 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot TTS With Enhanced Audio Prompts: Bsc Submission For The 2026 Wildspoof Challenge TTS Track
Feb 05, 2026We evaluate two non-autoregressive architectures, StyleTTS2 and F5-TTS, to address the spontaneous nature of in-the-wild speech. Our models utilize flexible duration modeling to improve prosodic naturalness. To handle acoustic noise, we implement a multi-stage enhancement pipeline using the Sidon model, which significantly outperforms standard Demucs in signal quality. Experimental results show that finetuning enhanced audios yields superior robustness, achieving up to 4.21 UTMOS and 3.47 DNSMOS. Furthermore, we analyze the impact of reference prompt quality and length on zero-shot synthesis performance, demonstrating the effectiveness of our approach for realistic speech generation.
Enhancing Crowdsourced Audio for Text-to-Speech Models
Oct 17, 2024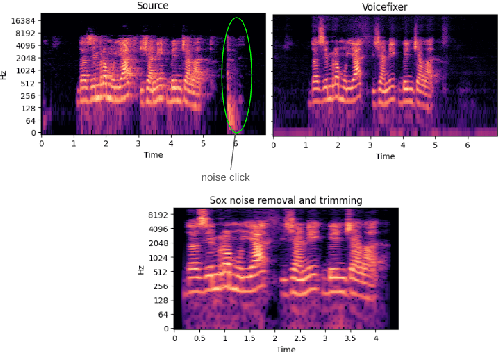
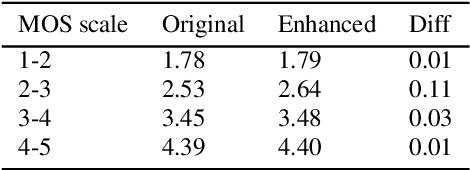
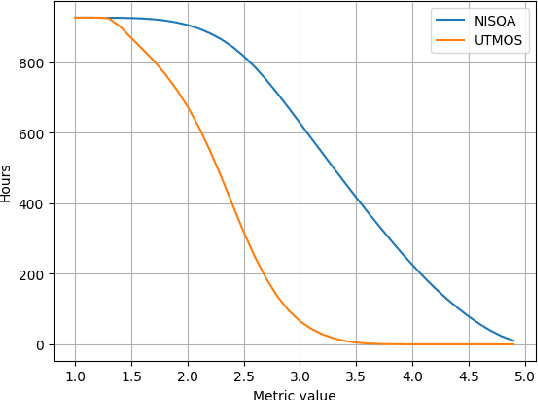

High-quality audio data is a critical prerequisite for training robust text-to-speech models, which often limits the use of opportunistic or crowdsourced datasets. This paper presents an approach to overcome this limitation by implementing a denoising pipeline on the Catalan subset of Commonvoice, a crowd-sourced corpus known for its inherent noise and variability. The pipeline incorporates an audio enhancement phase followed by a selective filtering strategy. We developed an automatic filtering mechanism leveraging Non-Intrusive Speech Quality Assessment (NISQA) models to identify and retain the highest quality samples post-enhancement. To evaluate the efficacy of this approach, we trained a state of the art diffusion-based TTS model on the processed dataset. The results show a significant improvement, with an increase of 0.4 in the UTMOS Score compared to the baseline dataset without enhancement. This methodology shows promise for expanding the utility of crowdsourced data in TTS applications, particularly for mid to low resource languages like Catalan.
English Accent Accuracy Analysis in a State-of-the-Art Automatic Speech Recognition System
May 09, 2021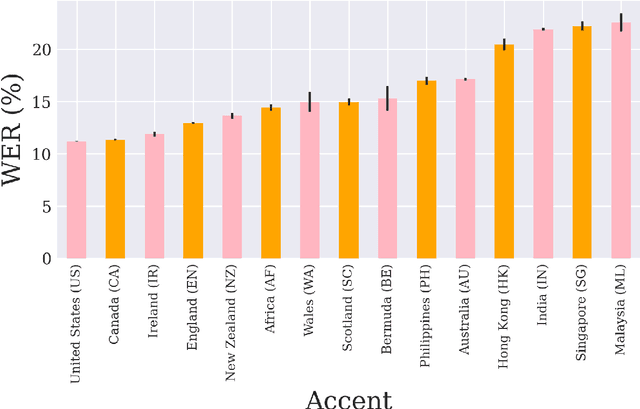

Nowadays, research in speech technologies has gotten a lot out thanks to recently created public domain corpora that contain thousands of recording hours. These large amounts of data are very helpful for training the new complex models based on deep learning technologies. However, the lack of dialectal diversity in a corpus is known to cause performance biases in speech systems, mainly for underrepresented dialects. In this work, we propose to evaluate a state-of-the-art automatic speech recognition (ASR) deep learning-based model, using unseen data from a corpus with a wide variety of labeled English accents from different countries around the world. The model has been trained with 44.5K hours of English speech from an open access corpus called Multilingual LibriSpeech, showing remarkable results in popular benchmarks. We test the accuracy of such ASR against samples extracted from another public corpus that is continuously growing, the Common Voice dataset. Then, we present graphically the accuracy in terms of Word Error Rate of each of the different English included accents, showing that there is indeed an accuracy bias in terms of accentual variety, favoring the accents most prevalent in the training corpus.