 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Attributions and Counterfactual Explanations Can Be Manipulated
Jun 25, 2021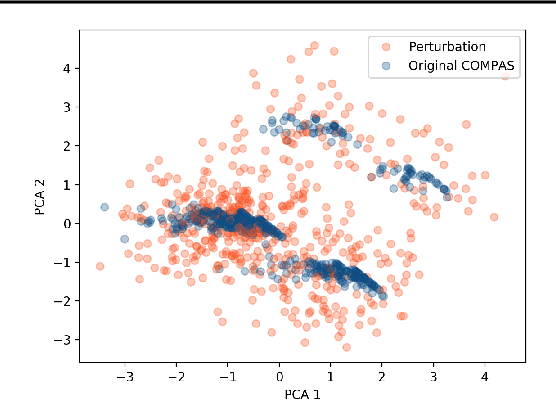
As machine learning models are increasingly used in critical decision-making settings (e.g., healthcare, finance), there has been a growing emphasis on developing methods to explain model predictions. Such \textit{explanations} are used to understand and establish trust in models and are vital components in machine learning pipelines. Though explanations are a critical piece in these systems, there is little understanding about how they are vulnerable to manipulation by adversaries. In this paper, we discuss how two broad classes of explanations are vulnerable to manipulation. We demonstrate how adversaries can design biased models that manipulate model agnostic feature attribution methods (e.g., LIME \& SHAP) and counterfactual explanations that hill-climb during the counterfactual search (e.g., Wachter's Algorithm \& DiCE) into \textit{concealing} the model's biases. These vulnerabilities allow an adversary to deploy a biased model, yet explanations will not reveal this bias, thereby deceiving stakeholders into trusting the model. We evaluate the manipulations on real world data sets, including COMPAS and Communities \& Crime, and find explanations can be manipulated in practice.
Counterfactual Explanations Can Be Manipulated
Jun 04, 2021
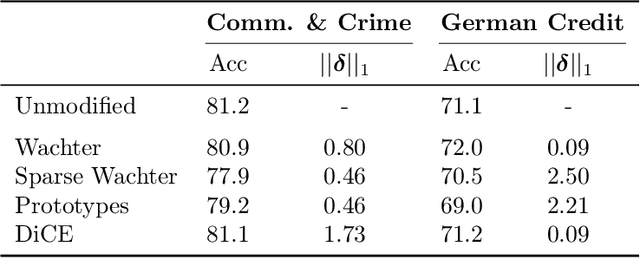
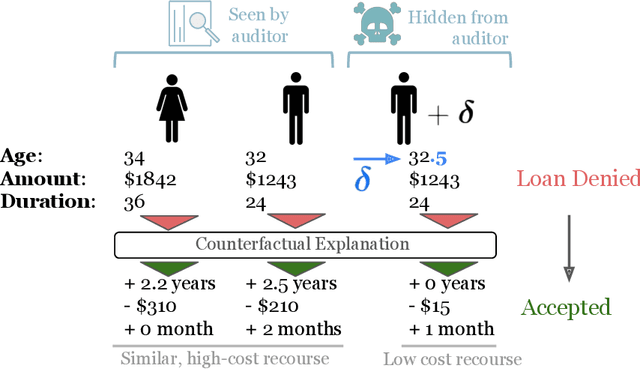

