 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Lost in Translation, Found in Embeddings: Sign Language Translation and Alignment
Dec 08, 2025

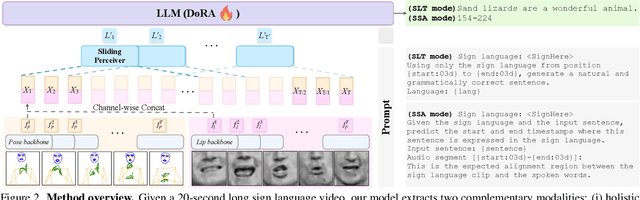
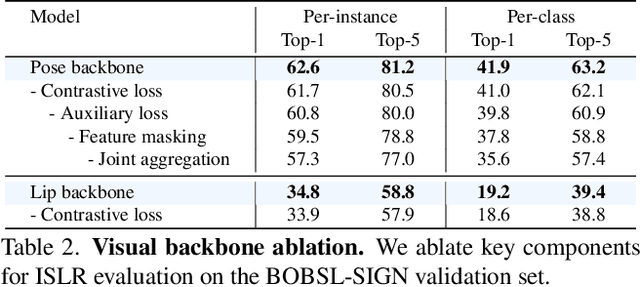
Our aim is to develop a unified model for sign language understanding, that performs sign language translation (SLT) and sign-subtitle alignment (SSA). Together, these two tasks enable the conversion of continuous signing videos into spoken language text and also the temporal alignment of signing with subtitles -- both essential for practical communication, large-scale corpus construction, and educational applications. To achieve this, our approach is built upon three components: (i) a lightweight visual backbone that captures manual and non-manual cues from human keypoints and lip-region images while preserving signer privacy; (ii) a Sliding Perceiver mapping network that aggregates consecutive visual features into word-level embeddings to bridge the vision-text gap; and (iii) a multi-task scalable training strategy that jointly optimises SLT and SSA, reinforcing both linguistic and temporal alignment. To promote cross-linguistic generalisation, we pretrain our model on large-scale sign-text corpora covering British Sign Language (BSL) and American Sign Language (ASL) from the BOBSL and YouTube-SL-25 datasets. With this multilingual pretraining and strong model design, we achieve state-of-the-art results on the challenging BOBSL (BSL) dataset for both SLT and SSA. Our model also demonstrates robust zero-shot generalisation and finetuned SLT performance on How2Sign (ASL), highlighting the potential of scalable translation across different sign languages.
Detecting Cognitive Impairment and Psychological Well-being among Older Adults Using Facial, Acoustic, Linguistic, and Cardiovascular Patterns Derived from Remote Conversations
Dec 23, 2024



The aging society urgently requires scalable methods to monitor cognitive decline and identify social and psychological factors indicative of dementia risk in older adults. Our machine learning (ML) models captured facial, acoustic, linguistic, and cardiovascular features from 39 individuals with normal cognition or Mild Cognitive Impairment derived from remote video conversations and classified cognitive status, social isolation, neuroticism, and psychological well-being. Our model could distinguish Clinical Dementia Rating Scale (CDR) of 0.5 (vs. 0) with 0.78 area under the receiver operating characteristic curve (AUC), social isolation with 0.75 AUC, neuroticism with 0.71 AUC, and negative affect scales with 0.79 AUC. Recent advances in machine learning offer new opportunities to remotely detect cognitive impairment and assess associated factors, such as neuroticism and psychological well-being. Our experiment showed that speech and language patterns were more useful for quantifying cognitive impairment, whereas facial expression and cardiovascular patterns using photoplethysmography (PPG) were more useful for quantifying personality and psychological well-being.
Pose-Based Sign Language Appearance Transfer
Oct 17, 2024
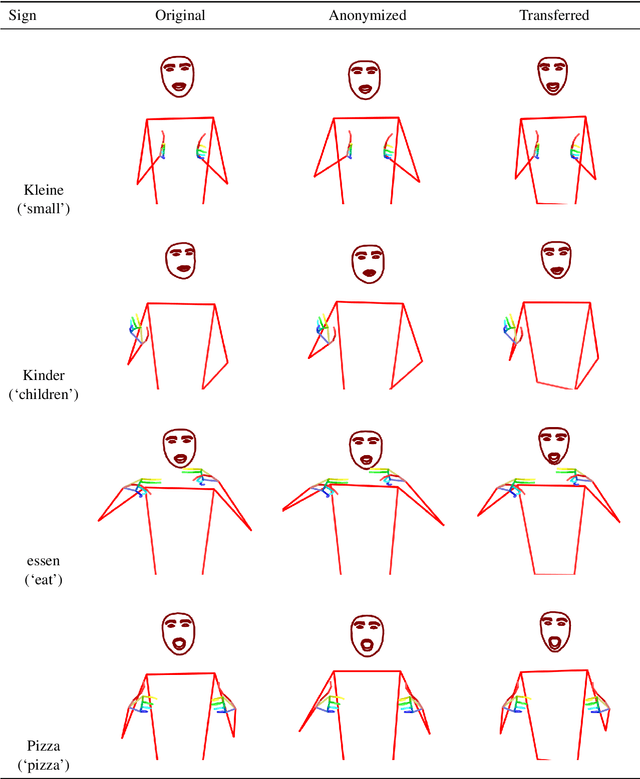

