 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Orthographic Variation in Occitan's Dialects
Apr 30, 2024



Effectively normalizing textual data poses a considerable challenge, especially for low-resource languages lacking standardized writing systems. In this study, we fine-tuned a multilingual model with data from several Occitan dialects and conducted a series of experiments to assess the model's representations of these dialects. For evaluation purposes, we compiled a parallel lexicon encompassing four Occitan dialects. Intrinsic evaluations of the model's embeddings revealed that surface similarity between the dialects strengthened representations. When the model was further fine-tuned for part-of-speech tagging and Universal Dependency parsing, its performance was robust to dialectical variation, even when trained solely on part-of-speech data from a single dialect. Our findings suggest that large multilingual models minimize the need for spelling normalization during pre-processing.
Does Whisper understand Swiss German? An automatic, qualitative, and human evaluation
Apr 30, 2024

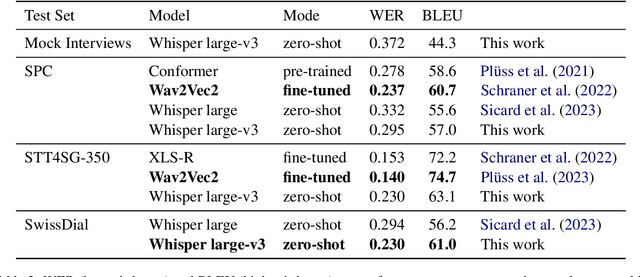
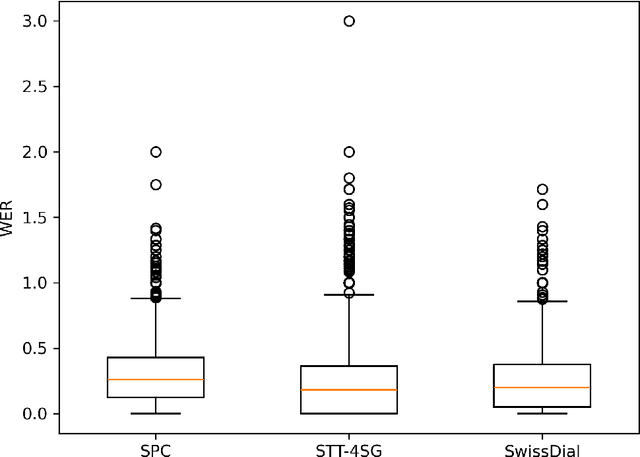
Whisper is a state-of-the-art automatic speech recognition (ASR) model (Radford et al., 2022). Although Swiss German dialects are allegedly not part of Whisper's training data, preliminary experiments showed that Whisper can transcribe Swiss German quite well, with the output being a speech translation into Standard German. To gain a better understanding of Whisper's performance on Swiss German, we systematically evaluate it using automatic, qualitative, and human evaluation. We test its performance on three existing test sets: SwissDial (Dogan-Sch\"onberger et al., 2021), STT4SG-350 (Pl\"uss et al., 2023), and Swiss Parliaments Corpus (Pl\"uss et al., 2021). In addition, we create a new test set for this work, based on short mock clinical interviews. For automatic evaluation, we used word error rate (WER) and BLEU. In the qualitative analysis, we discuss Whisper's strengths and weaknesses and anylyze some output examples. For the human evaluation, we conducted a survey with 28 participants who were asked to evaluate Whisper's performance. All of our evaluations suggest that Whisper is a viable ASR system for Swiss German, so long as the Standard German output is desired.
A Tulu Resource for Machine Translation
Mar 28, 2024



We present the first parallel dataset for English-Tulu translation. Tulu, classified within the South Dravidian linguistic family branch, is predominantly spoken by approximately 2.5 million individuals in southwestern India. Our dataset is constructed by integrating human translations into the multilingual machine translation resource FLORES-200. Furthermore, we use this dataset for evaluation purposes in developing our English-Tulu machine translation model. For the model's training, we leverage resources available for related South Dravidian languages. We adopt a transfer learning approach that exploits similarities between high-resource and low-resource languages. This method enables the training of a machine translation system even in the absence of parallel data between the source and target language, thereby overcoming a significant obstacle in machine translation development for low-resource languages. Our English-Tulu system, trained without using parallel English-Tulu data, outperforms Google Translate by 19 BLEU points (in September 2023). The dataset and code are available here: https://github.com/manunarayanan/Tulu-NMT.
Modular Adaptation of Multilingual Encoders to Written Swiss German Dialect
Jan 25, 2024


