 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Crowdsourced Audio for Text-to-Speech Models
Oct 17, 2024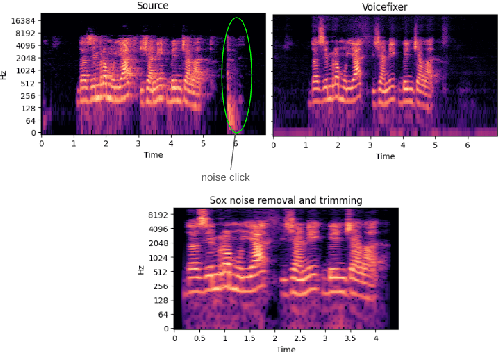
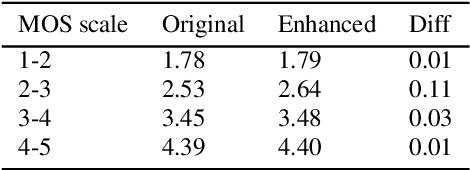
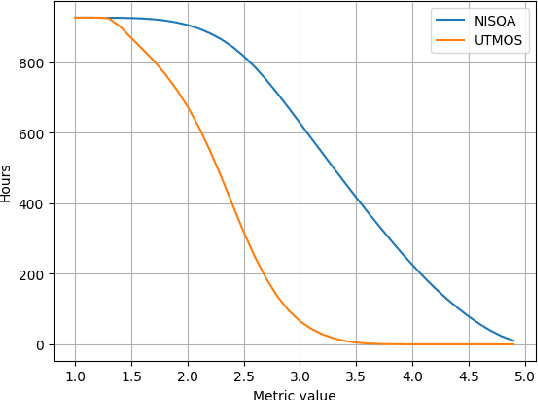

High-quality audio data is a critical prerequisite for training robust text-to-speech models, which often limits the use of opportunistic or crowdsourced datasets. This paper presents an approach to overcome this limitation by implementing a denoising pipeline on the Catalan subset of Commonvoice, a crowd-sourced corpus known for its inherent noise and variability. The pipeline incorporates an audio enhancement phase followed by a selective filtering strategy. We developed an automatic filtering mechanism leveraging Non-Intrusive Speech Quality Assessment (NISQA) models to identify and retain the highest quality samples post-enhancement. To evaluate the efficacy of this approach, we trained a state of the art diffusion-based TTS model on the processed dataset. The results show a significant improvement, with an increase of 0.4 in the UTMOS Score compared to the baseline dataset without enhancement. This methodology shows promise for expanding the utility of crowdsourced data in TTS applications, particularly for mid to low resource languages like Catalan.
Pose-Based Sign Language Appearance Transfer
Oct 17, 2024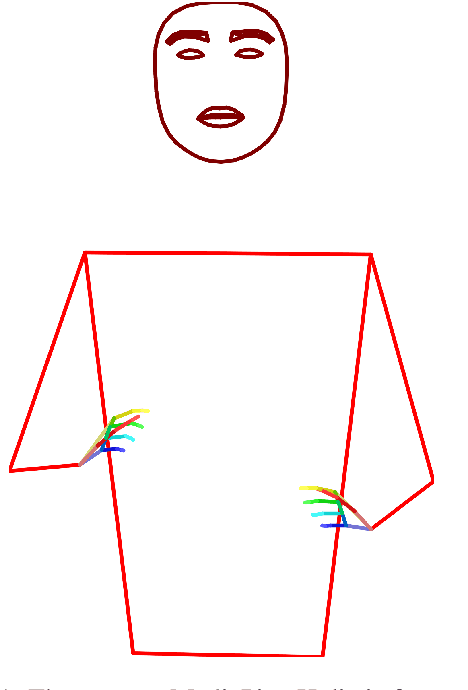
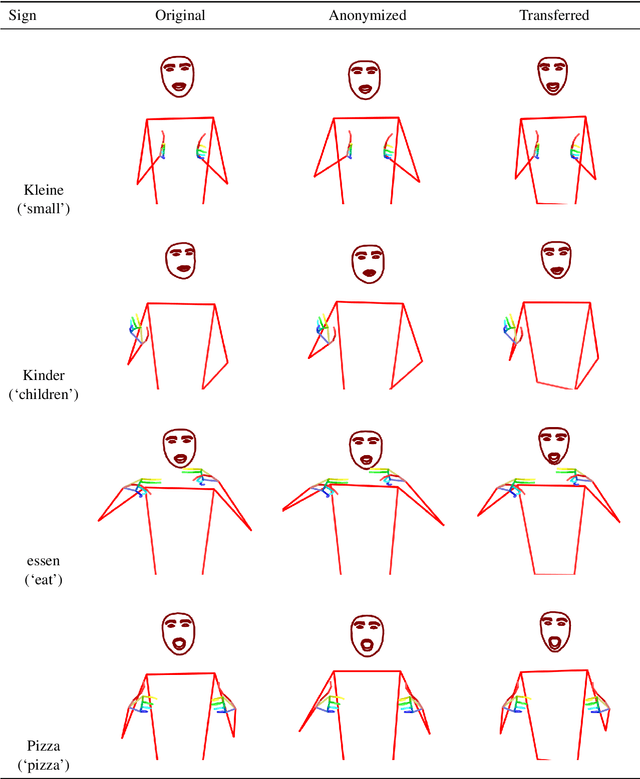

