 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Variational Estimation via Monte Carlo Sampling
Feb 06, 2026This article addresses online variational estimation in parametric state-space models. We propose a new procedure for efficiently computing the evidence lower bound and its gradient in a streaming-data setting, where observations arrive sequentially. The algorithm allows for the simultaneous training of the model parameters and the distribution of the latent states given the observations. It is based on i.i.d. Monte Carlo sampling, coupled with a well-chosen deep architecture, enabling both computational efficiency and flexibility. The performance of the method is illustrated on both synthetic data and real-world air-quality data. The proposed approach is theoretically motivated by the existence of an asymptotic contrast function and the ergodicity of the underlying Markov chain, and applies more generally to the computation of additive expectations under posterior distributions in state-space models.
Recursive Learning of Asymptotic Variational Objectives
Nov 04, 2024

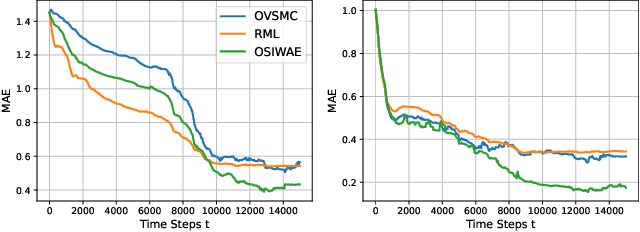
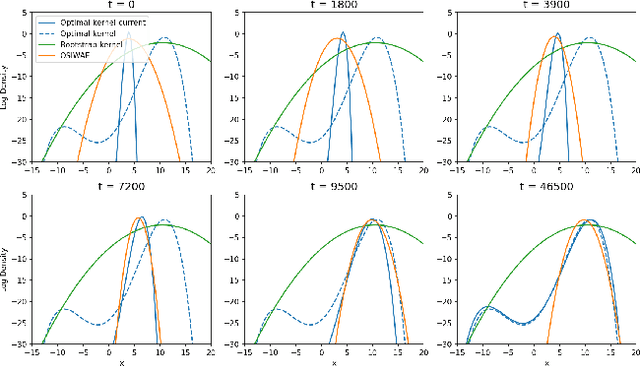
General state-space models (SSMs) are widely used in statistical machine learning and are among the most classical generative models for sequential time-series data. SSMs, comprising latent Markovian states, can be subjected to variational inference (VI), but standard VI methods like the importance-weighted autoencoder (IWAE) lack functionality for streaming data. To enable online VI in SSMs when the observations are received in real time, we propose maximising an IWAE-type variational lower bound on the asymptotic contrast function, rather than the standard IWAE ELBO, using stochastic approximation. Unlike the recursive maximum likelihood method, which directly maximises the asymptotic contrast, our approach, called online sequential IWAE (OSIWAE), allows for online learning of both model parameters and a Markovian recognition model for inferring latent states. By approximating filter state posteriors and their derivatives using sequential Monte Carlo (SMC) methods, we create a particle-based framework for online VI in SSMs. This approach is more theoretically well-founded than recently proposed online variational SMC methods. We provide rigorous theoretical results on the learning objective and a numerical study demonstrating the method's efficiency in learning model parameters and particle proposal kernels.
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024

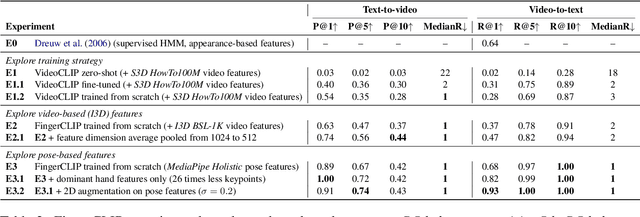

We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
JWSign: A Highly Multilingual Corpus of Bible Translations for more Diversity in Sign Language Processing
Nov 16, 2023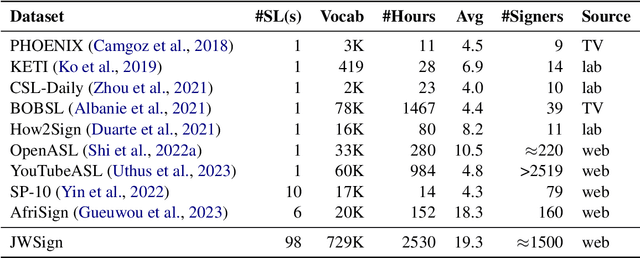

