 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGerman also Hallucinates! Inconsistency Detection in News Summaries with the Absinth Dataset
Mar 14, 2024



The advent of Large Language Models (LLMs) has led to remarkable progress on a wide range of natural language processing tasks. Despite the advances, these large-sized models still suffer from hallucinating information in their output, which poses a major issue in automatic text summarization, as we must guarantee that the generated summary is consistent with the content of the source document. Previous research addresses the challenging task of detecting hallucinations in the output (i.e. inconsistency detection) in order to evaluate the faithfulness of the generated summaries. However, these works primarily focus on English and recent multilingual approaches lack German data. This work presents absinth, a manually annotated dataset for hallucination detection in German news summarization and explores the capabilities of novel open-source LLMs on this task in both fine-tuning and in-context learning settings. We open-source and release the absinth dataset to foster further research on hallucination detection in German.
Considerations for meaningful sign language machine translation based on glosses
Nov 28, 2022


Automatic sign language processing is gaining popularity in Natural Language Processing (NLP) research (Yin et al., 2021). In machine translation (MT) in particular, sign language translation based on glosses is a prominent approach. In this paper, we review recent works on neural gloss translation. We find that limitations of glosses in general and limitations of specific datasets are not discussed in a transparent manner and that there is no common standard for evaluation. To address these issues, we put forward concrete recommendations for future research on gloss translation. Our suggestions advocate awareness of the inherent limitations of gloss-based approaches, realistic datasets, stronger baselines and convincing evaluation.
Evaluating the Immediate Applicability of Pose Estimation for Sign Language Recognition
Apr 20, 2021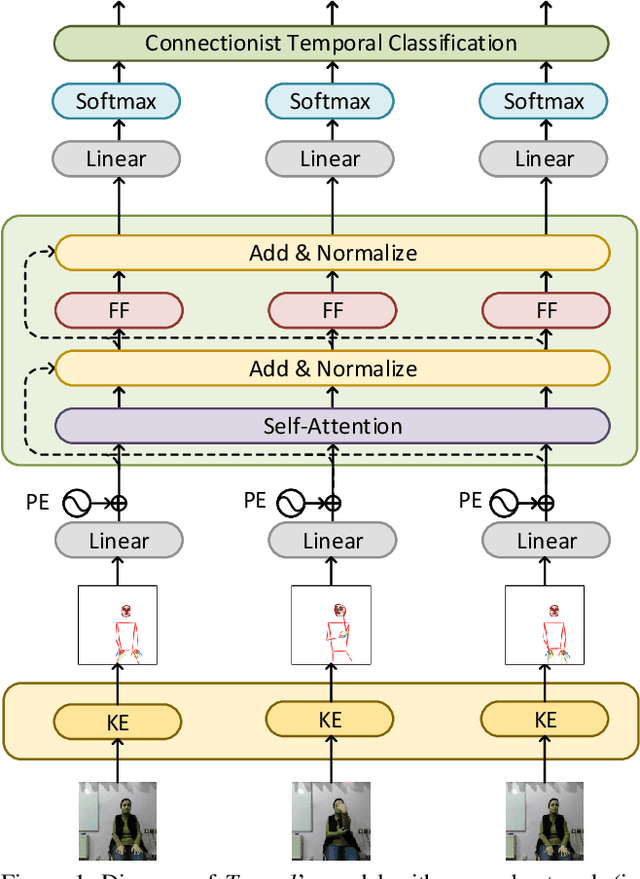
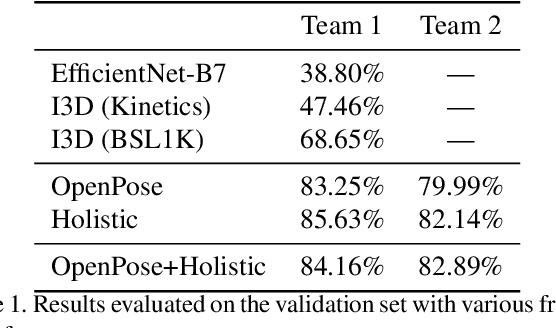
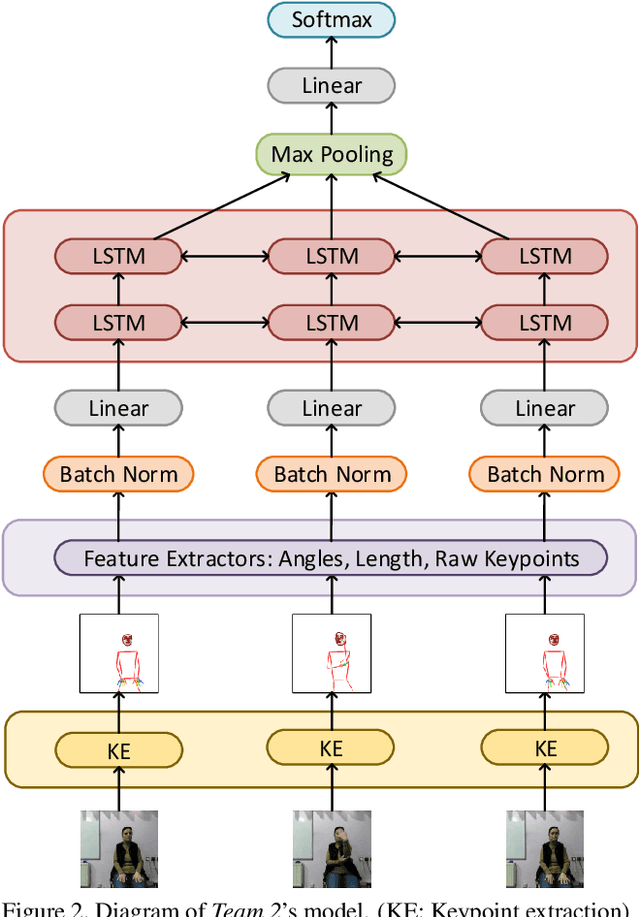
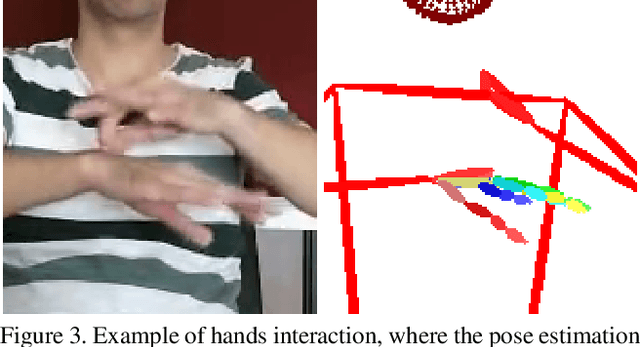
Signed languages are visual languages produced by the movement of the hands, face, and body. In this paper, we evaluate representations based on skeleton poses, as these are explainable, person-independent, privacy-preserving, low-dimensional representations. Basically, skeletal representations generalize over an individual's appearance and background, allowing us to focus on the recognition of motion. But how much information is lost by the skeletal representation? We perform two independent studies using two state-of-the-art pose estimation systems. We analyze the applicability of the pose estimation systems to sign language recognition by evaluating the failure cases of the recognition models. Importantly, this allows us to characterize the current limitations of skeletal pose estimation approaches in sign language recognition.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021