Creating neural text encoders for written Swiss German is challenging due to a dearth of training data combined with dialectal variation. In this paper, we build on several existing multilingual encoders and adapt them to Swiss German using continued pre-training. Evaluation on three diverse downstream tasks shows that simply adding a Swiss German adapter to a modular encoder achieves 97.5% of fully monolithic adaptation performance. We further find that for the task of retrieving Swiss German sentences given Standard German queries, adapting a character-level model is more effective than the other adaptation strategies. We release our code and the models trained for our experiments at https://github.com/ZurichNLP/swiss-german-text-encoders
A Benchmark for Evaluating Machine Translation Metrics on Dialects Without Standard Orthography
Nov 28, 2023



For sensible progress in natural language processing, it is important that we are aware of the limitations of the evaluation metrics we use. In this work, we evaluate how robust metrics are to non-standardized dialects, i.e. spelling differences in language varieties that do not have a standard orthography. To investigate this, we collect a dataset of human translations and human judgments for automatic machine translations from English to two Swiss German dialects. We further create a challenge set for dialect variation and benchmark existing metrics' performances. Our results show that existing metrics cannot reliably evaluate Swiss German text generation outputs, especially on segment level. We propose initial design adaptations that increase robustness in the face of non-standardized dialects, although there remains much room for further improvement. The dataset, code, and models are available here: https://github.com/textshuttle/dialect_eval
Findings of the VarDial Evaluation Campaign 2023
May 31, 2023This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2023. The campaign is part of the tenth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with EACL 2023. Three separate shared tasks were included this year: Slot and intent detection for low-resource language varieties (SID4LR), Discriminating Between Similar Languages -- True Labels (DSL-TL), and Discriminating Between Similar Languages -- Speech (DSL-S). All three tasks were organized for the first time this year.
Improving Zero-shot Cross-lingual Transfer between Closely Related Languages by injecting Character-level Noise
Sep 14, 2021



Cross-lingual transfer between a high-resource language and its dialects or closely related language varieties should be facilitated by their similarity, but current approaches that operate in the embedding space do not take surface similarity into account. In this work, we present a simple yet effective strategy to improve cross-lingual transfer between closely related varieties by augmenting the data of the high-resource parent language with character-level noise to make the model more robust towards spelling variations. Our strategy shows consistent improvements over several languages and tasks: Zero-shot transfer of POS tagging and topic identification between language varieties from the Germanic, Uralic, and Romance language genera. Our work provides evidence for the usefulness of simple surface-level noise in improving transfer between language varieties.
On Biasing Transformer Attention Towards Monotonicity
Apr 08, 2021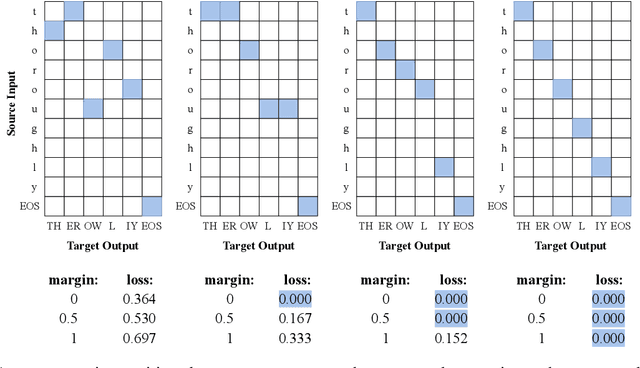
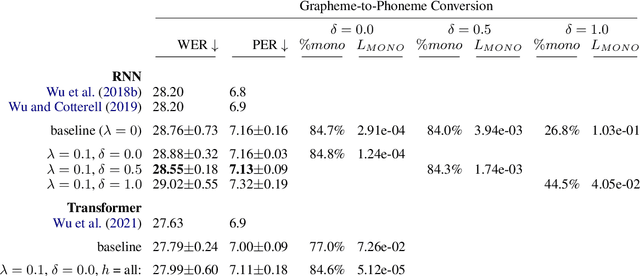

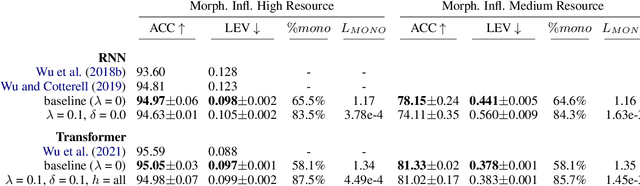
Many sequence-to-sequence tasks in natural language processing are roughly monotonic in the alignment between source and target sequence, and previous work has facilitated or enforced learning of monotonic attention behavior via specialized attention functions or pretraining. In this work, we introduce a monotonicity loss function that is compatible with standard attention mechanisms and test it on several sequence-to-sequence tasks: grapheme-to-phoneme conversion, morphological inflection, transliteration, and dialect normalization. Experiments show that we can achieve largely monotonic behavior. Performance is mixed, with larger gains on top of RNN baselines. General monotonicity does not benefit transformer multihead attention, however, we see isolated improvements when only a subset of heads is biased towards monotonic behavior.