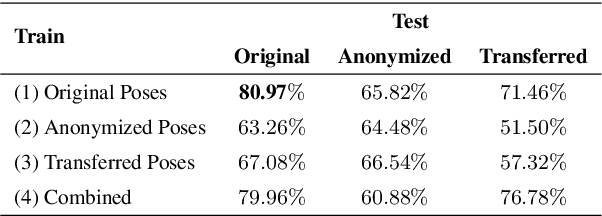
We introduce a method for transferring the signer's appearance in sign language skeletal poses while preserving the sign content. Using estimated poses, we transfer the appearance of one signer to another, maintaining natural movements and transitions. This approach improves pose-based rendering and sign stitching while obfuscating identity. Our experiments show that while the method reduces signer identification accuracy, it slightly harms sign recognition performance, highlighting a tradeoff between privacy and utility. Our code is available at \url{https://github.com/sign-language-processing/pose-anonymization}.
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024

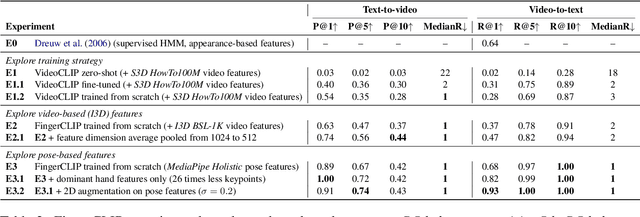

We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
Linguistically Motivated Sign Language Segmentation
Oct 30, 2023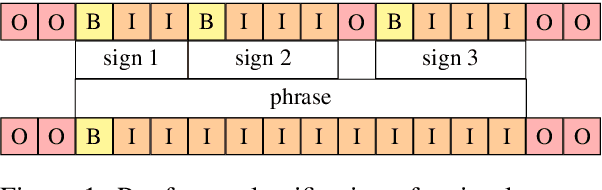