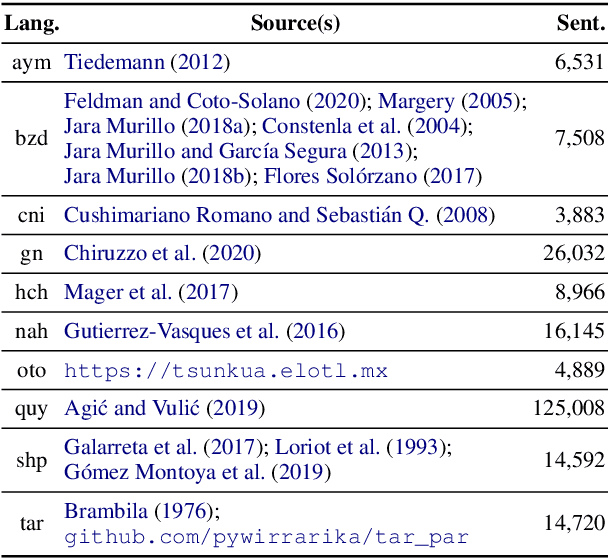
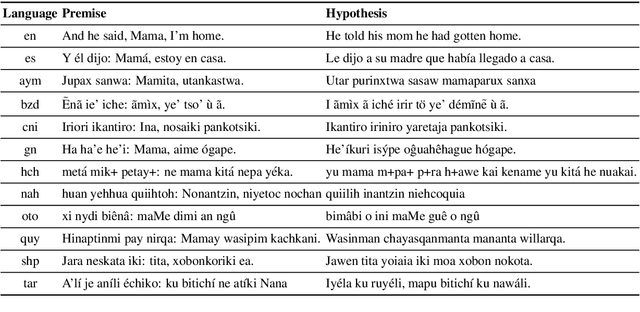

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
On Biasing Transformer Attention Towards Monotonicity
Apr 08, 2021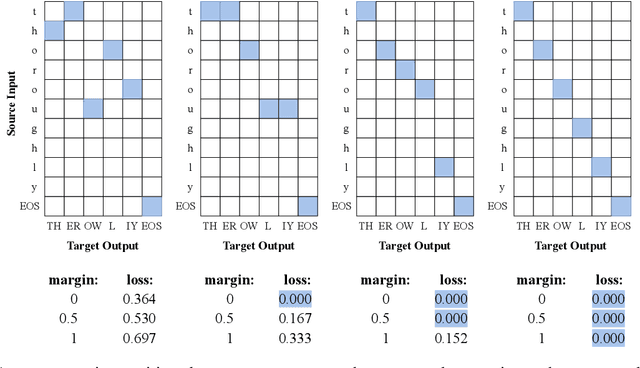
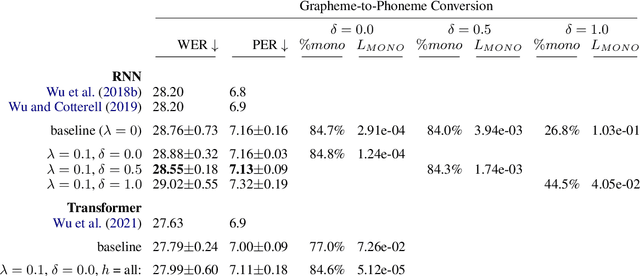

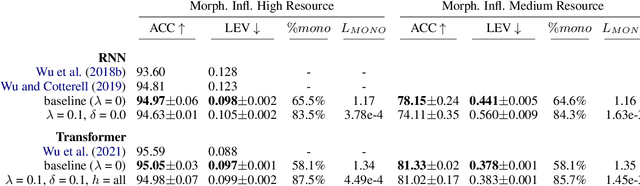
Many sequence-to-sequence tasks in natural language processing are roughly monotonic in the alignment between source and target sequence, and previous work has facilitated or enforced learning of monotonic attention behavior via specialized attention functions or pretraining. In this work, we introduce a monotonicity loss function that is compatible with standard attention mechanisms and test it on several sequence-to-sequence tasks: grapheme-to-phoneme conversion, morphological inflection, transliteration, and dialect normalization. Experiments show that we can achieve largely monotonic behavior. Performance is mixed, with larger gains on top of RNN baselines. General monotonicity does not benefit transformer multihead attention, however, we see isolated improvements when only a subset of heads is biased towards monotonic behavior.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
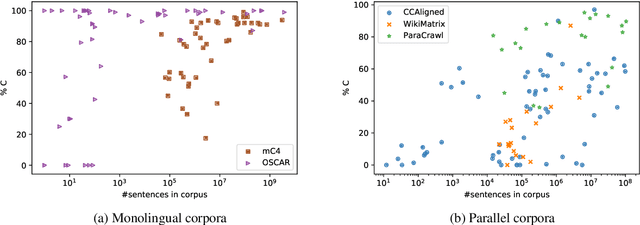

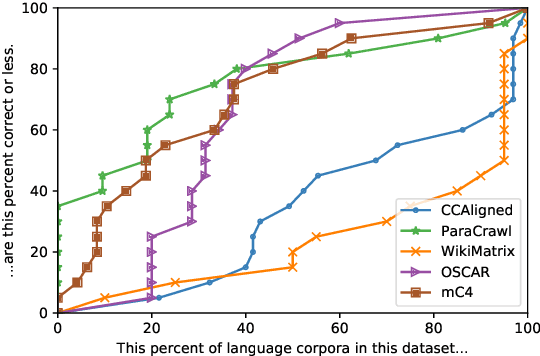
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Subword Segmentation and a Single Bridge Language Affect Zero-Shot Neural Machine Translation
Nov 03, 2020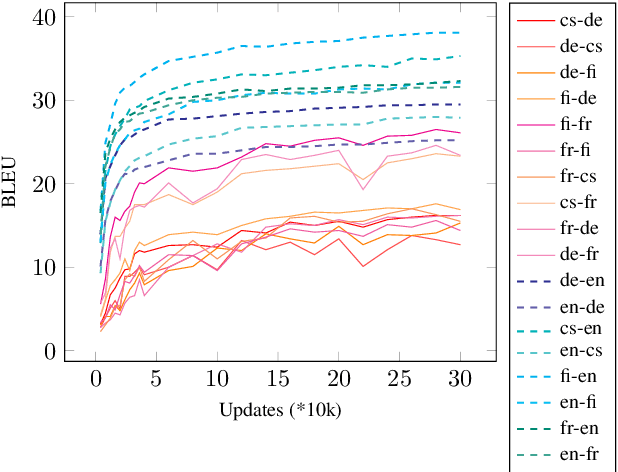
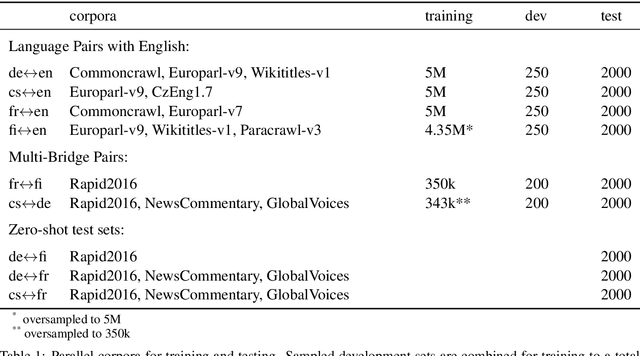
