 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Whisper understand Swiss German? An automatic, qualitative, and human evaluation
Apr 30, 2024

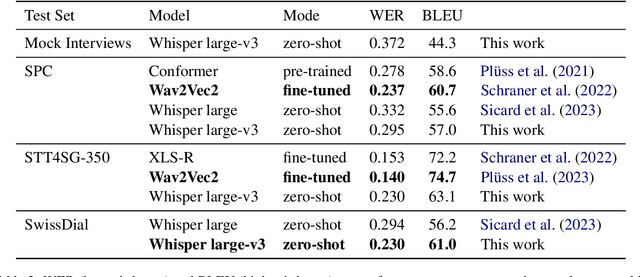
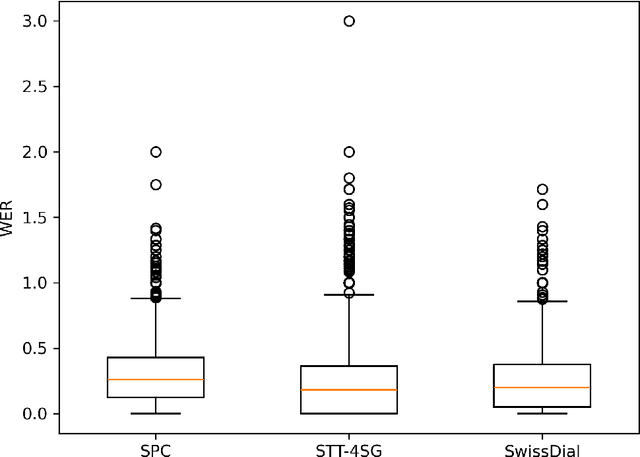
Whisper is a state-of-the-art automatic speech recognition (ASR) model (Radford et al., 2022). Although Swiss German dialects are allegedly not part of Whisper's training data, preliminary experiments showed that Whisper can transcribe Swiss German quite well, with the output being a speech translation into Standard German. To gain a better understanding of Whisper's performance on Swiss German, we systematically evaluate it using automatic, qualitative, and human evaluation. We test its performance on three existing test sets: SwissDial (Dogan-Sch\"onberger et al., 2021), STT4SG-350 (Pl\"uss et al., 2023), and Swiss Parliaments Corpus (Pl\"uss et al., 2021). In addition, we create a new test set for this work, based on short mock clinical interviews. For automatic evaluation, we used word error rate (WER) and BLEU. In the qualitative analysis, we discuss Whisper's strengths and weaknesses and anylyze some output examples. For the human evaluation, we conducted a survey with 28 participants who were asked to evaluate Whisper's performance. All of our evaluations suggest that Whisper is a viable ASR system for Swiss German, so long as the Standard German output is desired.
Voting Booklet Bias: Stance Detection in Swiss Federal Communication
Jun 15, 2023
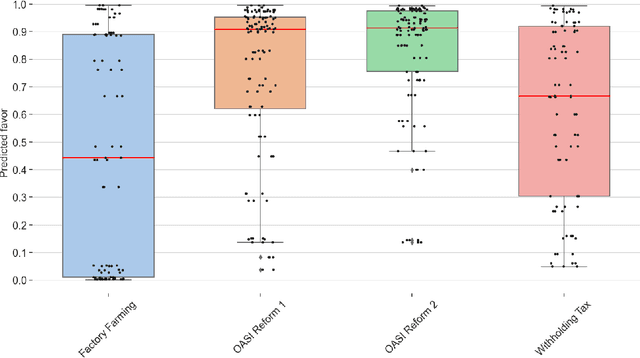
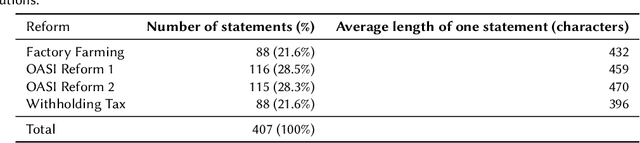
In this study, we use recent stance detection methods to study the stance (for, against or neutral) of statements in official information booklets for voters. Our main goal is to answer the fundamental question: are topics to be voted on presented in a neutral way? To this end, we first train and compare several models for stance detection on a large dataset about Swiss politics. We find that fine-tuning an M-BERT model leads to the best accuracy. We then use our best model to analyze the stance of utterances extracted from the Swiss federal voting booklet concerning the Swiss popular votes of September 2022, which is the main goal of this project. We evaluated the models in both a multilingual as well as a monolingual context for German, French, and Italian. Our analysis shows that some issues are heavily favored while others are more balanced, and that the results are largely consistent across languages. Our findings have implications for the editorial process of future voting booklets and the design of better automated systems for analyzing political discourse. The data and code accompanying this paper are available at https://github.com/ZurichNLP/voting-booklet-bias.
Does mBERT understand Romansh? Evaluating word embeddings using word alignment
Jun 14, 2023We test similarity-based word alignment models (SimAlign and awesome-align) in combination with word embeddings from mBERT and XLM-R on parallel sentences in German and Romansh. Since Romansh is an unseen language, we are dealing with a zero-shot setting. Using embeddings from mBERT, both models reach an alignment error rate of 0.22, which outperforms fast_align, a statistical model, and is on par with similarity-based word alignment for seen languages. We interpret these results as evidence that mBERT contains information that can be meaningful and applicable to Romansh. To evaluate performance, we also present a new trilingual corpus, which we call the DERMIT (DE-RM-IT) corpus, containing press releases made by the Canton of Grisons in German, Romansh and Italian in the past 25 years. The corpus contains 4 547 parallel documents and approximately 100 000 sentence pairs in each language combination. We additionally present a gold standard for German-Romansh word alignment. The data is available at https://github.com/eyldlv/DERMIT-Corpus.