 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwissGov-RSD: A Human-annotated, Cross-lingual Benchmark for Token-level Recognition of Semantic Differences Between Related Documents
Dec 08, 2025Recognizing semantic differences across documents, especially in different languages, is crucial for text generation evaluation and multilingual content alignment. However, as a standalone task it has received little attention. We address this by introducing SwissGov-RSD, the first naturalistic, document-level, cross-lingual dataset for semantic difference recognition. It encompasses a total of 224 multi-parallel documents in English-German, English-French, and English-Italian with token-level difference annotations by human annotators. We evaluate a variety of open-source and closed source large language models as well as encoder models across different fine-tuning settings on this new benchmark. Our results show that current automatic approaches perform poorly compared to their performance on monolingual, sentence-level, and synthetic benchmarks, revealing a considerable gap for both LLMs and encoder models. We make our code and datasets publicly available.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
20min-XD: A Comparable Corpus of Swiss News Articles
Apr 30, 2025We present 20min-XD (20 Minuten cross-lingual document-level), a French-German, document-level comparable corpus of news articles, sourced from the Swiss online news outlet 20 Minuten/20 minutes. Our dataset comprises around 15,000 article pairs spanning 2015 to 2024, automatically aligned based on semantic similarity. We detail the data collection process and alignment methodology. Furthermore, we provide a qualitative and quantitative analysis of the corpus. The resulting dataset exhibits a broad spectrum of cross-lingual similarity, ranging from near-translations to loosely related articles, making it valuable for various NLP applications and broad linguistically motivated studies. We publicly release the dataset in document- and sentence-aligned versions and code for the described experiments.
Source-primed Multi-turn Conversation Helps Large Language Models Translate Documents
Mar 13, 2025LLMs have paved the way for truly simple document-level machine translation, but challenges such as omission errors remain. In this paper, we study a simple method for handling document-level machine translation, by leveraging previous contexts in a multi-turn conversational manner. Specifically, by decomposing documents into segments and iteratively translating them while maintaining previous turns, this method ensures coherent translations without additional training, and can fully re-use the KV cache of previous turns thus minimizing computational overhead. We further propose a `source-primed' method that first provides the whole source document before multi-turn translation. We empirically show this multi-turn method outperforms both translating entire documents in a single turn and translating each segment independently according to multiple automatic metrics in representative LLMs, establishing a strong baseline for document-level translation using LLMs.
Fine-tuning the SwissBERT Encoder Model for Embedding Sentences and Documents
May 13, 2024



Encoder models trained for the embedding of sentences or short documents have proven useful for tasks such as semantic search and topic modeling. In this paper, we present a version of the SwissBERT encoder model that we specifically fine-tuned for this purpose. SwissBERT contains language adapters for the four national languages of Switzerland -- German, French, Italian, and Romansh -- and has been pre-trained on a large number of news articles in those languages. Using contrastive learning based on a subset of these articles, we trained a fine-tuned version, which we call SentenceSwissBERT. Multilingual experiments on document retrieval and text classification in a Switzerland-specific setting show that SentenceSwissBERT surpasses the accuracy of the original SwissBERT model and of a comparable baseline. The model is openly available for research use.
Linear-time Minimum Bayes Risk Decoding with Reference Aggregation
Feb 06, 2024



Minimum Bayes Risk (MBR) decoding is a text generation technique that has been shown to improve the quality of machine translations, but is expensive, even if a sampling-based approximation is used. Besides requiring a large number of sampled sequences, it requires the pairwise calculation of a utility metric, which has quadratic complexity. In this paper, we propose to approximate pairwise metric scores with scores calculated against aggregated reference representations. This changes the complexity of utility estimation from $O(n^2)$ to $O(n)$, while empirically preserving most of the quality gains of MBR decoding. We release our source code at https://github.com/ZurichNLP/mbr
Modular Adaptation of Multilingual Encoders to Written Swiss German Dialect
Jan 25, 2024


Creating neural text encoders for written Swiss German is challenging due to a dearth of training data combined with dialectal variation. In this paper, we build on several existing multilingual encoders and adapt them to Swiss German using continued pre-training. Evaluation on three diverse downstream tasks shows that simply adding a Swiss German adapter to a modular encoder achieves 97.5% of fully monolithic adaptation performance. We further find that for the task of retrieving Swiss German sentences given Standard German queries, adapting a character-level model is more effective than the other adaptation strategies. We release our code and the models trained for our experiments at https://github.com/ZurichNLP/swiss-german-text-encoders
Machine Translation Models are Zero-Shot Detectors of Translation Direction
Jan 12, 2024



