 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Contextualized Document Representation
Paper and Code
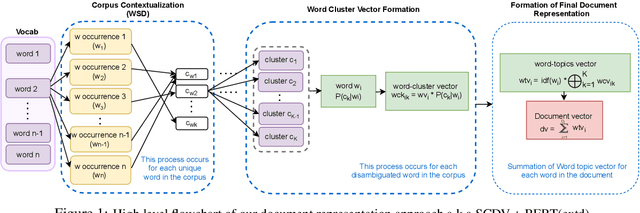
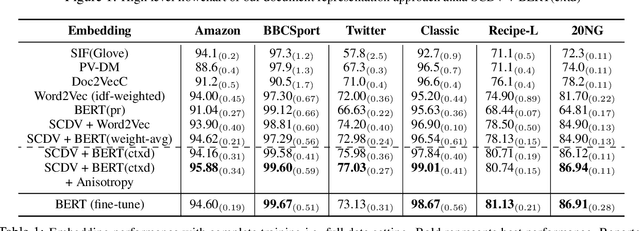
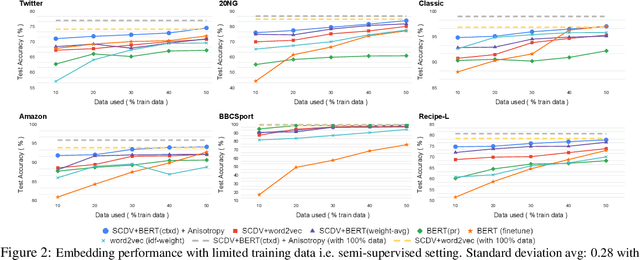
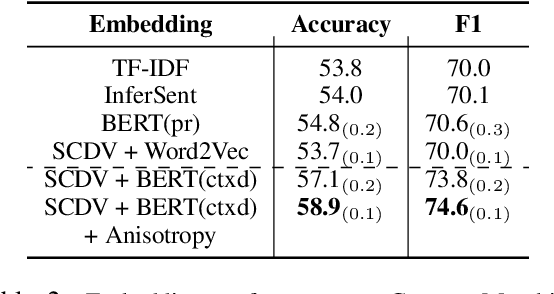
Several NLP tasks need the effective representation of text documents. Arora et. al., 2017 demonstrate that simple weighted averaging of word vectors frequently outperforms neural models. SCDV (Mekala et. al., 2017) further extends this from sentences to documents by employing soft and sparse clustering over pre-computed word vectors. However, both techniques ignore the polysemy and contextual character of words. In this paper, we address this issue by proposing SCDV+BERT(ctxd), a simple and effective unsupervised representation that combines contextualized BERT (Devlin et al., 2019) based word embedding for word sense disambiguation with SCDV soft clustering approach. We show that our embeddings outperform original SCDV, pre-train BERT, and several other baselines on many classification datasets. We also demonstrate our embeddings effectiveness on other tasks, such as concept matching and sentence similarity. In addition, we show that SCDV+BERT(ctxd) outperforms fine-tune BERT and different embedding approaches in scenarios with limited data and only few shots examples.