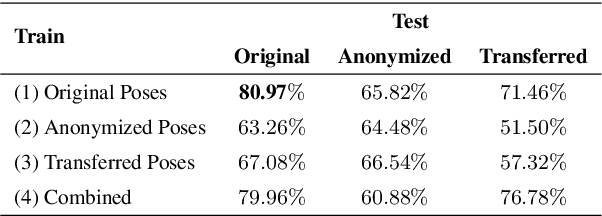
We introduce a method for transferring the signer's appearance in sign language skeletal poses while preserving the sign content. Using estimated poses, we transfer the appearance of one signer to another, maintaining natural movements and transitions. This approach improves pose-based rendering and sign stitching while obfuscating identity. Our experiments show that while the method reduces signer identification accuracy, it slightly harms sign recognition performance, highlighting a tradeoff between privacy and utility. Our code is available at \url{https://github.com/sign-language-processing/pose-anonymization}.
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024

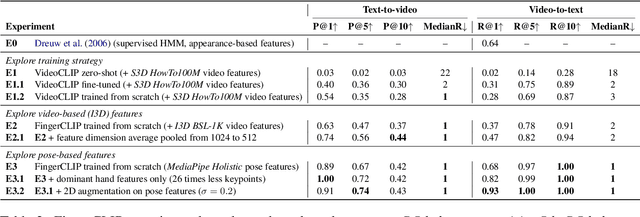

We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
Multiformer: A Head-Configurable Transformer-Based Model for Direct Speech Translation
May 14, 2022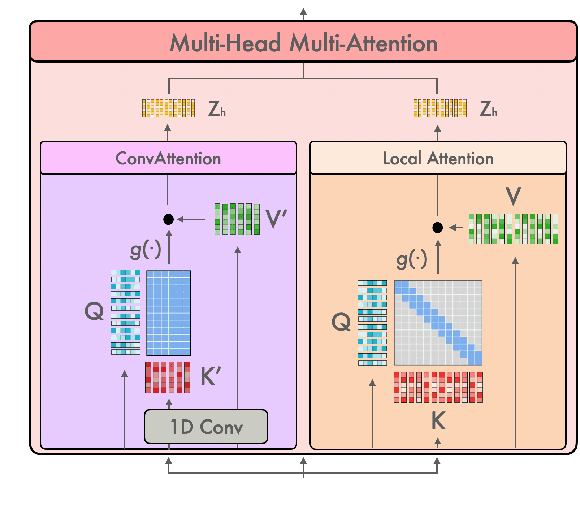
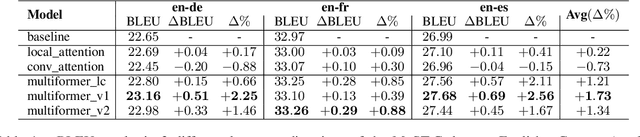
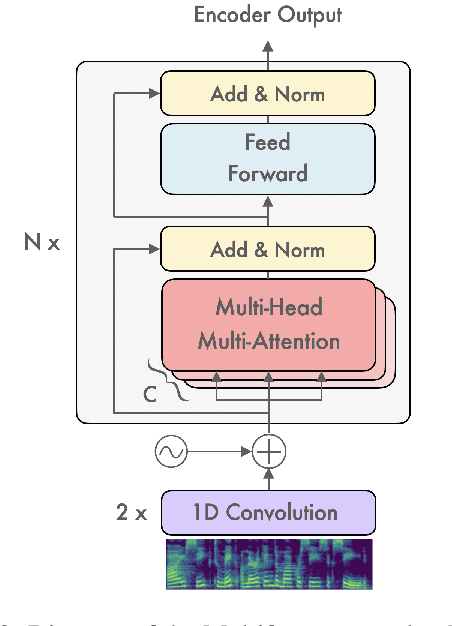
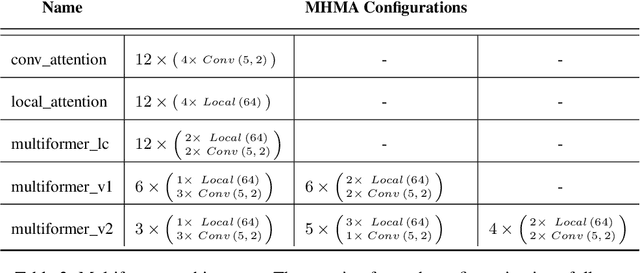
Transformer-based models have been achieving state-of-the-art results in several fields of Natural Language Processing. However, its direct application to speech tasks is not trivial. The nature of this sequences carries problems such as long sequence lengths and redundancy between adjacent tokens. Therefore, we believe that regular self-attention mechanism might not be well suited for it. Different approaches have been proposed to overcome these problems, such as the use of efficient attention mechanisms. However, the use of these methods usually comes with a cost, which is a performance reduction caused by information loss. In this study, we present the Multiformer, a Transformer-based model which allows the use of different attention mechanisms on each head. By doing this, the model is able to bias the self-attention towards the extraction of more diverse token interactions, and the information loss is reduced. Finally, we perform an analysis of the head contributions, and we observe that those architectures where all heads relevance is uniformly distributed obtain better results. Our results show that mixing attention patterns along the different heads and layers outperforms our baseline by up to 0.7 BLEU.