 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Variety Identification with True Labels
Mar 02, 2023



Language identification is an important first step in many IR and NLP applications. Most publicly available language identification datasets, however, are compiled under the assumption that the gold label of each instance is determined by where texts are retrieved from. Research has shown that this is a problematic assumption, particularly in the case of very similar languages (e.g., Croatian and Serbian) and national language varieties (e.g., Brazilian and European Portuguese), where texts may contain no distinctive marker of the particular language or variety. To overcome this important limitation, this paper presents DSL True Labels (DSL-TL), the first human-annotated multilingual dataset for language variety identification. DSL-TL contains a total of 12,900 instances in Portuguese, split between European Portuguese and Brazilian Portuguese; Spanish, split between Argentine Spanish and Castilian Spanish; and English, split between American English and British English. We trained multiple models to discriminate between these language varieties, and we present the results in detail. The data and models presented in this paper provide a reliable benchmark toward the development of robust and fairer language variety identification systems. We make DSL-TL freely available to the research community.
Constructing Open Cloze Tests Using Generation and Discrimination Capabilities of Transformers
Apr 14, 2022
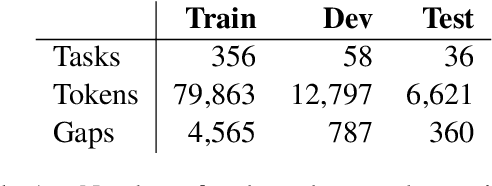
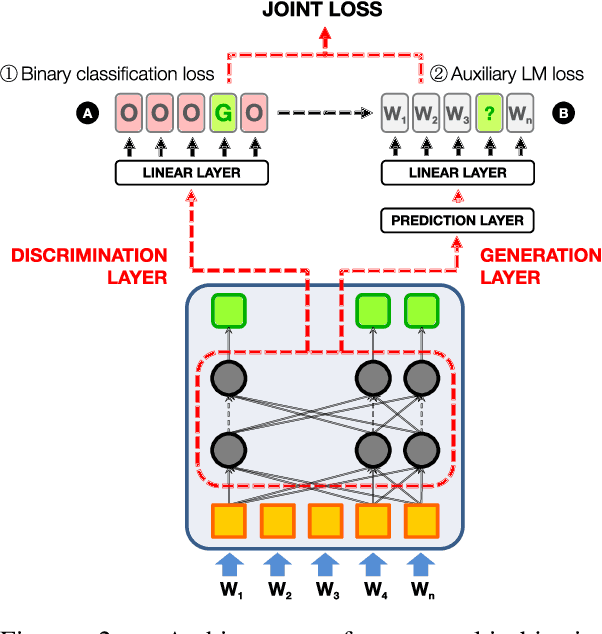

This paper presents the first multi-objective transformer model for constructing open cloze tests that exploits generation and discrimination capabilities to improve performance. Our model is further enhanced by tweaking its loss function and applying a post-processing re-ranking algorithm that improves overall test structure. Experiments using automatic and human evaluation show that our approach can achieve up to 82% accuracy according to experts, outperforming previous work and baselines. We also release a collection of high-quality open cloze tests along with sample system output and human annotations that can serve as a future benchmark.
Artificial Error Generation with Machine Translation and Syntactic Patterns
Jul 17, 2017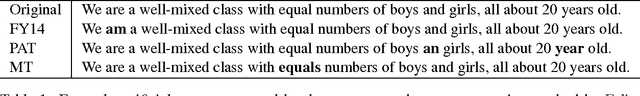
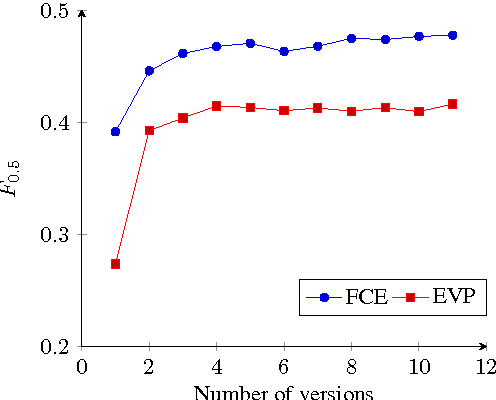

Shortage of available training data is holding back progress in the area of automated error detection. This paper investigates two alternative methods for artificially generating writing errors, in order to create additional resources. We propose treating error generation as a machine translation task, where grammatically correct text is translated to contain errors. In addition, we explore a system for extracting textual patterns from an annotated corpus, which can then be used to insert errors into grammatically correct sentences. Our experiments show that the inclusion of artificially generated errors significantly improves error detection accuracy on both FCE and CoNLL 2014 datasets.