 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntax-Aware Graph-to-Graph Transformer for Semantic Role Labelling
Paper and Code
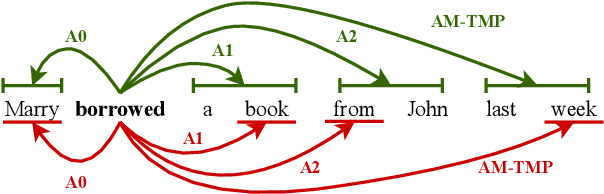


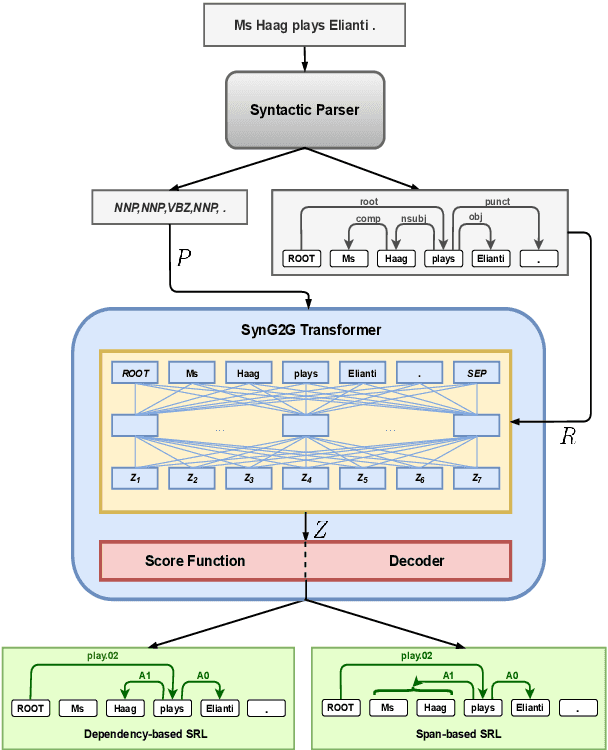
The goal of semantic role labelling (SRL) is to recognise the predicate-argument structure of a sentence. Recent models have shown that syntactic information can enhance the SRL performance, but other syntax-agnostic approaches achieved reasonable performance. The best way to encode syntactic information for the SRL task is still an open question. In this paper, we propose the Syntax-aware Graph-to-Graph Transformer (SynG2G-Tr) architecture, which encodes the syntactic structure with a novel way to input graph relations as embeddings directly into the self-attention mechanism of Transformer. This approach adds a soft bias towards attention patterns that follow the syntactic structure but also allows the model to use this information to learn alternative patterns. We evaluate our model on both dependency-based and span-based SRL datasets, and outperform all previous syntax-aware and syntax-agnostic models in both in-domain and out-of-domain settings, on the CoNLL 2005 and CoNLL 2009 datasets. Our architecture is general and can be applied to encode any graph information for a desired downstream task.