 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Language agnostic WER Standardization
Mar 09, 2023



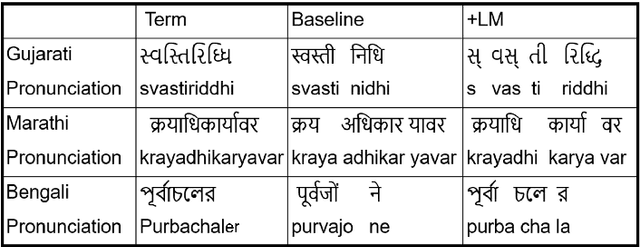
Word error rate (WER) is a standard metric for the evaluation of Automated Speech Recognition (ASR) systems. However, WER fails to provide a fair evaluation of human perceived quality in presence of spelling variations, abbreviations, or compound words arising out of agglutination. Multiple spelling variations might be acceptable based on locale/geography, alternative abbreviations, borrowed words, and transliteration of code-mixed words from a foreign language to the target language script. Similarly, in case of agglutination, often times the agglutinated, as well as the split forms, are acceptable. Previous work handled this problem by using manually identified normalization pairs and applying them to both the transcription and the hypothesis before computing WER. In this paper, we propose an automatic WER normalization system consisting of two modules: spelling normalization and segmentation normalization. The proposed system is unsupervised and language agnostic, and therefore scalable. Experiments with ASR on 35K utterances across four languages yielded an average WER reduction of 13.28%. Human judgements of these automatically identified normalization pairs show that our WER-normalized evaluation is highly consistent with the perceived quality of ASR output.
Cross-lingual and Multilingual Spoken Term Detection for Low-Resource Indian Languages
Nov 12, 2020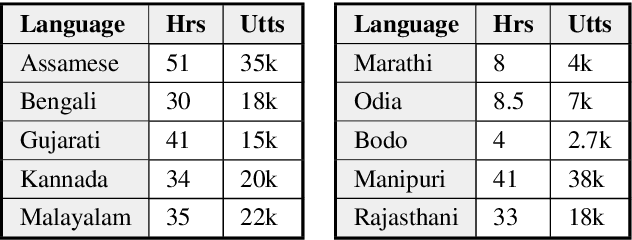

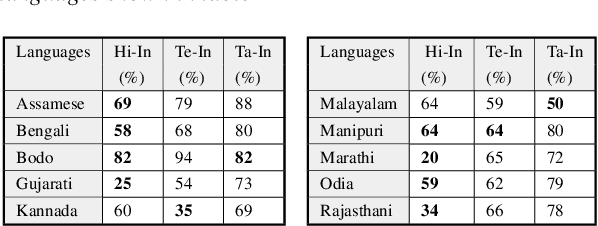
Spoken Term Detection (STD) is the task of searching for words or phrases within audio, given either text or spoken input as a query. In this work, we use state-of-the-art Hindi, Tamil and Telugu ASR systems cross-lingually for lexical Spoken Term Detection in ten low-resource Indian languages. Since no publicly available dataset exists for Spoken Term Detection in these languages, we create a new dataset using a publicly available TTS dataset. We report a standard metric for STD, Mean Term Weighted Value (MTWV) and show that ASR systems built in languages that are phonetically similar to the target languages have higher accuracy, however, it is also possible to get high MTWV scores for dissimilar languages by using a relaxed phone matching algorithm. We propose a technique to bootstrap the Grapheme-to-Phoneme (g2p) mapping between all the languages under consideration using publicly available resources. Gains are obtained when we combine the output of multiple ASR systems and when we use language-specific Language Models. We show that it is possible to perform STD cross-lingually in a zero-shot manner without the need for any language-specific speech data. We plan to make the STD dataset available for other researchers interested in cross-lingual STD.