 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIlluSign: Illustrating Sign Language Videos by Leveraging the Attention Mechanism
Apr 15, 2025Sign languages are dynamic visual languages that involve hand gestures, in combination with non manual elements such as facial expressions. While video recordings of sign language are commonly used for education and documentation, the dynamic nature of signs can make it challenging to study them in detail, especially for new learners and educators. This work aims to convert sign language video footage into static illustrations, which serve as an additional educational resource to complement video content. This process is usually done by an artist, and is therefore quite costly. We propose a method that illustrates sign language videos by leveraging generative models' ability to understand both the semantic and geometric aspects of images. Our approach focuses on transferring a sketch like illustration style to video footage of sign language, combining the start and end frames of a sign into a single illustration, and using arrows to highlight the hand's direction and motion. While many style transfer methods address domain adaptation at varying levels of abstraction, applying a sketch like style to sign languages, especially for hand gestures and facial expressions, poses a significant challenge. To tackle this, we intervene in the denoising process of a diffusion model, injecting style as keys and values into high resolution attention layers, and fusing geometric information from the image and edges as queries. For the final illustration, we use the attention mechanism to combine the attention weights from both the start and end illustrations, resulting in a soft combination. Our method offers a cost effective solution for generating sign language illustrations at inference time, addressing the lack of such resources in educational materials.
Real-Time Multilingual Sign Language Processing
Dec 02, 2024Sign Language Processing (SLP) is an interdisciplinary field comprised of Natural Language Processing (NLP) and Computer Vision. It is focused on the computational understanding, translation, and production of signed languages. Traditional approaches have often been constrained by the use of gloss-based systems that are both language-specific and inadequate for capturing the multidimensional nature of sign language. These limitations have hindered the development of technology capable of processing signed languages effectively. This thesis aims to revolutionize the field of SLP by proposing a simple paradigm that can bridge this existing technological gap. We propose the use of SignWiring, a universal sign language transcription notation system, to serve as an intermediary link between the visual-gestural modality of signed languages and text-based linguistic representations. We contribute foundational libraries and resources to the SLP community, thereby setting the stage for a more in-depth exploration of the tasks of sign language translation and production. These tasks encompass the translation of sign language from video to spoken language text and vice versa. Through empirical evaluations, we establish the efficacy of our transcription method as a pivot for enabling faster, more targeted research, that can lead to more natural and accurate translations across a range of languages. The universal nature of our transcription-based paradigm also paves the way for real-time, multilingual applications in SLP, thereby offering a more inclusive and accessible approach to language technology. This is a significant step toward universal accessibility, enabling a wider reach of AI-driven language technologies to include the deaf and hard-of-hearing community.
Pose-Based Sign Language Appearance Transfer
Oct 17, 2024
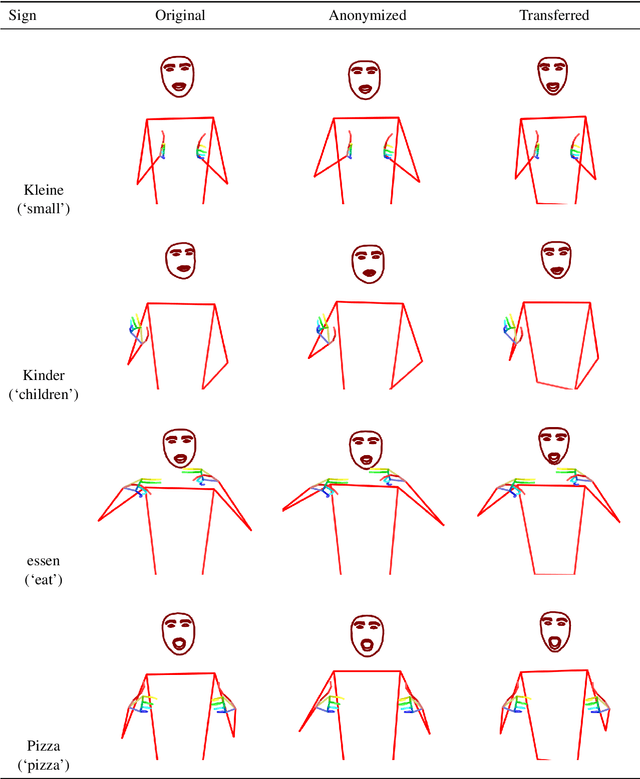

