 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic AI controller that can drive with confidence: steering vehicle with uncertainty knowledge
Apr 24, 2024
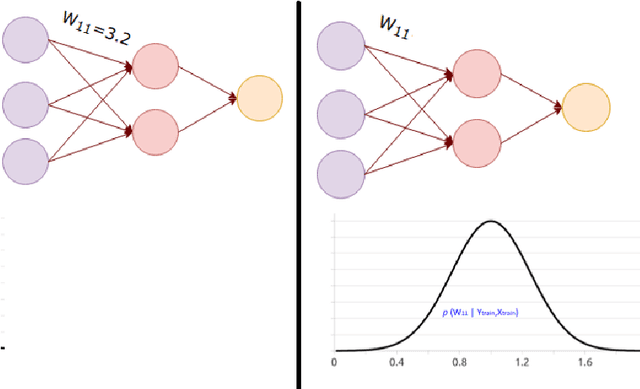

In safety-critical systems that interface with the real world, the role of uncertainty in decision-making is pivotal, particularly in the context of machine learning models. For the secure functioning of Cyber-Physical Systems (CPS), it is imperative to manage such uncertainty adeptly. In this research, we focus on the development of a vehicle's lateral control system using a machine learning framework. Specifically, we employ a Bayesian Neural Network (BNN), a probabilistic learning model, to address uncertainty quantification. This capability allows us to gauge the level of confidence or uncertainty in the model's predictions. The BNN based controller is trained using simulated data gathered from the vehicle traversing a single track and subsequently tested on various other tracks. We want to share two significant results: firstly, the trained model demonstrates the ability to adapt and effectively control the vehicle on multiple similar tracks. Secondly, the quantification of prediction confidence integrated into the controller serves as an early-warning system, signaling when the algorithm lacks confidence in its predictions and is therefore susceptible to failure. By establishing a confidence threshold, we can trigger manual intervention, ensuring that control is relinquished from the algorithm when it operates outside of safe parameters.
Language Variety Identification with True Labels
Mar 02, 2023



Language identification is an important first step in many IR and NLP applications. Most publicly available language identification datasets, however, are compiled under the assumption that the gold label of each instance is determined by where texts are retrieved from. Research has shown that this is a problematic assumption, particularly in the case of very similar languages (e.g., Croatian and Serbian) and national language varieties (e.g., Brazilian and European Portuguese), where texts may contain no distinctive marker of the particular language or variety. To overcome this important limitation, this paper presents DSL True Labels (DSL-TL), the first human-annotated multilingual dataset for language variety identification. DSL-TL contains a total of 12,900 instances in Portuguese, split between European Portuguese and Brazilian Portuguese; Spanish, split between Argentine Spanish and Castilian Spanish; and English, split between American English and British English. We trained multiple models to discriminate between these language varieties, and we present the results in detail. The data and models presented in this paper provide a reliable benchmark toward the development of robust and fairer language variety identification systems. We make DSL-TL freely available to the research community.