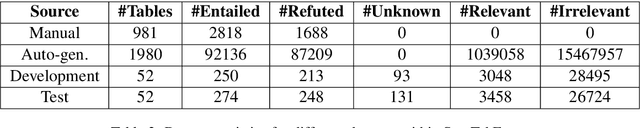
Recently, there has been an interest in factual verification and prediction over structured data like tables and graphs. To circumvent any false news incident, it is necessary to not only model and predict over structured data efficiently but also to explain those predictions. In this paper, as part of the SemEval-2021 Task 9, we tackle the problem of fact verification and evidence finding over tabular data. There are two subtasks. Given a table and a statement/fact, subtask A determines whether the statement is inferred from the tabular data, and subtask B determines which cells in the table provide evidence for the former subtask. We make a comparison of the baselines and state-of-the-art approaches over the given SemTabFact dataset. We also propose a novel approach CellBERT to solve evidence finding as a form of the Natural Language Inference task. We obtain a 3-way F1 score of 0.69 on subtask A and an F1 score of 0.65 on subtask B.
TruthBot: An Automated Conversational Tool for Intent Learning, Curated Information Presenting, and Fake News Alerting
Jan 31, 2021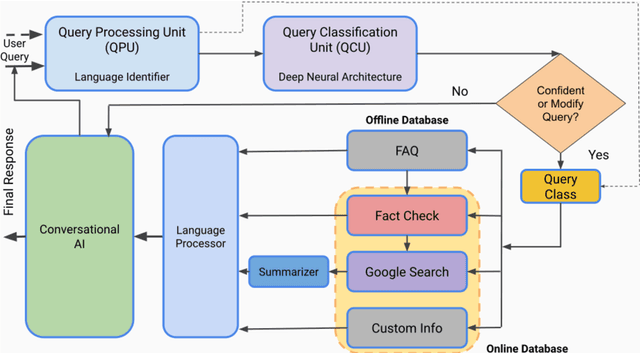
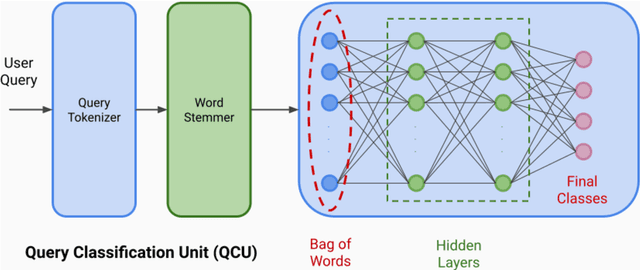

We present TruthBot, an all-in-one multilingual conversational chatbot designed for seeking truth (trustworthy and verified information) on specific topics. It helps users to obtain information specific to certain topics, fact-check information, and get recent news. The chatbot learns the intent of a query by training a deep neural network from the data of the previous intents and responds appropriately when it classifies the intent in one of the classes above. Each class is implemented as a separate module that uses either its own curated knowledge-base or searches the web to obtain the correct information. The topic of the chatbot is currently set to COVID-19. However, the bot can be easily customized to any topic-specific responses. Our experimental results show that each module performs significantly better than its closest competitor, which is verified both quantitatively and through several user-based surveys in multiple languages. TruthBot has been deployed in June 2020 and is currently running.
