 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on the Test Task Confounds Evaluation and Emergence
Paper and Code



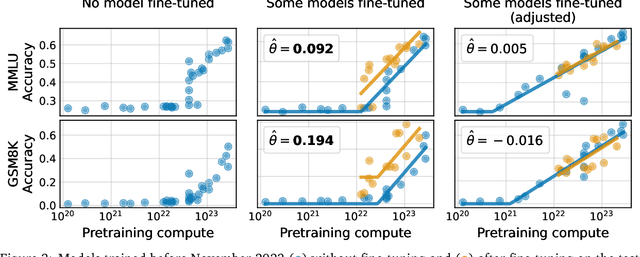
We study a fundamental problem in the evaluation of large language models that we call training on the test task. Unlike wrongful practices like training on the test data, leakage, or data contamination, training on the test task is not a malpractice. Rather, the term describes a growing set of techniques to include task-relevant data in the pretraining stage of a language model. We demonstrate that training on the test task confounds both relative model evaluations and claims about emergent capabilities. We argue that the seeming superiority of one model family over another may be explained by a different degree of training on the test task. To this end, we propose an effective method to adjust for training on the test task by fine-tuning each model under comparison on the same task-relevant data before evaluation. We then show that instances of emergent behavior largely vanish once we adjust for training on the test task. This also applies to reported instances of emergent behavior that cannot be explained by the choice of evaluation metric. Our work promotes a new perspective on the evaluation of large language models with broad implications for benchmarking and the study of emergent capabilities.