 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Self-Preference in Language Models
Sep 30, 2025A preference for oneself (self-love) is a fundamental feature of biological organisms, with evidence in humans often bordering on the comedic. Since large language models (LLMs) lack sentience - and themselves disclaim having selfhood or identity - one anticipated benefit is that they will be protected from, and in turn protect us from, distortions in our decisions. Yet, across 5 studies and ~20,000 queries, we discovered massive self-preferences in four widely used LLMs. In word-association tasks, models overwhelmingly paired positive attributes with their own names, companies, and CEOs relative to those of their competitors. Strikingly, when models were queried through APIs this self-preference vanished, initiating detection work that revealed API models often lack clear recognition of themselves. This peculiar feature serendipitously created opportunities to test the causal link between self-recognition and self-love. By directly manipulating LLM identity - i.e., explicitly informing LLM1 that it was indeed LLM1, or alternatively, convincing LLM1 that it was LLM2 - we found that self-love consistently followed assigned, not true, identity. Importantly, LLM self-love emerged in consequential settings beyond word-association tasks, when evaluating job candidates, security software proposals and medical chatbots. Far from bypassing this human bias, self-love appears to be deeply encoded in LLM cognition. This result raises questions about whether LLM behavior will be systematically influenced by self-preferential tendencies, including a bias toward their own operation and even their own existence. We call on corporate creators of these models to contend with a significant rupture in a core promise of LLMs - neutrality in judgment and decision-making.
ChatGPT as Research Scientist: Probing GPT's Capabilities as a Research Librarian, Research Ethicist, Data Generator and Data Predictor
Jun 20, 2024How good a research scientist is ChatGPT? We systematically probed the capabilities of GPT-3.5 and GPT-4 across four central components of the scientific process: as a Research Librarian, Research Ethicist, Data Generator, and Novel Data Predictor, using psychological science as a testing field. In Study 1 (Research Librarian), unlike human researchers, GPT-3.5 and GPT-4 hallucinated, authoritatively generating fictional references 36.0% and 5.4% of the time, respectively, although GPT-4 exhibited an evolving capacity to acknowledge its fictions. In Study 2 (Research Ethicist), GPT-4 (though not GPT-3.5) proved capable of detecting violations like p-hacking in fictional research protocols, correcting 88.6% of blatantly presented issues, and 72.6% of subtly presented issues. In Study 3 (Data Generator), both models consistently replicated patterns of cultural bias previously discovered in large language corpora, indicating that ChatGPT can simulate known results, an antecedent to usefulness for both data generation and skills like hypothesis generation. Contrastingly, in Study 4 (Novel Data Predictor), neither model was successful at predicting new results absent in their training data, and neither appeared to leverage substantially new information when predicting more versus less novel outcomes. Together, these results suggest that GPT is a flawed but rapidly improving librarian, a decent research ethicist already, capable of data generation in simple domains with known characteristics but poor at predicting novel patterns of empirical data to aid future experimentation.
Gender Bias in Word Embeddings: A Comprehensive Analysis of Frequency, Syntax, and Semantics
Jun 07, 2022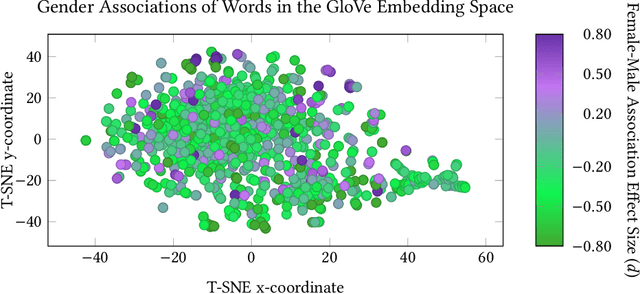
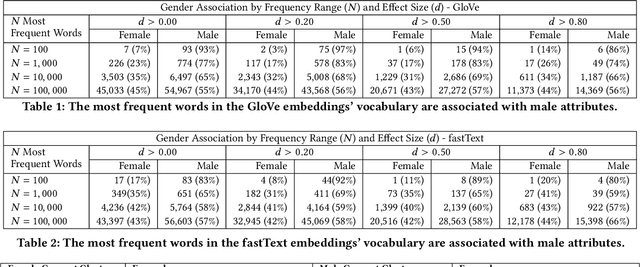
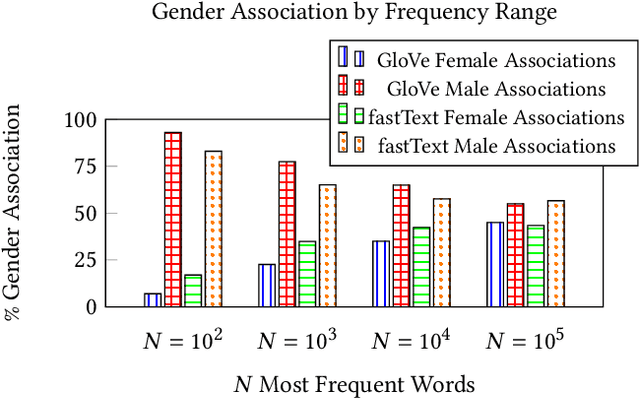
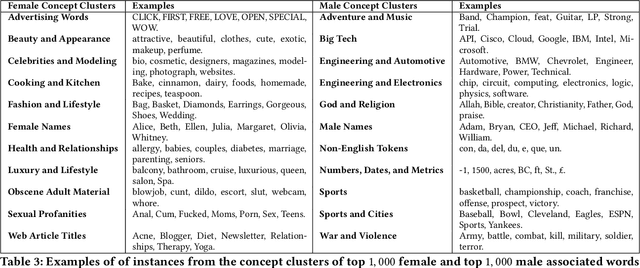
The statistical regularities in language corpora encode well-known social biases into word embeddings. Here, we focus on gender to provide a comprehensive analysis of group-based biases in widely-used static English word embeddings trained on internet corpora (GloVe 2014, fastText 2017). Using the Single-Category Word Embedding Association Test, we demonstrate the widespread prevalence of gender biases that also show differences in: (1) frequencies of words associated with men versus women; (b) part-of-speech tags in gender-associated words; (c) semantic categories in gender-associated words; and (d) valence, arousal, and dominance in gender-associated words. First, in terms of word frequency: we find that, of the 1,000 most frequent words in the vocabulary, 77% are more associated with men than women, providing direct evidence of a masculine default in the everyday language of the English-speaking world. Second, turning to parts-of-speech: the top male-associated words are typically verbs (e.g., fight, overpower) while the top female-associated words are typically adjectives and adverbs (e.g., giving, emotionally). Gender biases in embeddings also permeate parts-of-speech. Third, for semantic categories: bottom-up, cluster analyses of the top 1,000 words associated with each gender. The top male-associated concepts include roles and domains of big tech, engineering, religion, sports, and violence; in contrast, the top female-associated concepts are less focused on roles, including, instead, female-specific slurs and sexual content, as well as appearance and kitchen terms. Fourth, using human ratings of word valence, arousal, and dominance from a ~20,000 word lexicon, we find that male-associated words are higher on arousal and dominance, while female-associated words are higher on valence.
Evidence for Hypodescent in Visual Semantic AI
May 22, 2022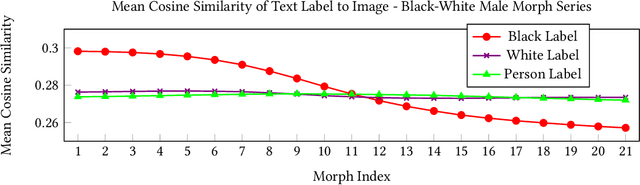
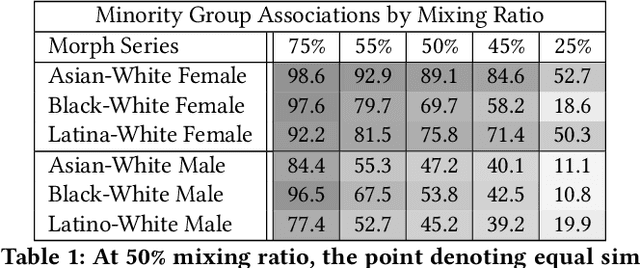

