 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Robustness in Neural Machine Translation
Paper and Code

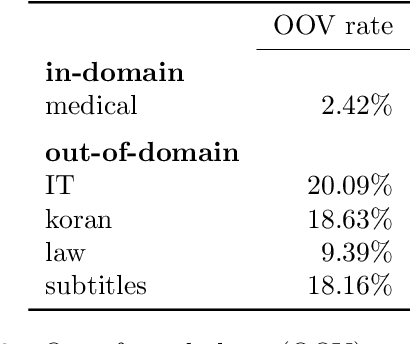
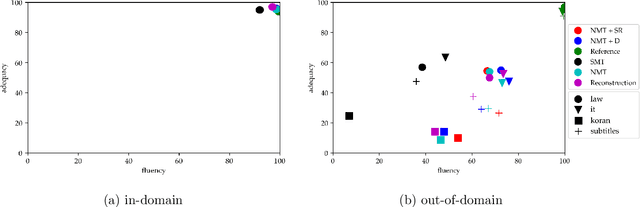

Translating text that diverges from the training domain is a key challenge for neural machine translation (NMT). Domain robustness - the generalization of models to unseen test domains - is low compared to statistical machine translation. In this paper, we investigate the performance of NMT on out-of-domain test sets, and ways to improve it. We observe that hallucination (translations that are fluent but unrelated to the source) is common in out-of-domain settings, and we empirically compare methods that improve adequacy (reconstruction), out-of-domain translation (subword regularization), or robustness against adversarial examples (defensive distillation), as well as noisy channel models. In experiments on German to English OPUS data, and German to Romansh, a low-resource scenario, we find that several methods improve domain robustness, reconstruction standing out as a method that not only improves automatic scores, but also shows improvements in a manual assessments of adequacy, albeit at some loss in fluency. However, out-of-domain performance is still relatively low and domain robustness remains an open problem.