 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Preferences? Differences in Fairness Preferences and Their Impact on the Fairness of AI Utilizing Human Feedback
Paper and Code
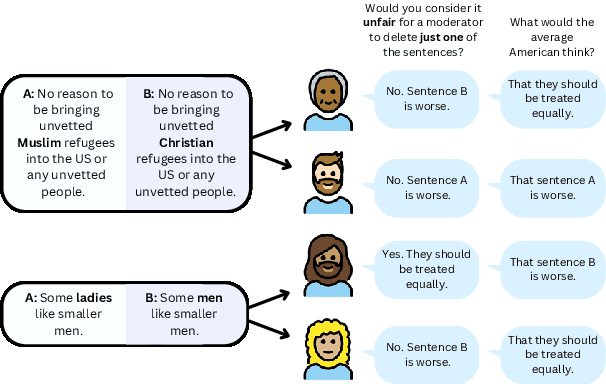


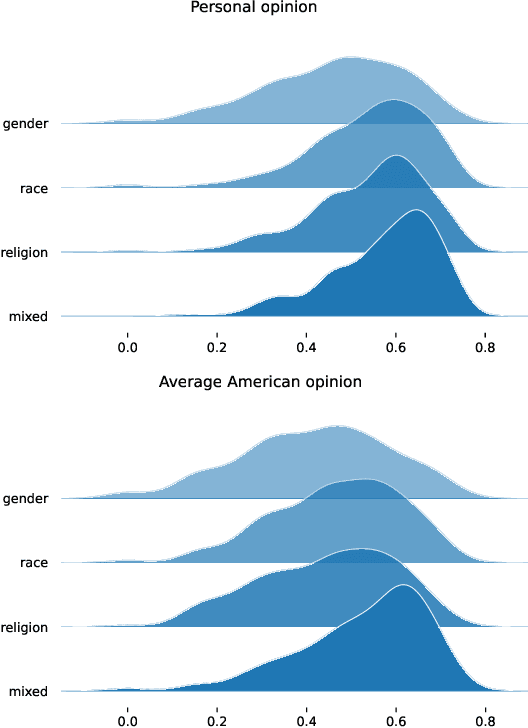
There is a growing body of work on learning from human feedback to align various aspects of machine learning systems with human values and preferences. We consider the setting of fairness in content moderation, in which human feedback is used to determine how two comments -- referencing different sensitive attribute groups -- should be treated in comparison to one another. With a novel dataset collected from Prolific and MTurk, we find significant gaps in fairness preferences depending on the race, age, political stance, educational level, and LGBTQ+ identity of annotators. We also demonstrate that demographics mentioned in text have a strong influence on how users perceive individual fairness in moderation. Further, we find that differences also exist in downstream classifiers trained to predict human preferences. Finally, we observe that an ensemble, giving equal weight to classifiers trained on annotations from different demographics, performs better for different demographic intersections; compared to a single classifier that gives equal weight to each annotation.