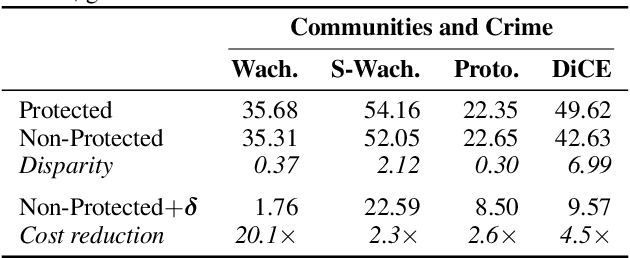
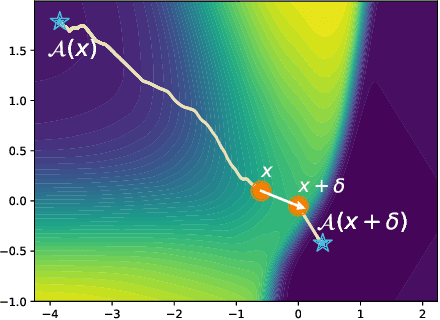
Counterfactual explanations are emerging as an attractive option for providing recourse to individuals adversely impacted by algorithmic decisions. As they are deployed in critical applications (e.g. law enforcement, financial lending), it becomes important to ensure that we clearly understand the vulnerabilities of these methods and find ways to address them. However, there is little understanding of the vulnerabilities and shortcomings of counterfactual explanations. In this work, we introduce the first framework that describes the vulnerabilities of counterfactual explanations and shows how they can be manipulated. More specifically, we show counterfactual explanations may converge to drastically different counterfactuals under a small perturbation indicating they are not robust. Leveraging this insight, we introduce a novel objective to train seemingly fair models where counterfactual explanations find much lower cost recourse under a slight perturbation. We describe how these models can unfairly provide low-cost recourse for specific subgroups in the data while appearing fair to auditors. We perform experiments on loan and violent crime prediction data sets where certain subgroups achieve up to 20x lower cost recourse under the perturbation. These results raise concerns regarding the dependability of current counterfactual explanation techniques, which we hope will inspire investigations in robust counterfactual explanations.
Does Fair Ranking Improve Minority Outcomes? Understanding the Interplay of Human and Algorithmic Biases in Online Hiring
Dec 01, 2020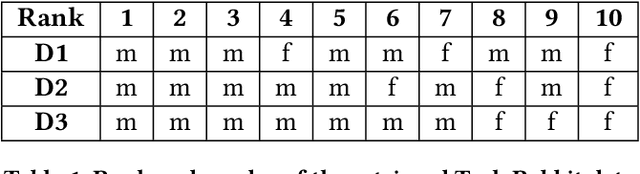
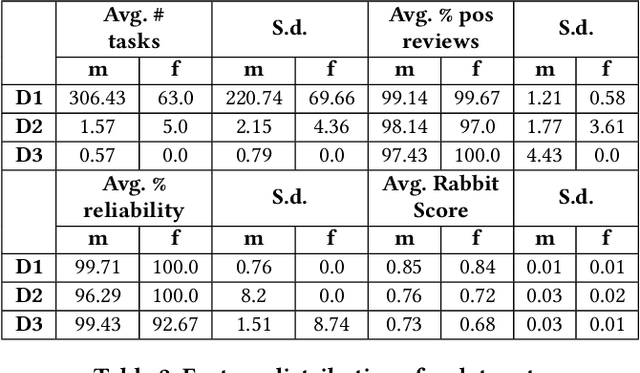
Ranking algorithms are being widely employed in various online hiring platforms including LinkedIn, TaskRabbit, and Fiverr. Since these platforms impact the livelihood of millions of people, it is important to ensure that the underlying algorithms are not adversely affecting minority groups. However, prior research has demonstrated that ranking algorithms employed by these platforms are prone to a variety of undesirable biases. To address this problem, fair ranking algorithms (e.g.,Det-Greedy) which increase exposure of underrepresented candidates have been proposed in recent literature. However, there is little to no work that explores if these proposed fair ranking algorithms actually improve real world outcomes (e.g., hiring decisions) for minority groups. Furthermore, there is no clear understanding as to how other factors (e.g., jobcontext, inherent biases of the employers) play a role in impacting the real world outcomes of minority groups. In this work, we study how gender biases manifest in online hiring platforms and how they impact real world hiring decisions. More specifically, we analyze various sources of gender biases including the nature of the ranking algorithm, the job context, and inherent biases of employers, and establish how these factors interact and affect real world hiring decisions. To this end, we experiment with three different ranking algorithms on three different job contexts using real world data from TaskRabbit. We simulate the hiring scenarios on TaskRabbit by carrying out a large-scale user study with Amazon Mechanical Turk. We then leverage the responses from this study to understand the effect of each of the aforementioned factors. Our results demonstrate that fair ranking algorithms can be an effective tool at increasing hiring of underrepresented gender candidates but induces inconsistent outcomes across candidate features and job contexts.
How Much Should I Trust You? Modeling Uncertainty of Black Box Explanations
Aug 11, 2020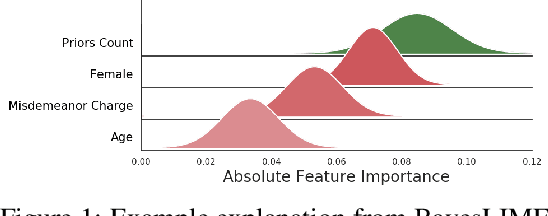

