 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSeTOX: Re-learning attention weights for toxicity mitigation in machine translation
May 19, 2023



Our proposed method, ReSeTOX (REdo SEarch if TOXic), addresses the issue of Neural Machine Translation (NMT) generating translation outputs that contain toxic words not present in the input. The objective is to mitigate the introduction of toxic language without the need for re-training. In the case of identified added toxicity during the inference process, ReSeTOX dynamically adjusts the key-value self-attention weights and re-evaluates the beam search hypotheses. Experimental results demonstrate that ReSeTOX achieves a remarkable 57% reduction in added toxicity while maintaining an average translation quality of 99.5% across 164 languages.
Multiformer: A Head-Configurable Transformer-Based Model for Direct Speech Translation
May 14, 2022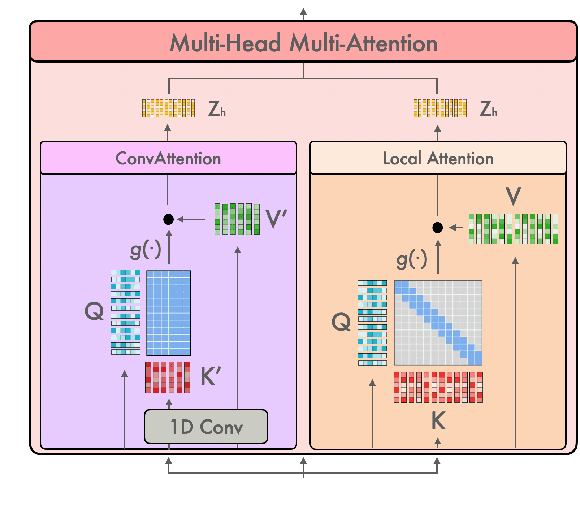
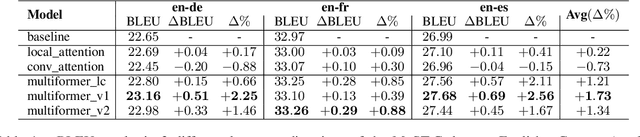
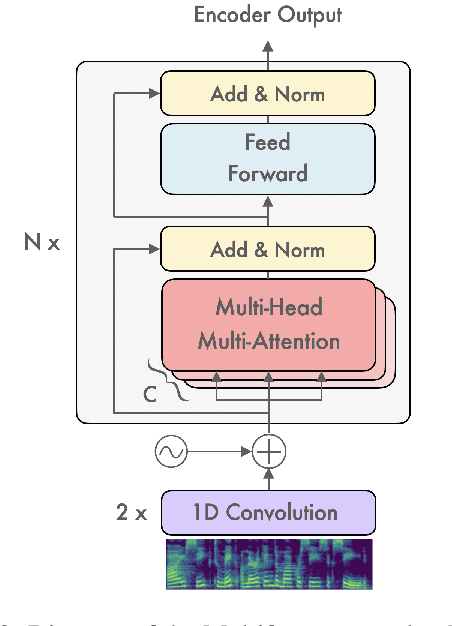
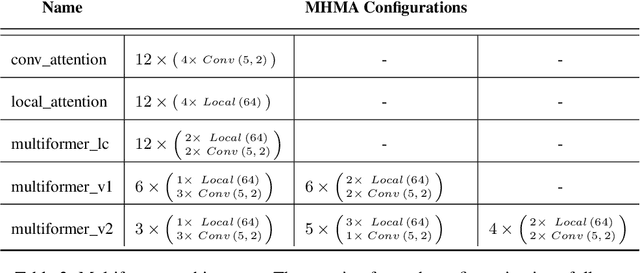
Transformer-based models have been achieving state-of-the-art results in several fields of Natural Language Processing. However, its direct application to speech tasks is not trivial. The nature of this sequences carries problems such as long sequence lengths and redundancy between adjacent tokens. Therefore, we believe that regular self-attention mechanism might not be well suited for it. Different approaches have been proposed to overcome these problems, such as the use of efficient attention mechanisms. However, the use of these methods usually comes with a cost, which is a performance reduction caused by information loss. In this study, we present the Multiformer, a Transformer-based model which allows the use of different attention mechanisms on each head. By doing this, the model is able to bias the self-attention towards the extraction of more diverse token interactions, and the information loss is reduced. Finally, we perform an analysis of the head contributions, and we observe that those architectures where all heads relevance is uniformly distributed obtain better results. Our results show that mixing attention patterns along the different heads and layers outperforms our baseline by up to 0.7 BLEU.
From Bilingual to Multilingual Neural Machine Translation by Incremental Training
Jul 11, 2019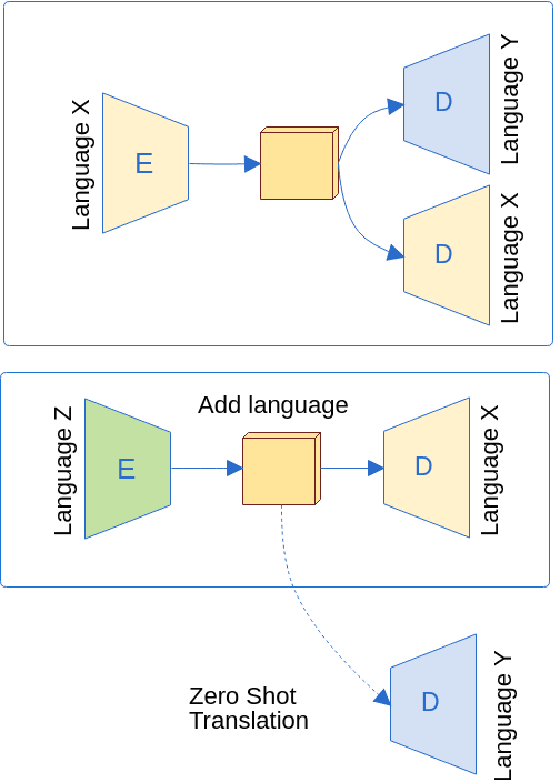
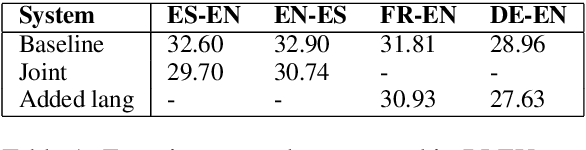