Detecting the translation direction of parallel text has applications for machine translation training and evaluation, but also has forensic applications such as resolving plagiarism or forgery allegations. In this work, we explore an unsupervised approach to translation direction detection based on the simple hypothesis that $p(\text{translation}|\text{original})>p(\text{original}|\text{translation})$, motivated by the well-known simplification effect in translationese or machine-translationese. In experiments with massively multilingual machine translation models across 20 translation directions, we confirm the effectiveness of the approach for high-resource language pairs, achieving document-level accuracies of 82-96% for NMT-produced translations, and 60-81% for human translations, depending on the model used. Code and demo are available at https://github.com/ZurichNLP/translation-direction-detection
Trained MT Metrics Learn to Cope with Machine-translated References
Dec 01, 2023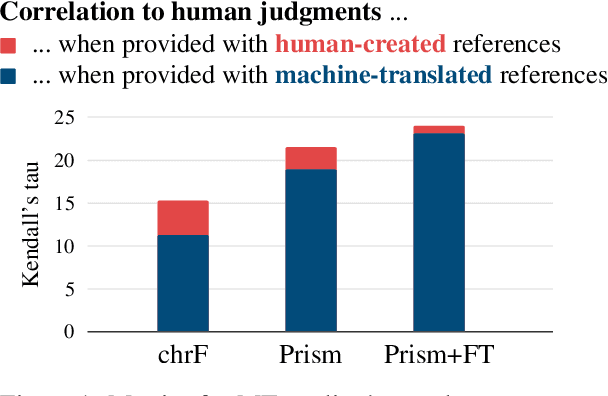



Neural metrics trained on human evaluations of MT tend to correlate well with human judgments, but their behavior is not fully understood. In this paper, we perform a controlled experiment and compare a baseline metric that has not been trained on human evaluations (Prism) to a trained version of the same metric (Prism+FT). Surprisingly, we find that Prism+FT becomes more robust to machine-translated references, which are a notorious problem in MT evaluation. This suggests that the effects of metric training go beyond the intended effect of improving overall correlation with human judgments.
Investigating Multi-Pivot Ensembling with Massively Multilingual Machine Translation Models
Nov 14, 2023
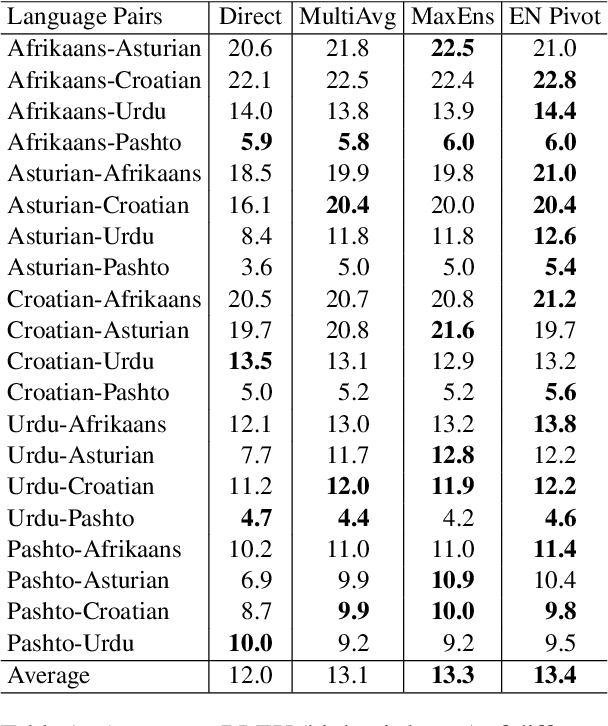


Massively multilingual machine translation models allow for the translation of a large number of languages with a single model, but have limited performance on low- and very-low-resource translation directions. Pivoting via high-resource languages remains a strong strategy for low-resource directions, and in this paper we revisit ways of pivoting through multiple languages. Previous work has used a simple averaging of probability distributions from multiple paths, but we find that this performs worse than using a single pivot, and exacerbates the hallucination problem because the same hallucinations can be probable across different paths. As an alternative, we propose MaxEns, a combination strategy that is biased towards the most confident predictions, hypothesising that confident predictions are less prone to be hallucinations. We evaluate different strategies on the FLORES benchmark for 20 low-resource language directions, demonstrating that MaxEns improves translation quality for low-resource languages while reducing hallucination in translations, compared to both direct translation and an averaging approach. On average, multi-pivot strategies still lag behind using English as a single pivot language, raising the question of how to identify the best pivoting strategy for a given translation direction.