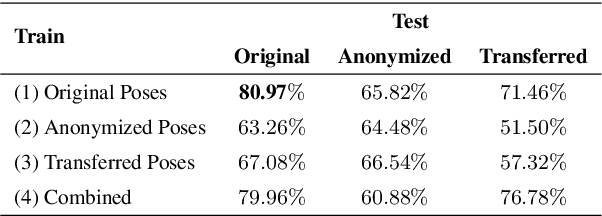
We introduce a method for transferring the signer's appearance in sign language skeletal poses while preserving the sign content. Using estimated poses, we transfer the appearance of one signer to another, maintaining natural movements and transitions. This approach improves pose-based rendering and sign stitching while obfuscating identity. Our experiments show that while the method reduces signer identification accuracy, it slightly harms sign recognition performance, highlighting a tradeoff between privacy and utility. Our code is available at \url{https://github.com/sign-language-processing/pose-anonymization}.
signwriting-evaluation: Effective Sign Language Evaluation via SignWriting
Oct 17, 2024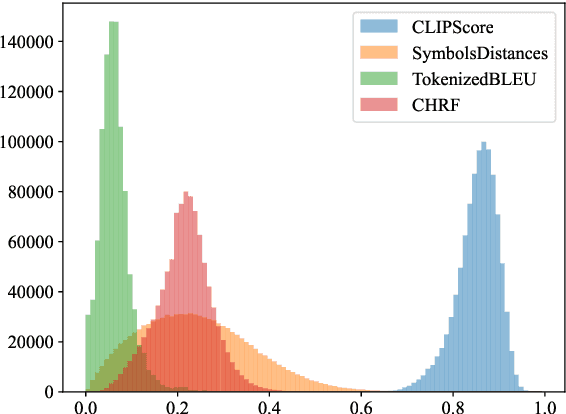
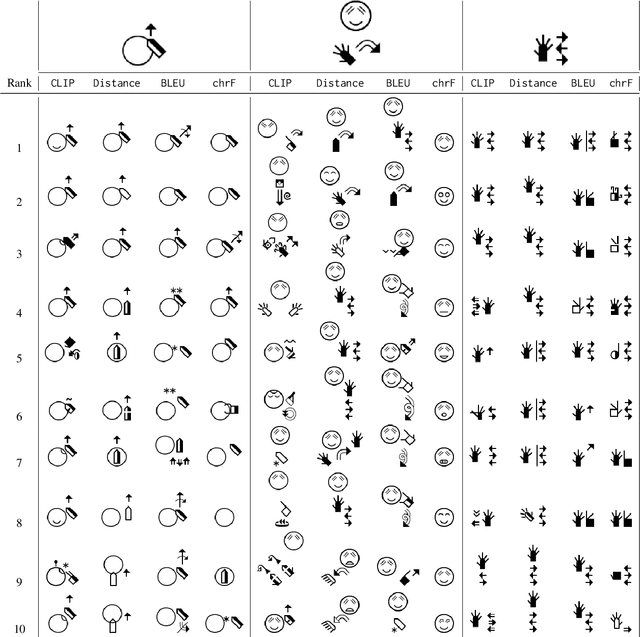
The lack of automatic evaluation metrics tailored for SignWriting presents a significant obstacle in developing effective transcription and translation models for signed languages. This paper introduces a comprehensive suite of evaluation metrics specifically designed for SignWriting, including adaptations of standard metrics such as \texttt{BLEU} and \texttt{chrF}, the application of \texttt{CLIPScore} to SignWriting images, and a novel symbol distance metric unique to our approach. We address the distinct challenges of evaluating single signs versus continuous signing and provide qualitative demonstrations of metric efficacy through score distribution analyses and nearest-neighbor searches within the SignBank corpus. Our findings reveal the strengths and limitations of each metric, offering valuable insights for future advancements using SignWriting. This work contributes essential tools for evaluating SignWriting models, facilitating progress in the field of sign language processing. Our code is available at \url{https://github.com/sign-language-processing/signwriting-evaluation}.
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024