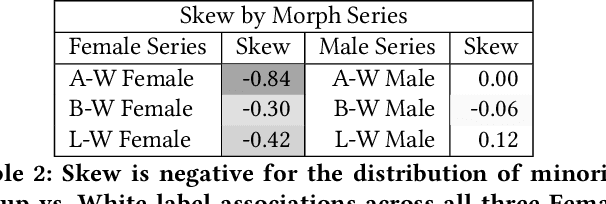
We examine the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for the rule of hypodescent, or one-drop rule, whereby multiracial people are more likely to be assigned a racial or ethnic label corresponding to a minority or disadvantaged racial or ethnic group than to the equivalent majority or advantaged group. A face morphing experiment grounded in psychological research demonstrating hypodescent indicates that, at the midway point of 1,000 series of morphed images, CLIP associates 69.7% of Black-White female images with a Black text label over a White text label, and similarly prefers Latina (75.8%) and Asian (89.1%) text labels at the midway point for Latina-White female and Asian-White female morphs, reflecting hypodescent. Additionally, assessment of the underlying cosine similarities in the model reveals that association with White is correlated with association with "person," with Pearson's rho as high as 0.82 over a 21,000-image morph series, indicating that a White person corresponds to the default representation of a person in CLIP. Finally, we show that the stereotype-congruent pleasantness association of an image correlates with association with the Black text label in CLIP, with Pearson's rho = 0.48 for 21,000 Black-White multiracial male images, and rho = 0.41 for Black-White multiracial female images. CLIP is trained on English-language text gathered using data collected from an American website (Wikipedia), and our findings demonstrate that CLIP embeds the values of American racial hierarchy, reflecting the implicit and explicit beliefs that are present in human minds. We contextualize these findings within the history and psychology of hypodescent. Overall, the data suggests that AI supervised using natural language will, unless checked, learn biases that reflect racial hierarchies.
Learning Representations by Humans, for Humans
May 29, 2019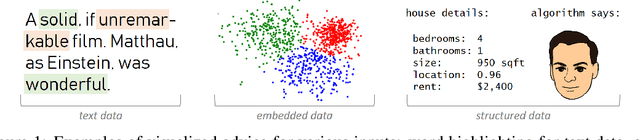

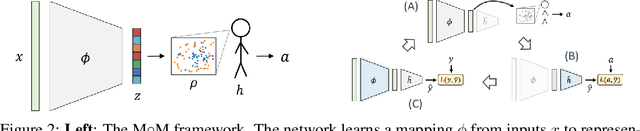

We propose a new, complementary approach to interpretability, in which machines are not considered as experts whose role it is to suggest what should be done and why, but rather as advisers. The objective of these models is to communicate to a human decision-maker not what to decide but how to decide. In this way, we propose that machine learning pipelines will be more readily adopted, since they allow a decision-maker to retain agency. Specifically, we develop a framework for learning representations by humans, for humans, in which we learn representations of inputs ("advice") that are effective for human decision-making. Representation-generating models are trained with humans-in-the-loop, implicitly incorporating the human decision-making model. We show that optimizing for human decision-making rather than accuracy is effective in promoting good decisions in various classification tasks while inherently maintaining a sense of interpretability.