Counterfactual Estimation and Optimization of Click Metrics for Search Engines
Mar 12, 2014
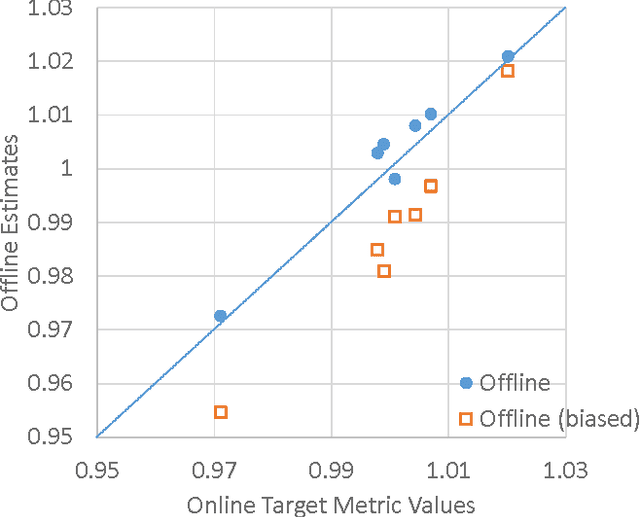
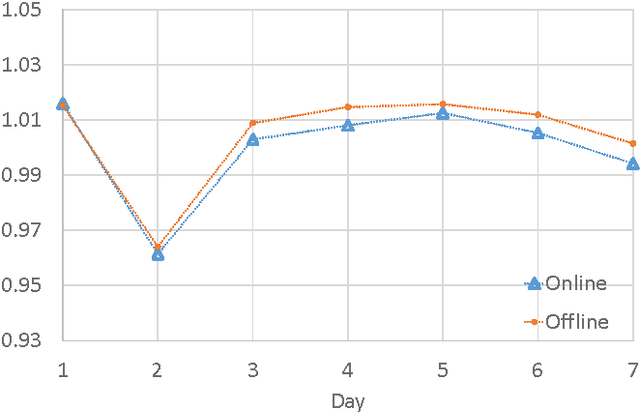
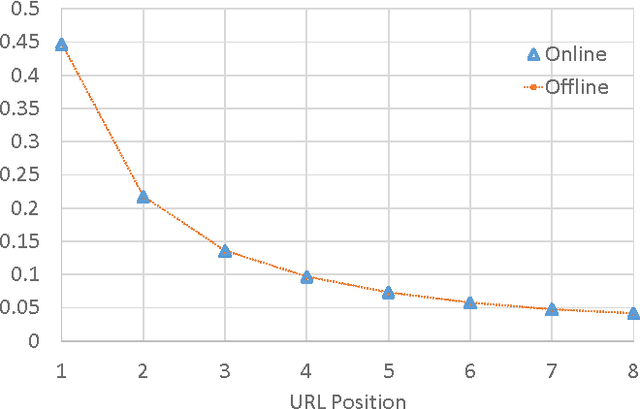
Optimizing an interactive system against a predefined online metric is particularly challenging, when the metric is computed from user feedback such as clicks and payments. The key challenge is the counterfactual nature: in the case of Web search, any change to a component of the search engine may result in a different search result page for the same query, but we normally cannot infer reliably from search log how users would react to the new result page. Consequently, it appears impossible to accurately estimate online metrics that depend on user feedback, unless the new engine is run to serve users and compared with a baseline in an A/B test. This approach, while valid and successful, is unfortunately expensive and time-consuming. In this paper, we propose to address this problem using causal inference techniques, under the contextual-bandit framework. This approach effectively allows one to run (potentially infinitely) many A/B tests offline from search log, making it possible to estimate and optimize online metrics quickly and inexpensively. Focusing on an important component in a commercial search engine, we show how these ideas can be instantiated and applied, and obtain very promising results that suggest the wide applicability of these techniques.
Automated Switching System for Skin Pixel Segmentation in Varied Lighting
Apr 17, 2013

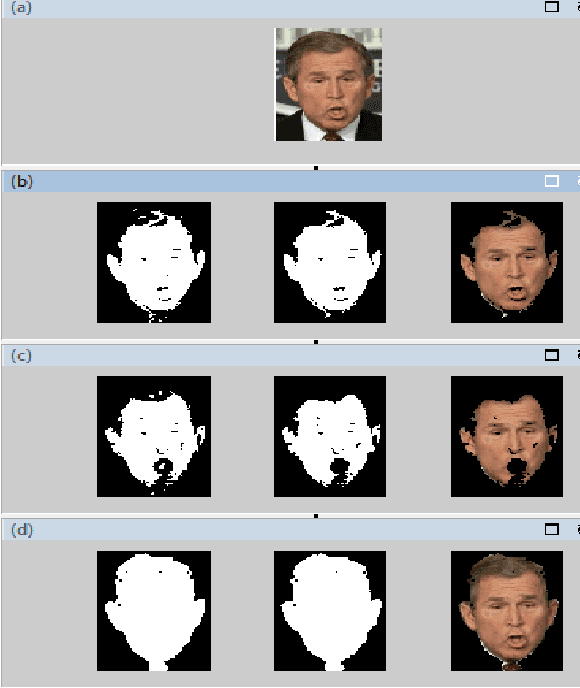
In Computer Vision, colour-based spatial techniquesoften assume a static skin colour model. However, skin colour perceived by a camera can change when lighting changes. In common real environment multiple light sources impinge on the skin. Moreover, detection techniques may vary when the image under study is taken under different lighting condition than the one that was earlier under consideration. Therefore, for robust skin pixel detection, a dynamic skin colour model that can cope with the changes must be employed. This paper shows that skin pixel detection in a digital colour image can be significantly improved by employing automated colour space switching methods. In the root of the switching technique which is employed in this study, lies the statistical mean of value of the skin pixels in the image which in turn has been derived from the Value, measures as a third component of the HSV. The study is based on experimentations on a set of images where capture time conditions varying from highly illuminated to almost dark.
* 6 pages