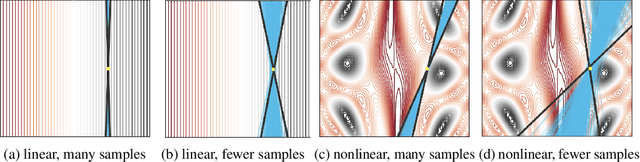

As local explanations of black box models are increasingly being employed to establish model credibility in high stakes settings, it is important to ensure that these explanations are accurate and reliable. However, local explanations generated by existing techniques are often prone to high variance. Further, these techniques are computationally inefficient, require significant hyper-parameter tuning, and provide little insight into the quality of the resulting explanations. By identifying lack of uncertainty modeling as the main cause of these challenges, we propose a novel Bayesian framework that produces explanations that go beyond point-wise estimates of feature importance. We instantiate this framework to generate Bayesian versions of LIME and KernelSHAP. In particular, we estimate credible intervals (CIs) that capture the uncertainty associated with each feature importance in local explanations. These credible intervals are tight when we have high confidence in the feature importances of a local explanation. The CIs are also informative both for estimating how many perturbations we need to sample -- sampling can proceed until the CIs are sufficiently narrow -- and where to sample -- sampling in regions with high predictive uncertainty leads to faster convergence. Experimental evaluation with multiple real world datasets and user studies demonstrate the efficacy of our framework and the resulting explanations.
From Predictions to Decisions: Using Lookahead Regularization
Jun 23, 2020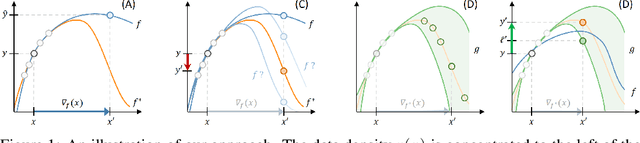
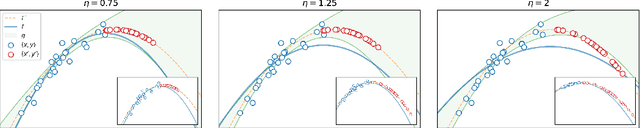
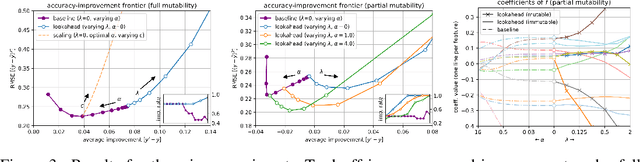
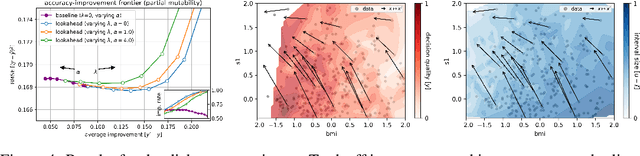
Machine learning is a powerful tool for predicting human-related outcomes, from credit scores to heart attack risks. But when deployed, learned models also affect how users act in order to improve outcomes, whether predicted or real. The standard approach to learning is agnostic to induced user actions and provides no guarantees as to the effect of actions. We provide a framework for learning predictors that are both accurate and promote good actions. For this, we introduce look-ahead regularization which, by anticipating user actions, encourages predictive models to also induce actions that improve outcomes. This regularization carefully tailors the uncertainty estimates governing confidence in this improvement to the distribution of model-induced actions. We report the results of experiments on real and synthetic data that show the effectiveness of this approach.
How can we fool LIME and SHAP? Adversarial Attacks on Post hoc Explanation Methods
Nov 06, 2019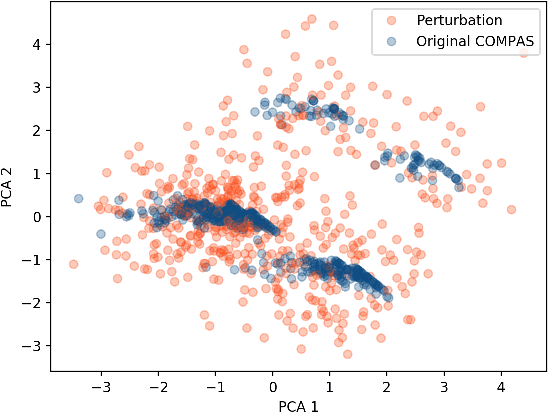