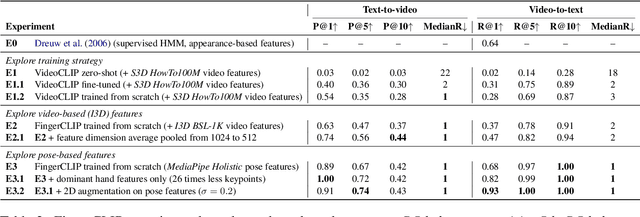

We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
Optimizing Hand Region Detection in MediaPipe Holistic Full-Body Pose Estimation to Improve Accuracy and Avoid Downstream Errors
May 06, 2024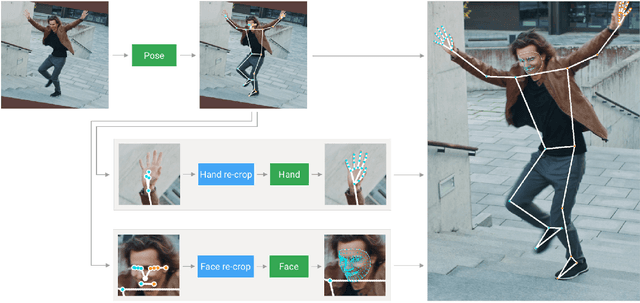

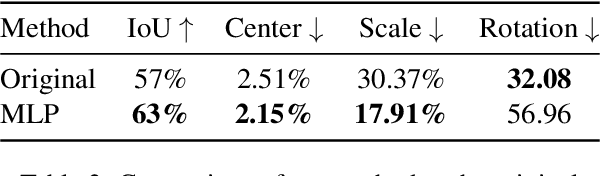
This paper addresses a critical flaw in MediaPipe Holistic's hand Region of Interest (ROI) prediction, which struggles with non-ideal hand orientations, affecting sign language recognition accuracy. We propose a data-driven approach to enhance ROI estimation, leveraging an enriched feature set including additional hand keypoints and the z-dimension. Our results demonstrate better estimates, with higher Intersection-over-Union compared to the current method. Our code and optimizations are available at https://github.com/sign-language-processing/mediapipe-hand-crop-fix.
Linguistically Motivated Sign Language Segmentation
Oct 30, 2023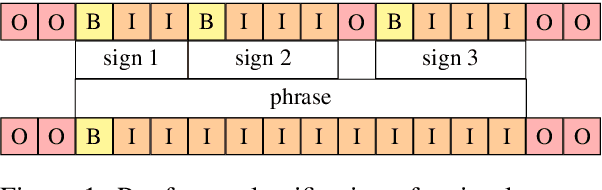



Sign language segmentation is a crucial task in sign language processing systems. It enables downstream tasks such as sign recognition, transcription, and machine translation. In this work, we consider two kinds of segmentation: segmentation into individual signs and segmentation into phrases, larger units comprising several signs. We propose a novel approach to jointly model these two tasks. Our method is motivated by linguistic cues observed in sign language corpora. We replace the predominant IO tagging scheme with BIO tagging to account for continuous signing. Given that prosody plays a significant role in phrase boundaries, we explore the use of optical flow features. We also provide an extensive analysis of hand shapes and 3D hand normalization. We find that introducing BIO tagging is necessary to model sign boundaries. Explicitly encoding prosody by optical flow improves segmentation in shallow models, but its contribution is negligible in deeper models. Careful tuning of the decoding algorithm atop the models further improves the segmentation quality. We demonstrate that our final models generalize to out-of-domain video content in a different signed language, even under a zero-shot setting. We observe that including optical flow and 3D hand normalization enhances the robustness of the model in this context.
pose-format: Library for Viewing, Augmenting, and Handling .pose Files
Oct 13, 2023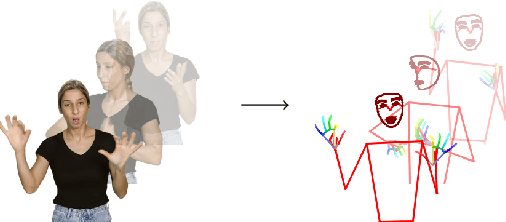