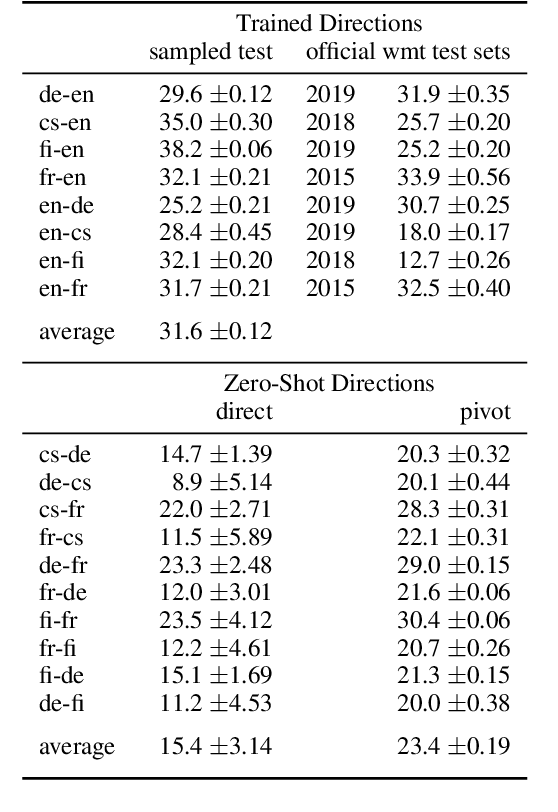
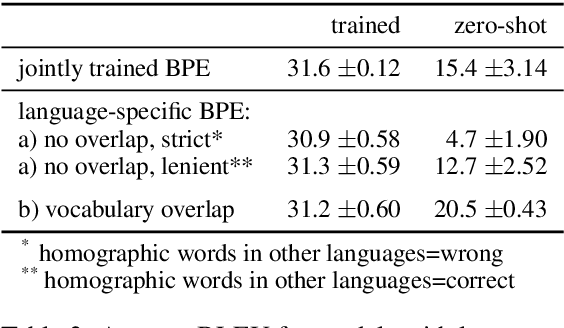
Zero-shot neural machine translation is an attractive goal because of the high cost of obtaining data and building translation systems for new translation directions. However, previous papers have reported mixed success in zero-shot translation. It is hard to predict in which settings it will be effective, and what limits performance compared to a fully supervised system. In this paper, we investigate zero-shot performance of a multilingual EN$\leftrightarrow${FR,CS,DE,FI} system trained on WMT data. We find that zero-shot performance is highly unstable and can vary by more than 6 BLEU between training runs, making it difficult to reliably track improvements. We observe a bias towards copying the source in zero-shot translation, and investigate how the choice of subword segmentation affects this bias. We find that language-specific subword segmentation results in less subword copying at training time, and leads to better zero-shot performance compared to jointly trained segmentation. A recent trend in multilingual models is to not train on parallel data between all language pairs, but have a single bridge language, e.g. English. We find that this negatively affects zero-shot translation and leads to a failure mode where the model ignores the language tag and instead produces English output in zero-shot directions. We show that this bias towards English can be effectively reduced with even a small amount of parallel data in some of the non-English pairs.
