 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHuBERT: Self-Supervised Sign Language Representation Learning via Multi-Stream Cluster Prediction
Nov 25, 2024
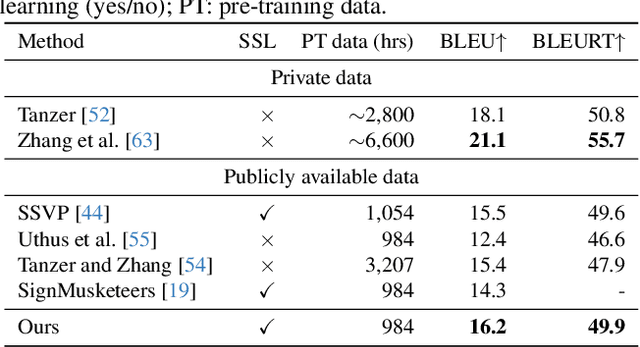

Sign language processing has traditionally relied on task-specific models,limiting the potential for transfer learning across tasks. We introduce SHuBERT (Sign Hidden-Unit BERT), a self-supervised transformer encoder that learns strong representations from approximately 1,000 hours of American Sign Language (ASL) video content. Inspired by the success of the HuBERT speech representation model, SHuBERT adapts masked prediction for multi-stream visual sign language input, learning to predict multiple targets for corresponding to clustered hand, face, and body pose streams. SHuBERT achieves state-of-the-art performance across multiple benchmarks. On sign language translation, it outperforms prior methods trained on publicly available data on the How2Sign (+0.7 BLEU), OpenASL (+10.0 BLEU), and FLEURS-ASL (+0.3 BLEU) benchmarks. Similarly for isolated sign language recognition, SHuBERT's accuracy surpasses that of specialized models on ASL-Citizen (+5\%) and SEM-LEX (+20.6\%), while coming close to them on WLASL2000 (-3\%). Ablation studies confirm the contribution of each component of the approach.
SignMusketeers: An Efficient Multi-Stream Approach for Sign Language Translation at Scale
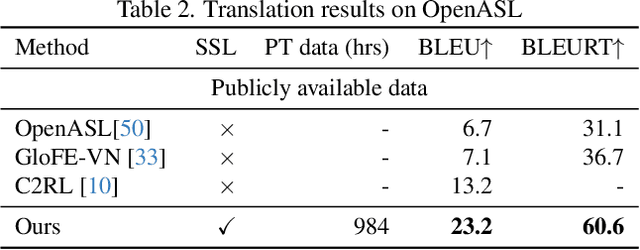
Jun 11, 2024A persistent challenge in sign language video processing, including the task of sign language to written language translation, is how we learn representations of sign language in an effective and efficient way that can preserve the important attributes of these languages, while remaining invariant to irrelevant visual differences. Informed by the nature and linguistics of signed languages, our proposed method focuses on just the most relevant parts in a signing video: the face, hands and body posture of the signer. However, instead of using pose estimation coordinates from off-the-shelf pose tracking models, which have inconsistent performance for hands and faces, we propose to learn the complex handshapes and rich facial expressions of sign languages in a self-supervised fashion. Our approach is based on learning from individual frames (rather than video sequences) and is therefore much more efficient than prior work on sign language pre-training. Compared to a recent model that established a new state of the art in sign language translation on the How2Sign dataset, our approach yields similar translation performance, using less than 3\% of the compute.
JWSign: A Highly Multilingual Corpus of Bible Translations for more Diversity in Sign Language Processing
Nov 16, 2023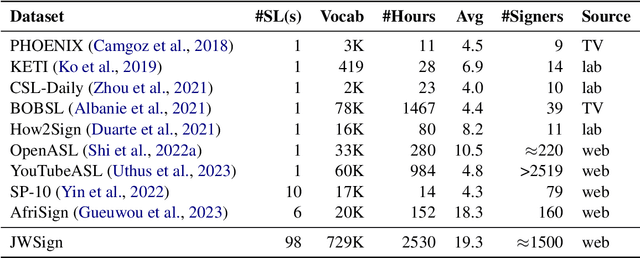