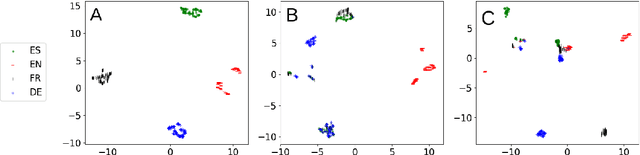
Multilingual Neural Machine Translation approaches are based on the use of task-specific models and the addition of one more language can only be done by retraining the whole system. In this work, we propose a new training schedule that allows the system to scale to more languages without modification of the previous components based on joint training and language-independent encoder/decoder modules allowing for zero-shot translation. This work in progress shows close results to the state-of-the-art in the WMT task.
Character-based Neural Machine Translation
Jun 30, 2016
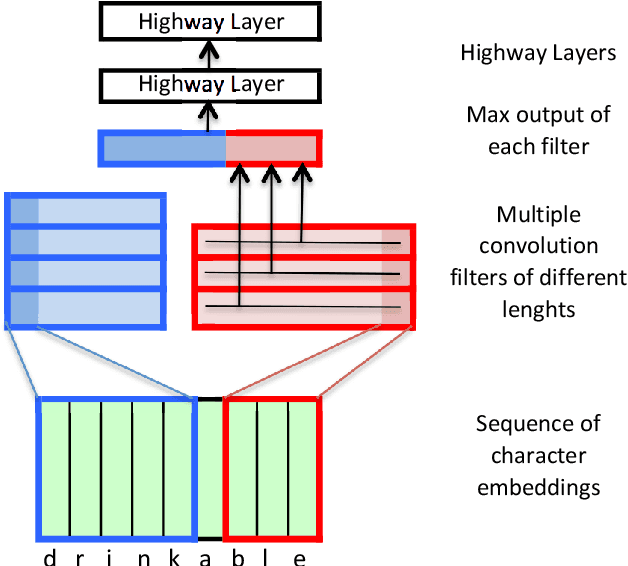

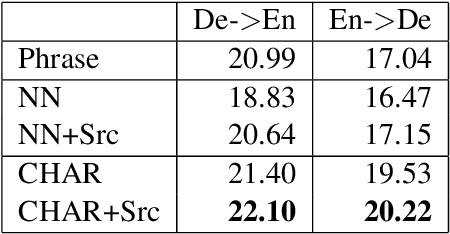
Neural Machine Translation (MT) has reached state-of-the-art results. However, one of the main challenges that neural MT still faces is dealing with very large vocabularies and morphologically rich languages. In this paper, we propose a neural MT system using character-based embeddings in combination with convolutional and highway layers to replace the standard lookup-based word representations. The resulting unlimited-vocabulary and affix-aware source word embeddings are tested in a state-of-the-art neural MT based on an attention-based bidirectional recurrent neural network. The proposed MT scheme provides improved results even when the source language is not morphologically rich. Improvements up to 3 BLEU points are obtained in the German-English WMT task.