 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence for Hypodescent in Visual Semantic AI
Paper and Code
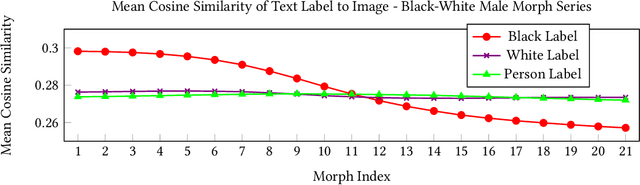
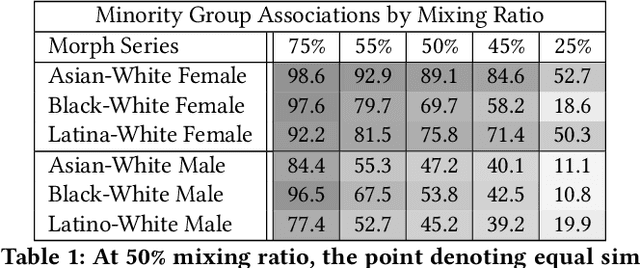

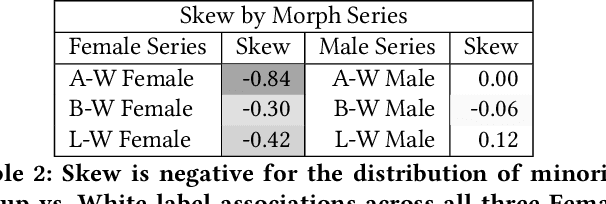
We examine the state-of-the-art multimodal "visual semantic" model CLIP ("Contrastive Language Image Pretraining") for the rule of hypodescent, or one-drop rule, whereby multiracial people are more likely to be assigned a racial or ethnic label corresponding to a minority or disadvantaged racial or ethnic group than to the equivalent majority or advantaged group. A face morphing experiment grounded in psychological research demonstrating hypodescent indicates that, at the midway point of 1,000 series of morphed images, CLIP associates 69.7% of Black-White female images with a Black text label over a White text label, and similarly prefers Latina (75.8%) and Asian (89.1%) text labels at the midway point for Latina-White female and Asian-White female morphs, reflecting hypodescent. Additionally, assessment of the underlying cosine similarities in the model reveals that association with White is correlated with association with "person," with Pearson's rho as high as 0.82 over a 21,000-image morph series, indicating that a White person corresponds to the default representation of a person in CLIP. Finally, we show that the stereotype-congruent pleasantness association of an image correlates with association with the Black text label in CLIP, with Pearson's rho = 0.48 for 21,000 Black-White multiracial male images, and rho = 0.41 for Black-White multiracial female images. CLIP is trained on English-language text gathered using data collected from an American website (Wikipedia), and our findings demonstrate that CLIP embeds the values of American racial hierarchy, reflecting the implicit and explicit beliefs that are present in human minds. We contextualize these findings within the history and psychology of hypodescent. Overall, the data suggests that AI supervised using natural language will, unless checked, learn biases that reflect racial hierarchies.