Sign language segmentation is a crucial task in sign language processing systems. It enables downstream tasks such as sign recognition, transcription, and machine translation. In this work, we consider two kinds of segmentation: segmentation into individual signs and segmentation into phrases, larger units comprising several signs. We propose a novel approach to jointly model these two tasks. Our method is motivated by linguistic cues observed in sign language corpora. We replace the predominant IO tagging scheme with BIO tagging to account for continuous signing. Given that prosody plays a significant role in phrase boundaries, we explore the use of optical flow features. We also provide an extensive analysis of hand shapes and 3D hand normalization. We find that introducing BIO tagging is necessary to model sign boundaries. Explicitly encoding prosody by optical flow improves segmentation in shallow models, but its contribution is negligible in deeper models. Careful tuning of the decoding algorithm atop the models further improves the segmentation quality. We demonstrate that our final models generalize to out-of-domain video content in a different signed language, even under a zero-shot setting. We observe that including optical flow and 3D hand normalization enhances the robustness of the model in this context.
SignBank+: Multilingual Sign Language Translation Dataset
Sep 20, 2023
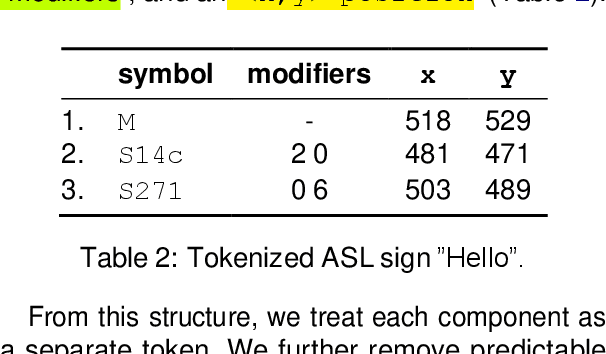


This work advances the field of sign language machine translation by focusing on dataset quality and simplification of the translation system. We introduce SignBank+, a clean version of the SignBank dataset, optimized for machine translation. Contrary to previous works that employ complex factorization techniques for translation, we advocate for a simplified text-to-text translation approach. Our evaluation shows that models trained on SignBank+ surpass those on the original dataset, establishing a new benchmark and providing an open resource for future research.
An Open-Source Gloss-Based Baseline for Spoken to Signed Language Translation
May 28, 2023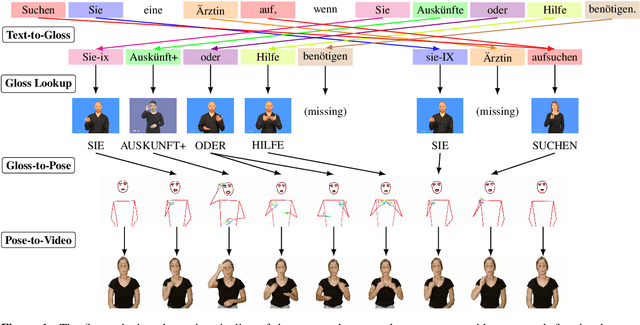