Managing and analyzing pose data is a complex task, with challenges ranging from handling diverse file structures and data types to facilitating effective data manipulations such as normalization and augmentation. This paper presents \texttt{pose-format}, a comprehensive toolkit designed to address these challenges by providing a unified, flexible, and easy-to-use interface. The library includes a specialized file format that encapsulates various types of pose data, accommodating multiple individuals and an indefinite number of time frames, thus proving its utility for both image and video data. Furthermore, it offers seamless integration with popular numerical libraries such as NumPy, PyTorch, and TensorFlow, thereby enabling robust machine-learning applications. Through benchmarking, we demonstrate that our \texttt{.pose} file format offers vastly superior performance against prevalent formats like OpenPose, with added advantages like self-contained pose specification. Additionally, the library includes features for data normalization, augmentation, and easy-to-use visualization capabilities, both in Python and Browser environments. \texttt{pose-format} emerges as a one-stop solution, streamlining the complexities of pose data management and analysis.
sign.mt: Real-Time Multilingual Sign Language Translation Application
Oct 08, 2023



This demo paper presents sign.mt, an open-source application pioneering real-time multilingual bi-directional translation between spoken and signed languages. Harnessing state-of-the-art open-source models, this tool aims to address the communication divide between the hearing and the deaf, facilitating seamless translation in both spoken-to-signed and signed-to-spoken translation directions. Promising reliable and unrestricted communication, sign.mt offers offline functionality, crucial in areas with limited internet connectivity. It further enhances user engagement by offering customizable photo-realistic sign language avatars, thereby encouraging a more personalized and authentic user experience. Licensed under CC BY-NC-SA 4.0, sign.mt signifies an important stride towards open, inclusive communication. The app can be used, and modified for personal and academic uses, and even supports a translation API, fostering integration into a wider range of applications. However, it is by no means a finished product. We invite the NLP community to contribute towards the evolution of sign.mt. Whether it be the integration of more refined models, the development of innovative pipelines, or user experience improvements, your contributions can propel this project to new heights. Available at https://sign.mt, it stands as a testament to what we can achieve together, as we strive to make communication accessible to all.
SignBank+: Multilingual Sign Language Translation Dataset
Sep 20, 2023
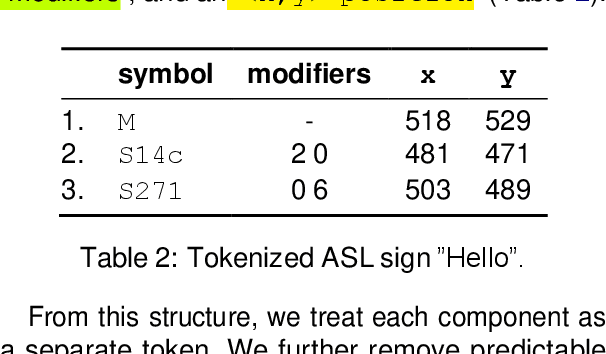


This work advances the field of sign language machine translation by focusing on dataset quality and simplification of the translation system. We introduce SignBank+, a clean version of the SignBank dataset, optimized for machine translation. Contrary to previous works that employ complex factorization techniques for translation, we advocate for a simplified text-to-text translation approach. Our evaluation shows that models trained on SignBank+ surpass those on the original dataset, establishing a new benchmark and providing an open resource for future research.