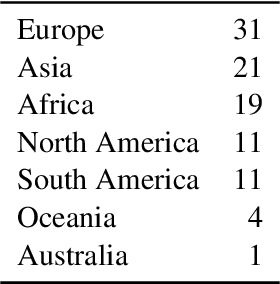

Advancements in sign language processing have been hindered by a lack of sufficient data, impeding progress in recognition, translation, and production tasks. The absence of comprehensive sign language datasets across the world's sign languages has widened the gap in this field, resulting in a few sign languages being studied more than others, making this research area extremely skewed mostly towards sign languages from high-income countries. In this work we introduce a new large and highly multilingual dataset for sign language translation: JWSign. The dataset consists of 2,530 hours of Bible translations in 98 sign languages, featuring more than 1,500 individual signers. On this dataset, we report neural machine translation experiments. Apart from bilingual baseline systems, we also train multilingual systems, including some that take into account the typological relatedness of signed or spoken languages. Our experiments highlight that multilingual systems are superior to bilingual baselines, and that in higher-resource scenarios, clustering language pairs that are related improves translation quality.
Linguistically Motivated Sign Language Segmentation
Oct 30, 2023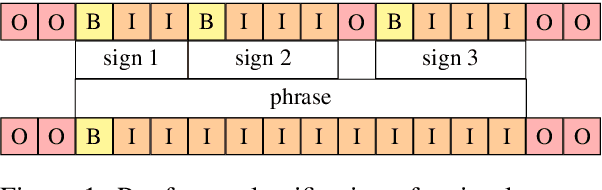



Sign language segmentation is a crucial task in sign language processing systems. It enables downstream tasks such as sign recognition, transcription, and machine translation. In this work, we consider two kinds of segmentation: segmentation into individual signs and segmentation into phrases, larger units comprising several signs. We propose a novel approach to jointly model these two tasks. Our method is motivated by linguistic cues observed in sign language corpora. We replace the predominant IO tagging scheme with BIO tagging to account for continuous signing. Given that prosody plays a significant role in phrase boundaries, we explore the use of optical flow features. We also provide an extensive analysis of hand shapes and 3D hand normalization. We find that introducing BIO tagging is necessary to model sign boundaries. Explicitly encoding prosody by optical flow improves segmentation in shallow models, but its contribution is negligible in deeper models. Careful tuning of the decoding algorithm atop the models further improves the segmentation quality. We demonstrate that our final models generalize to out-of-domain video content in a different signed language, even under a zero-shot setting. We observe that including optical flow and 3D hand normalization enhances the robustness of the model in this context.
pose-format: Library for Viewing, Augmenting, and Handling .pose Files
Oct 13, 2023