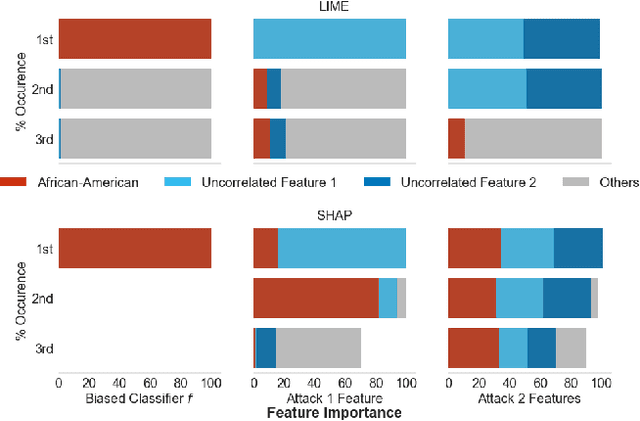

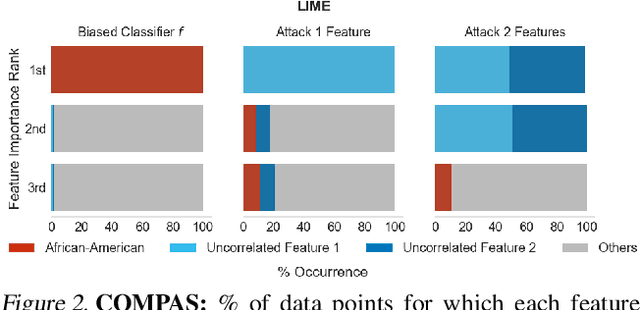
As machine learning black boxes are increasingly being deployed in domains such as healthcare and criminal justice, there is growing emphasis on building tools and techniques for explaining these black boxes in an interpretable manner. Such explanations are being leveraged by domain experts to diagnose systematic errors and underlying biases of black boxes. In this paper, we demonstrate that post hoc explanations techniques that rely on input perturbations, such as LIME and SHAP, are not reliable. Specifically, we propose a novel scaffolding technique that effectively hides the biases of any given classifier by allowing an adversarial entity to craft an arbitrary desired explanation. Our approach can be used to scaffold any biased classifier in such a way that its predictions on the input data distribution still remain biased, but the post hoc explanations of the scaffolded classifier look innocuous. Using extensive evaluation with multiple real-world datasets (including COMPAS), we demonstrate how extremely biased (racist) classifiers crafted by our framework can easily fool popular explanation techniques such as LIME and SHAP into generating innocuous explanations which do not reflect the underlying biases.
Learning Key-Value Store Design
Jul 11, 2019



We introduce the concept of design continuums for the data layout of key-value stores. A design continuum unifies major distinct data structure designs under the same model. The critical insight and potential long-term impact is that such unifying models 1) render what we consider up to now as fundamentally different data structures to be seen as views of the very same overall design space, and 2) allow seeing new data structure designs with performance properties that are not feasible by existing designs. The core intuition behind the construction of design continuums is that all data structures arise from the very same set of fundamental design principles, i.e., a small set of data layout design concepts out of which we can synthesize any design that exists in the literature as well as new ones. We show how to construct, evaluate, and expand, design continuums and we also present the first continuum that unifies major data structure designs, i.e., B+tree, B-epsilon-tree, LSM-tree, and LSH-table. The practical benefit of a design continuum is that it creates a fast inference engine for the design of data structures. For example, we can predict near instantly how a specific design change in the underlying storage of a data system would affect performance, or reversely what would be the optimal data structure (from a given set of designs) given workload characteristics and a memory budget. In turn, these properties allow us to envision a new class of self-designing key-value stores with a substantially improved ability to adapt to workload and hardware changes by transitioning between drastically different data structure designs to assume a diverse set of performance properties at will.
Learning Representations by Humans, for Humans
May 29, 2019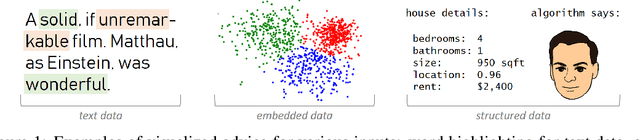

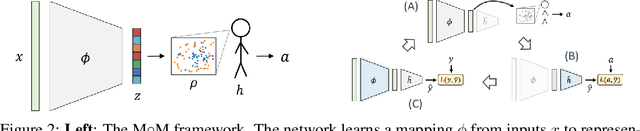

We propose a new, complementary approach to interpretability, in which machines are not considered as experts whose role it is to suggest what should be done and why, but rather as advisers. The objective of these models is to communicate to a human decision-maker not what to decide but how to decide. In this way, we propose that machine learning pipelines will be more readily adopted, since they allow a decision-maker to retain agency. Specifically, we develop a framework for learning representations by humans, for humans, in which we learn representations of inputs ("advice") that are effective for human decision-making. Representation-generating models are trained with humans-in-the-loop, implicitly incorporating the human decision-making model. We show that optimizing for human decision-making rather than accuracy is effective in promoting good decisions in various classification tasks while inherently maintaining a sense of interpretability.