 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
Mention Attention for Pronoun Translation
Dec 19, 2024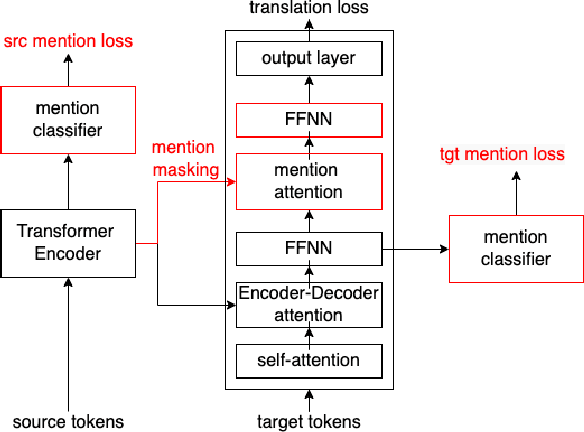

Most pronouns are referring expressions, computers need to resolve what do the pronouns refer to, and there are divergences on pronoun usage across languages. Thus, dealing with these divergences and translating pronouns is a challenge in machine translation. Mentions are referring candidates of pronouns and have closer relations with pronouns compared to general tokens. We assume that extracting additional mention features can help pronoun translation. Therefore, we introduce an additional mention attention module in the decoder to pay extra attention to source mentions but not non-mention tokens. Our mention attention module not only extracts features from source mentions, but also considers target-side context which benefits pronoun translation. In addition, we also introduce two mention classifiers to train models to recognize mentions, whose outputs guide the mention attention. We conduct experiments on the WMT17 English-German translation task, and evaluate our models on general translation and pronoun translation, using BLEU, APT, and contrastive evaluation metrics. Our proposed model outperforms the baseline Transformer model in terms of APT and BLEU scores, this confirms our hypothesis that we can improve pronoun translation by paying additional attention to source mentions, and shows that our introduced additional modules do not have negative effect on the general translation quality.
Parallel Data Helps Neural Entity Coreference Resolution
May 28, 2023Coreference resolution is the task of finding expressions that refer to the same entity in a text. Coreference models are generally trained on monolingual annotated data but annotating coreference is expensive and challenging. Hardmeier et al.(2013) have shown that parallel data contains latent anaphoric knowledge, but it has not been explored in end-to-end neural models yet. In this paper, we propose a simple yet effective model to exploit coreference knowledge from parallel data. In addition to the conventional modules learning coreference from annotations, we introduce an unsupervised module to capture cross-lingual coreference knowledge. Our proposed cross-lingual model achieves consistent improvements, up to 1.74 percentage points, on the OntoNotes 5.0 English dataset using 9 different synthetic parallel datasets. These experimental results confirm that parallel data can provide additional coreference knowledge which is beneficial to coreference resolution tasks.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021


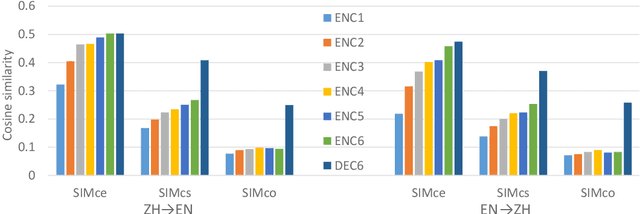
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.
Understanding Pure Character-Based Neural Machine Translation: The Case of Translating Finnish into English
Nov 06, 2020
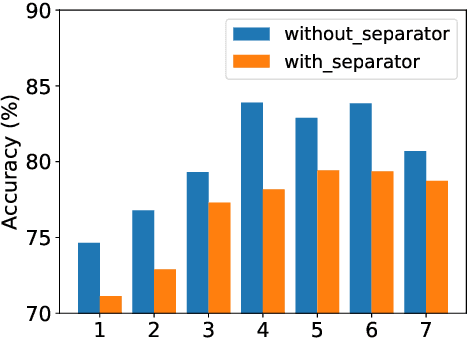

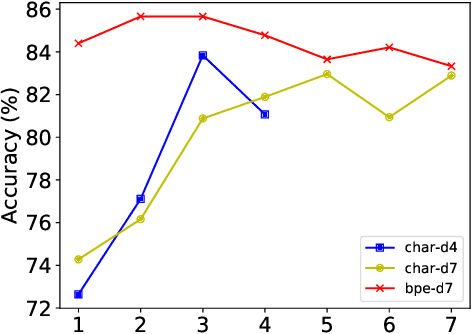
Recent work has shown that deeper character-based neural machine translation (NMT) models can outperform subword-based models. However, it is still unclear what makes deeper character-based models successful. In this paper, we conduct an investigation into pure character-based models in the case of translating Finnish into English, including exploring the ability to learn word senses and morphological inflections and the attention mechanism. We demonstrate that word-level information is distributed over the entire character sequence rather than over a single character, and characters at different positions play different roles in learning linguistic knowledge. In addition, character-based models need more layers to encode word senses which explains why only deeper models outperform subword-based models. The attention distribution pattern shows that separators attract a lot of attention and we explore a sparse word-level attention to enforce character hidden states to capture the full word-level information. Experimental results show that the word-level attention with a single head results in 1.2 BLEU points drop.
Encoders Help You Disambiguate Word Senses in Neural Machine Translation
Aug 30, 2019