Managing and analyzing pose data is a complex task, with challenges ranging from handling diverse file structures and data types to facilitating effective data manipulations such as normalization and augmentation. This paper presents \texttt{pose-format}, a comprehensive toolkit designed to address these challenges by providing a unified, flexible, and easy-to-use interface. The library includes a specialized file format that encapsulates various types of pose data, accommodating multiple individuals and an indefinite number of time frames, thus proving its utility for both image and video data. Furthermore, it offers seamless integration with popular numerical libraries such as NumPy, PyTorch, and TensorFlow, thereby enabling robust machine-learning applications. Through benchmarking, we demonstrate that our \texttt{.pose} file format offers vastly superior performance against prevalent formats like OpenPose, with added advantages like self-contained pose specification. Additionally, the library includes features for data normalization, augmentation, and easy-to-use visualization capabilities, both in Python and Browser environments. \texttt{pose-format} emerges as a one-stop solution, streamlining the complexities of pose data management and analysis.
Voting Booklet Bias: Stance Detection in Swiss Federal Communication
Jun 15, 2023
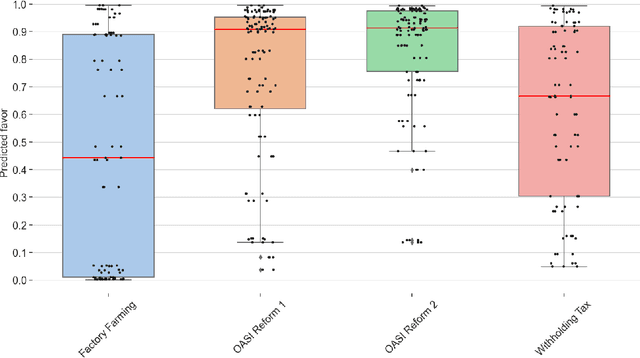
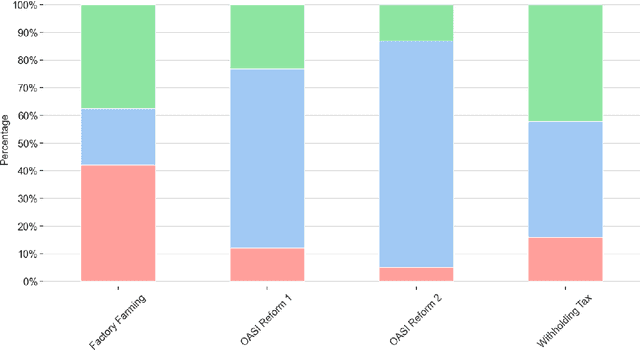
In this study, we use recent stance detection methods to study the stance (for, against or neutral) of statements in official information booklets for voters. Our main goal is to answer the fundamental question: are topics to be voted on presented in a neutral way? To this end, we first train and compare several models for stance detection on a large dataset about Swiss politics. We find that fine-tuning an M-BERT model leads to the best accuracy. We then use our best model to analyze the stance of utterances extracted from the Swiss federal voting booklet concerning the Swiss popular votes of September 2022, which is the main goal of this project. We evaluated the models in both a multilingual as well as a monolingual context for German, French, and Italian. Our analysis shows that some issues are heavily favored while others are more balanced, and that the results are largely consistent across languages. Our findings have implications for the editorial process of future voting booklets and the design of better automated systems for analyzing political discourse. The data and code accompanying this paper are available at https://github.com/ZurichNLP/voting-booklet-bias.
An Open-Source Gloss-Based Baseline for Spoken to Signed Language Translation
May 28, 2023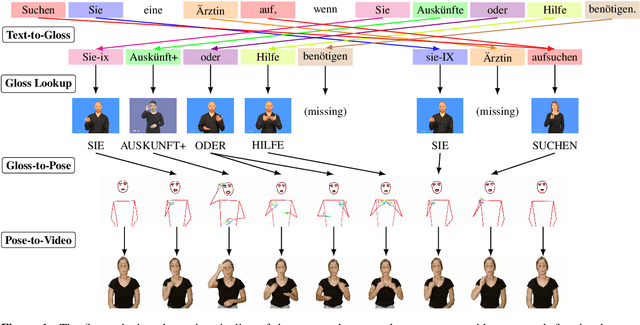