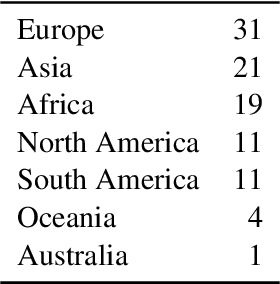

Advancements in sign language processing have been hindered by a lack of sufficient data, impeding progress in recognition, translation, and production tasks. The absence of comprehensive sign language datasets across the world's sign languages has widened the gap in this field, resulting in a few sign languages being studied more than others, making this research area extremely skewed mostly towards sign languages from high-income countries. In this work we introduce a new large and highly multilingual dataset for sign language translation: JWSign. The dataset consists of 2,530 hours of Bible translations in 98 sign languages, featuring more than 1,500 individual signers. On this dataset, we report neural machine translation experiments. Apart from bilingual baseline systems, we also train multilingual systems, including some that take into account the typological relatedness of signed or spoken languages. Our experiments highlight that multilingual systems are superior to bilingual baselines, and that in higher-resource scenarios, clustering language pairs that are related improves translation quality.
Stance Prediction and Analysis of Twitter data : A case study of Ghana 2020 Presidential Elections
Jun 27, 2023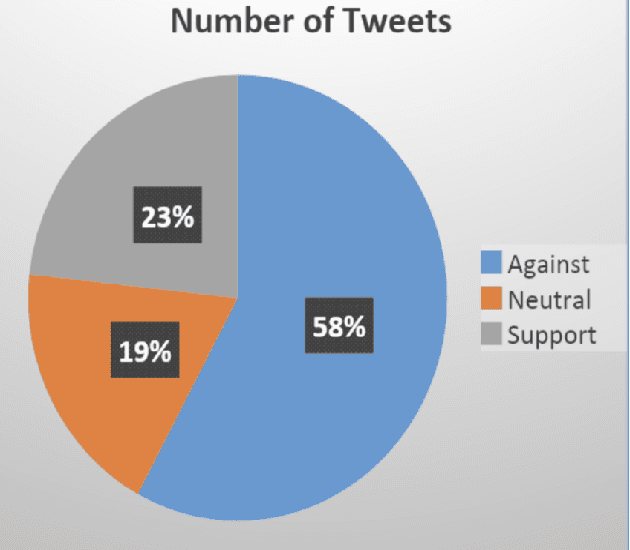

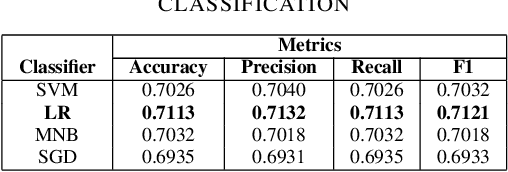

On December 7, 2020, Ghanaians participated in the polls to determine their president for the next four years. To gain insights from this presidential election, we conducted stance analysis (which is not always equivalent to sentiment analysis) to understand how Twitter, a popular social media platform, reflected the opinions of its users regarding the two main presidential candidates. We collected a total of 99,356 tweets using the Twitter API (Tweepy) and manually annotated 3,090 tweets into three classes: Against, Neutral, and Support. We then performed preprocessing on the tweets. The resulting dataset was evaluated using two lexicon-based approaches, VADER and TextBlob, as well as five supervised machine learning-based approaches: Support Vector Machine (SVM), Logistic Regression (LR), Multinomial Na\"ive Bayes (MNB), Stochastic Gradient Descent (SGD), and Random Forest (RF), based on metrics such as accuracy, precision, recall, and F1-score. The best performance was achieved by Logistic Regression with an accuracy of 71.13%. We utilized Logistic Regression to classify all the extracted tweets and subsequently conducted an analysis and discussion of the results. For access to our data and code, please visit: https://github.com/ShesterG/Stance-Detection-Ghana-2020-Elections.git