Neural machine translation (NMT) has achieved new state-of-the-art performance in translating ambiguous words. However, it is still unclear which component dominates the process of disambiguation. In this paper, we explore the ability of NMT encoders and decoders to disambiguate word senses by evaluating hidden states and investigating the distributions of self-attention. We train a classifier to predict whether a translation is correct given the representation of an ambiguous noun. We find that encoder hidden states outperform word embeddings significantly which indicates that encoders adequately encode relevant information for disambiguation into hidden states. In contrast to encoders, the effect of decoder is different in models with different architectures. Moreover, the attention weights and attention entropy show that self-attention can detect ambiguous nouns and distribute more attention to the context.
Understanding Neural Machine Translation by Simplification: The Case of Encoder-free Models
Jul 18, 2019



In this paper, we try to understand neural machine translation (NMT) via simplifying NMT architectures and training encoder-free NMT models. In an encoder-free model, the sums of word embeddings and positional embeddings represent the source. The decoder is a standard Transformer or recurrent neural network that directly attends to embeddings via attention mechanisms. Experimental results show (1) that the attention mechanism in encoder-free models acts as a strong feature extractor, (2) that the word embeddings in encoder-free models are competitive to those in conventional models, (3) that non-contextualized source representations lead to a big performance drop, and (4) that encoder-free models have different effects on alignment quality for German-English and Chinese-English.
An Analysis of Attention Mechanisms: The Case of Word Sense Disambiguation in Neural Machine Translation
Oct 17, 2018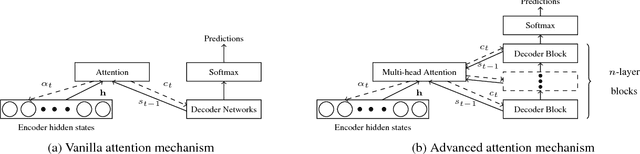



Recent work has shown that the encoder-decoder attention mechanisms in neural machine translation (NMT) are different from the word alignment in statistical machine translation. In this paper, we focus on analyzing encoder-decoder attention mechanisms, in the case of word sense disambiguation (WSD) in NMT models. We hypothesize that attention mechanisms pay more attention to context tokens when translating ambiguous words. We explore the attention distribution patterns when translating ambiguous nouns. Counter-intuitively, we find that attention mechanisms are likely to distribute more attention to the ambiguous noun itself rather than context tokens, in comparison to other nouns. We conclude that attention mechanism is not the main mechanism used by NMT models to incorporate contextual information for WSD. The experimental results suggest that NMT models learn to encode contextual information necessary for WSD in the encoder hidden states. For the attention mechanism in Transformer models, we reveal that the first few layers gradually learn to "align" source and target tokens and the last few layers learn to extract features from the related but unaligned context tokens.
Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures
Aug 28, 2018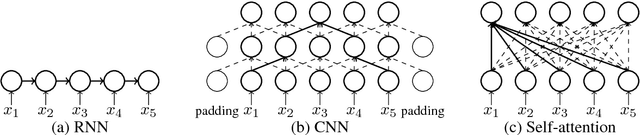
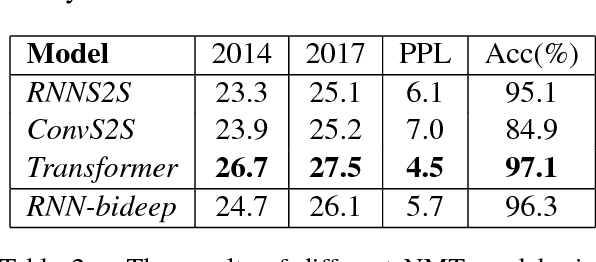
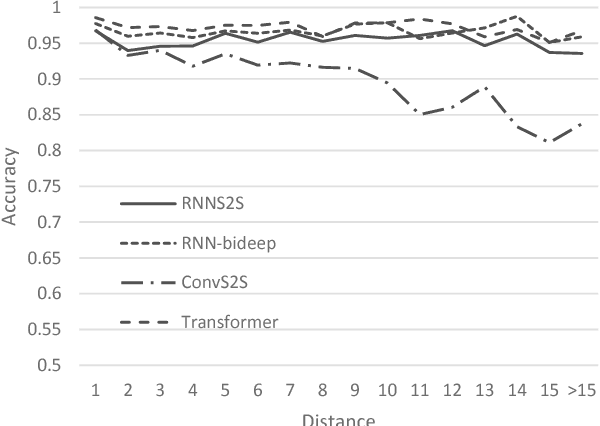

Recently, non-recurrent architectures (convolutional, self-attentional) have outperformed RNNs in neural machine translation. CNNs and self-attentional networks can connect distant words via shorter network paths than RNNs, and it has been speculated that this improves their ability to model long-range dependencies. However, this theoretical argument has not been tested empirically, nor have alternative explanations for their strong performance been explored in-depth. We hypothesize that the strong performance of CNNs and self-attentional networks could also be due to their ability to extract semantic features from the source text, and we evaluate RNNs, CNNs and self-attention networks on two tasks: subject-verb agreement (where capturing long-range dependencies is required) and word sense disambiguation (where semantic feature extraction is required). Our experimental results show that: 1) self-attentional networks and CNNs do not outperform RNNs in modeling subject-verb agreement over long distances; 2) self-attentional networks perform distinctly better than RNNs and CNNs on word sense disambiguation.
An Evaluation of Neural Machine Translation Models on Historical Spelling Normalization
Aug 04, 2018



In this paper, we apply different NMT models to the problem of historical spelling normalization for five languages: English, German, Hungarian, Icelandic, and Swedish. The NMT models are at different levels, have different attention mechanisms, and different neural network architectures. Our results show that NMT models are much better than SMT models in terms of character error rate. The vanilla RNNs are competitive to GRUs/LSTMs in historical spelling normalization. Transformer models perform better only when provided with more training data. We also find that subword-level models with a small subword vocabulary are better than character-level models for low-resource languages. In addition, we propose a hybrid method which further improves the performance of historical spelling normalization.