Sign language translation systems are complex and require many components. As a result, it is very hard to compare methods across publications. We present an open-source implementation of a text-to-gloss-to-pose-to-video pipeline approach, demonstrating conversion from German to Swiss German Sign Language, French to French Sign Language of Switzerland, and Italian to Italian Sign Language of Switzerland. We propose three different components for the text-to-gloss translation: a lemmatizer, a rule-based word reordering and dropping component, and a neural machine translation system. Gloss-to-pose conversion occurs using data from a lexicon for three different signed languages, with skeletal poses extracted from videos. To generate a sentence, the text-to-gloss system is first run, and the pose representations of the resulting signs are stitched together.
SLTUNET: A Simple Unified Model for Sign Language Translation
May 02, 2023


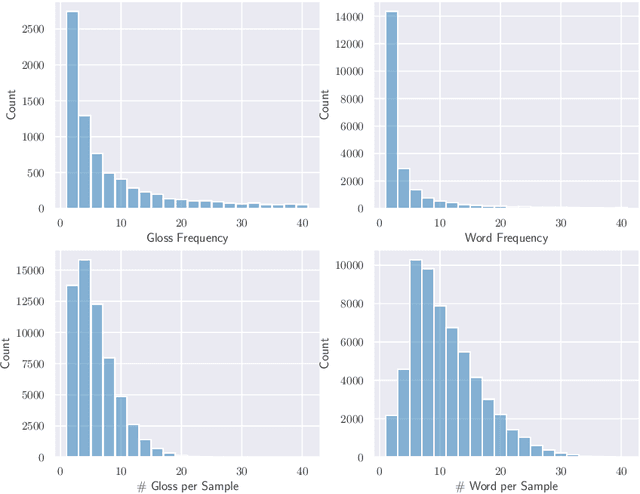
Despite recent successes with neural models for sign language translation (SLT), translation quality still lags behind spoken languages because of the data scarcity and modality gap between sign video and text. To address both problems, we investigate strategies for cross-modality representation sharing for SLT. We propose SLTUNET, a simple unified neural model designed to support multiple SLTrelated tasks jointly, such as sign-to-gloss, gloss-to-text and sign-to-text translation. Jointly modeling different tasks endows SLTUNET with the capability to explore the cross-task relatedness that could help narrow the modality gap. In addition, this allows us to leverage the knowledge from external resources, such as abundant parallel data used for spoken-language machine translation (MT). We show in experiments that SLTUNET achieves competitive and even state-of-the-art performance on PHOENIX-2014T and CSL-Daily when augmented with MT data and equipped with a set of optimization techniques. We further use the DGS Corpus for end-to-end SLT for the first time. It covers broader domains with a significantly larger vocabulary, which is more challenging and which we consider to allow for a more realistic assessment of the current state of SLT than the former two. Still, SLTUNET obtains improved results on the DGS Corpus. Code is available at https://github.com/bzhangGo/sltunet.
Considerations for meaningful sign language machine translation based on glosses
Nov 28, 2022
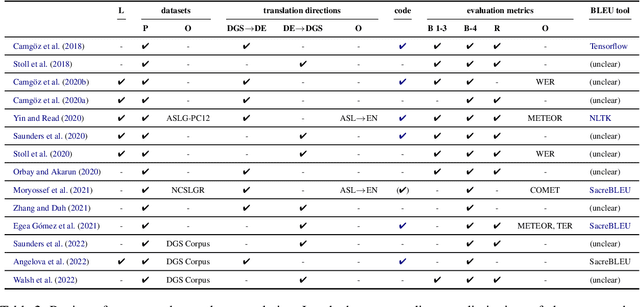


Automatic sign language processing is gaining popularity in Natural Language Processing (NLP) research (Yin et al., 2021). In machine translation (MT) in particular, sign language translation based on glosses is a prominent approach. In this paper, we review recent works on neural gloss translation. We find that limitations of glosses in general and limitations of specific datasets are not discussed in a transparent manner and that there is no common standard for evaluation. To address these issues, we put forward concrete recommendations for future research on gloss translation. Our suggestions advocate awareness of the inherent limitations of gloss-based approaches, realistic datasets, stronger baselines and convincing evaluation.