Domain Robustness in Neural Machine Translation
Nov 08, 2019
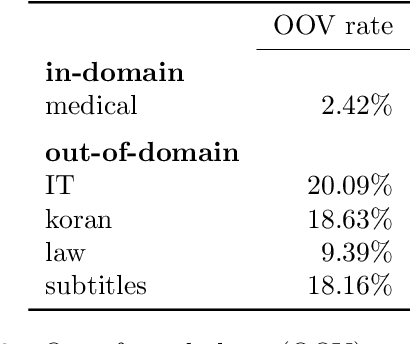
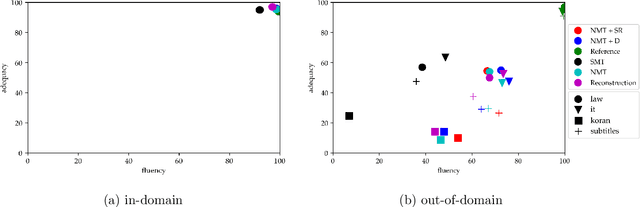

Translating text that diverges from the training domain is a key challenge for neural machine translation (NMT). Domain robustness - the generalization of models to unseen test domains - is low compared to statistical machine translation. In this paper, we investigate the performance of NMT on out-of-domain test sets, and ways to improve it. We observe that hallucination (translations that are fluent but unrelated to the source) is common in out-of-domain settings, and we empirically compare methods that improve adequacy (reconstruction), out-of-domain translation (subword regularization), or robustness against adversarial examples (defensive distillation), as well as noisy channel models. In experiments on German to English OPUS data, and German to Romansh, a low-resource scenario, we find that several methods improve domain robustness, reconstruction standing out as a method that not only improves automatic scores, but also shows improvements in a manual assessments of adequacy, albeit at some loss in fluency. However, out-of-domain performance is still relatively low and domain robustness remains an open problem.
Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures
Aug 28, 2018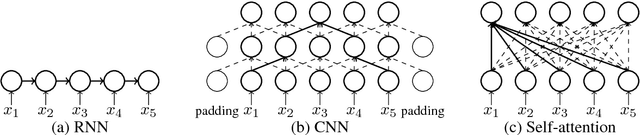
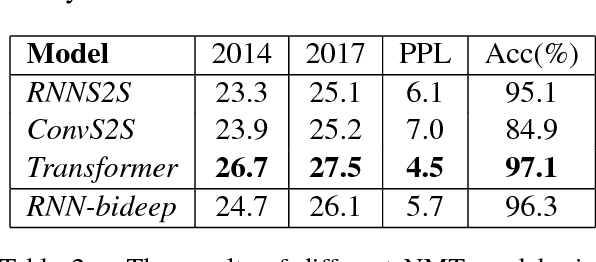
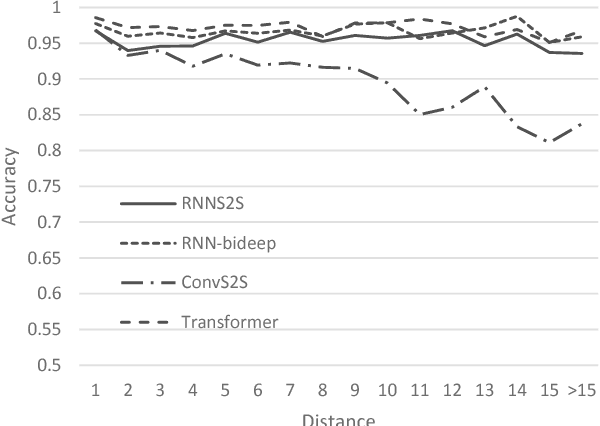

Recently, non-recurrent architectures (convolutional, self-attentional) have outperformed RNNs in neural machine translation. CNNs and self-attentional networks can connect distant words via shorter network paths than RNNs, and it has been speculated that this improves their ability to model long-range dependencies. However, this theoretical argument has not been tested empirically, nor have alternative explanations for their strong performance been explored in-depth. We hypothesize that the strong performance of CNNs and self-attentional networks could also be due to their ability to extract semantic features from the source text, and we evaluate RNNs, CNNs and self-attention networks on two tasks: subject-verb agreement (where capturing long-range dependencies is required) and word sense disambiguation (where semantic feature extraction is required). Our experimental results show that: 1) self-attentional networks and CNNs do not outperform RNNs in modeling subject-verb agreement over long distances; 2) self-attentional networks perform distinctly better than RNNs and CNNs on word sense disambiguation.