Sign language translation systems are complex and require many components. As a result, it is very hard to compare methods across publications. We present an open-source implementation of a text-to-gloss-to-pose-to-video pipeline approach, demonstrating conversion from German to Swiss German Sign Language, French to French Sign Language of Switzerland, and Italian to Italian Sign Language of Switzerland. We propose three different components for the text-to-gloss translation: a lemmatizer, a rule-based word reordering and dropping component, and a neural machine translation system. Gloss-to-pose conversion occurs using data from a lexicon for three different signed languages, with skeletal poses extracted from videos. To generate a sentence, the text-to-gloss system is first run, and the pose representations of the resulting signs are stitched together.
Automatic Sound Event Detection and Classification of Great Ape Calls Using Neural Networks
Jan 05, 2023
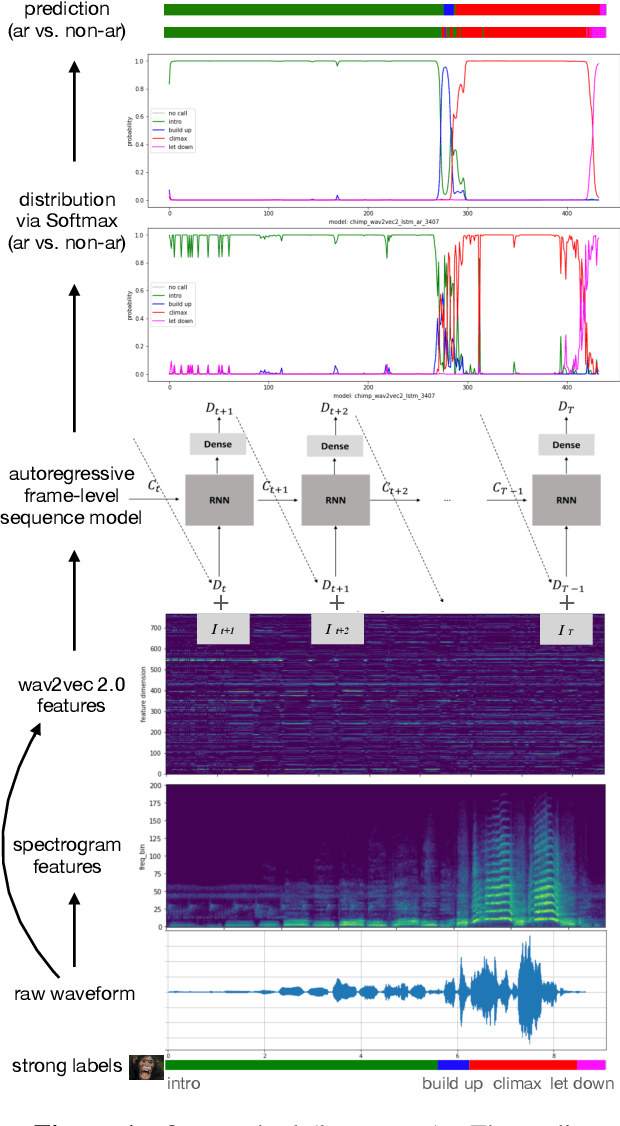
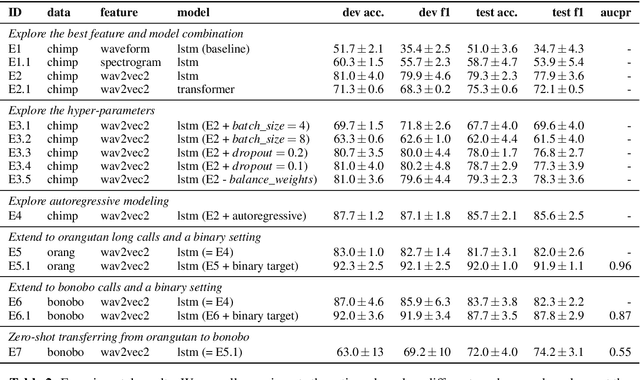
We present a novel approach to automatically detect and classify great ape calls from continuous raw audio recordings collected during field research. Our method leverages deep pretrained and sequential neural networks, including wav2vec 2.0 and LSTM, and is validated on three data sets from three different great ape lineages (orangutans, chimpanzees, and bonobos). The recordings were collected by different researchers and include different annotation schemes, which our pipeline preprocesses and trains in a uniform fashion. Our results for call detection and classification attain high accuracy. Our method is aimed to be generalizable to other animal species, and more generally, sound event detection tasks. To foster future research, we make our pipeline and methods publicly available.
Considerations for meaningful sign language machine translation based on glosses
Nov 28, 2022
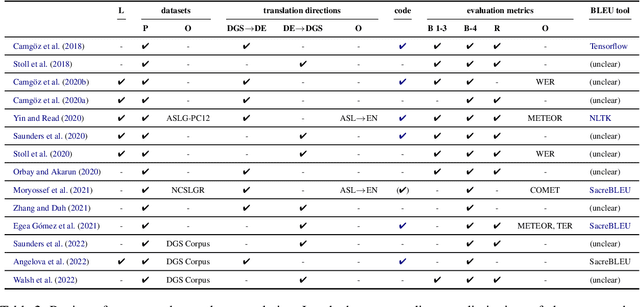


Automatic sign language processing is gaining popularity in Natural Language Processing (NLP) research (Yin et al., 2021). In machine translation (MT) in particular, sign language translation based on glosses is a prominent approach. In this paper, we review recent works on neural gloss translation. We find that limitations of glosses in general and limitations of specific datasets are not discussed in a transparent manner and that there is no common standard for evaluation. To address these issues, we put forward concrete recommendations for future research on gloss translation. Our suggestions advocate awareness of the inherent limitations of gloss-based approaches, realistic datasets, stronger baselines and convincing evaluation.