 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Byte Language Models -- A Hierarchical Architecture for Causal Million-Length Sequence Modeling
Feb 20, 2025Bytes form the basis of the digital world and thus are a promising building block for multimodal foundation models. Recently, Byte Language Models (BLMs) have emerged to overcome tokenization, yet the excessive length of bytestreams requires new architectural paradigms. Therefore, we present the Multiscale Byte Language Model (MBLM), a model-agnostic hierarchical decoder stack that allows training with context windows of $5$M bytes on single GPU in full model precision. We thoroughly examine MBLM's performance with Transformer and Mamba blocks on both unimodal and multimodal tasks. Our experiments demonstrate that hybrid architectures are efficient in handling extremely long byte sequences during training while achieving near-linear generational efficiency. To the best of our knowledge, we present the first evaluation of BLMs on visual Q\&A tasks and find that, despite serializing images and the absence of an encoder, a MBLM with pure next token prediction can match custom CNN-LSTM architectures with designated classification heads. We show that MBLMs exhibit strong adaptability in integrating diverse data representations, including pixel and image filestream bytes, underlining their potential toward omnimodal foundation models. Source code is publicly available at: https://github.com/ai4sd/multiscale-byte-lm
Voting Booklet Bias: Stance Detection in Swiss Federal Communication
Jun 15, 2023
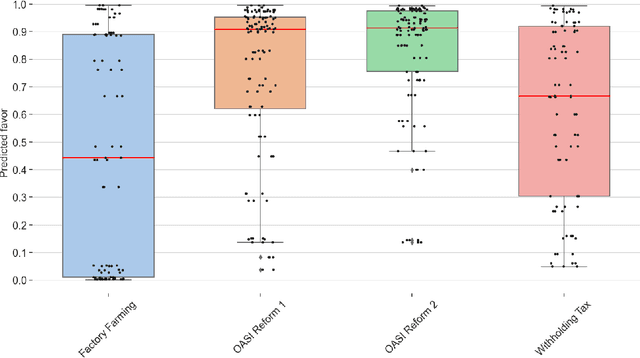
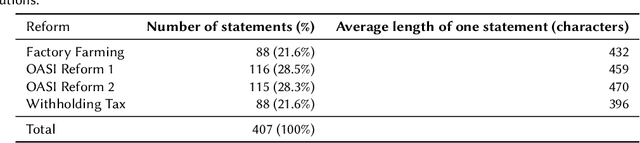
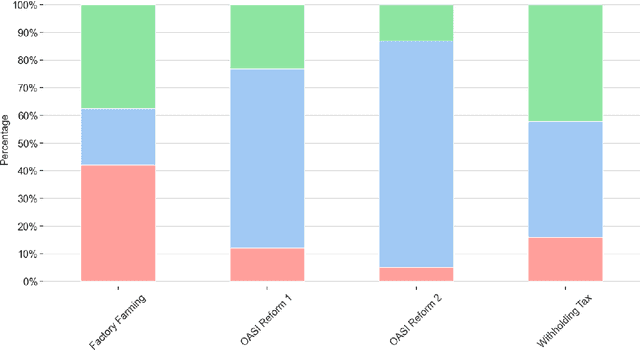
In this study, we use recent stance detection methods to study the stance (for, against or neutral) of statements in official information booklets for voters. Our main goal is to answer the fundamental question: are topics to be voted on presented in a neutral way? To this end, we first train and compare several models for stance detection on a large dataset about Swiss politics. We find that fine-tuning an M-BERT model leads to the best accuracy. We then use our best model to analyze the stance of utterances extracted from the Swiss federal voting booklet concerning the Swiss popular votes of September 2022, which is the main goal of this project. We evaluated the models in both a multilingual as well as a monolingual context for German, French, and Italian. Our analysis shows that some issues are heavily favored while others are more balanced, and that the results are largely consistent across languages. Our findings have implications for the editorial process of future voting booklets and the design of better automated systems for analyzing political discourse. The data and code accompanying this paper are available at https://github.com/ZurichNLP/voting-booklet-bias.