 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Negation in Neural Machine Translation
Paper and Code



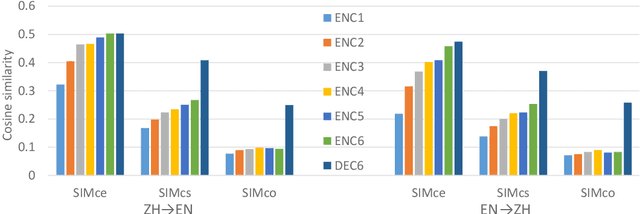
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.