 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Pure Character-Based Neural Machine Translation: The Case of Translating Finnish into English
Paper and Code
Nov 06, 2020
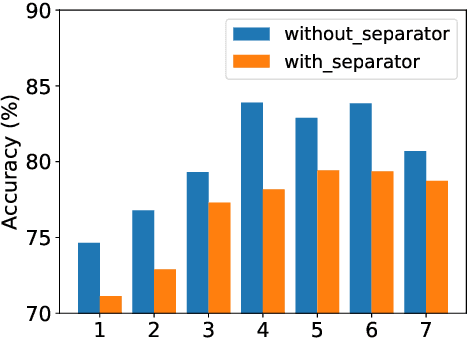

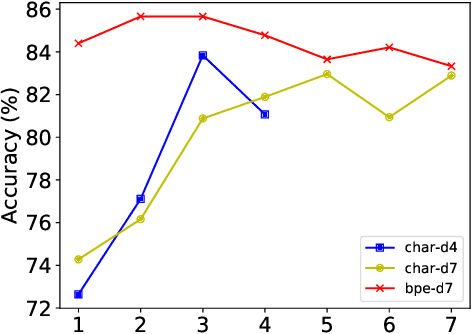
Recent work has shown that deeper character-based neural machine translation (NMT) models can outperform subword-based models. However, it is still unclear what makes deeper character-based models successful. In this paper, we conduct an investigation into pure character-based models in the case of translating Finnish into English, including exploring the ability to learn word senses and morphological inflections and the attention mechanism. We demonstrate that word-level information is distributed over the entire character sequence rather than over a single character, and characters at different positions play different roles in learning linguistic knowledge. In addition, character-based models need more layers to encode word senses which explains why only deeper models outperform subword-based models. The attention distribution pattern shows that separators attract a lot of attention and we explore a sparse word-level attention to enforce character hidden states to capture the full word-level information. Experimental results show that the word-level attention with a single head results in 1.2 BLEU points drop.