 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICTPolarReal: A Polarized Reflection and Material Dataset of Real World Objects
Mar 26, 2026Accurately modeling how real-world materials reflect light remains a core challenge in inverse rendering, largely due to the scarcity of real measured reflectance data. Existing approaches rely heavily on synthetic datasets with simplified illumination and limited material realism, preventing models from generalizing to real-world images. We introduce a large-scale polarized reflection and material dataset of real-world objects, captured with an 8-camera, 346-light Light Stage equipped with cross/parallel polarization. Our dataset spans 218 everyday objects across five acquisition dimensions-multiview, multi-illumination, polarization, reflectance separation, and material attributes-yielding over 1.2M high-resolution images with diffuse-specular separation and analytically derived diffuse albedo, specular albedo, and surface normals. Using this dataset, we train and evaluate state-of-the-art inverse and forward rendering models on intrinsic decomposition, relighting, and sparse-view 3D reconstruction, demonstrating significant improvements in material separation, illumination fidelity, and geometric consistency. We hope that our work can establish a new foundation for physically grounded material understanding and enable real-world generalization beyond synthetic training regimes. Project page: https://jingyangcarl.github.io/ICTPolarReal/
Composer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
How can we fool LIME and SHAP? Adversarial Attacks on Post hoc Explanation Methods
Nov 06, 2019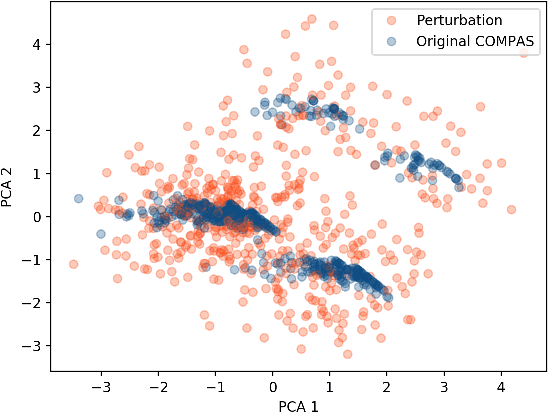

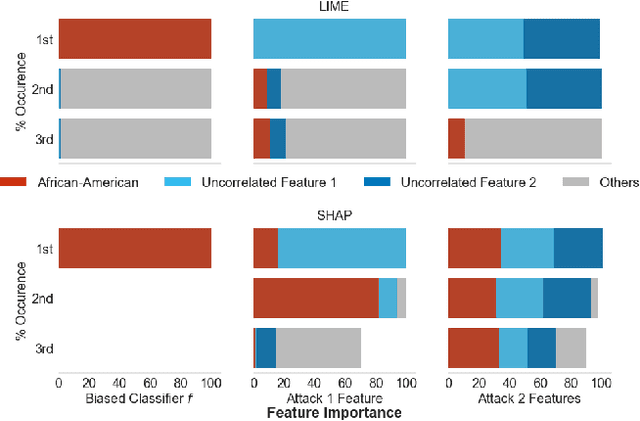

As machine learning black boxes are increasingly being deployed in domains such as healthcare and criminal justice, there is growing emphasis on building tools and techniques for explaining these black boxes in an interpretable manner. Such explanations are being leveraged by domain experts to diagnose systematic errors and underlying biases of black boxes. In this paper, we demonstrate that post hoc explanations techniques that rely on input perturbations, such as LIME and SHAP, are not reliable. Specifically, we propose a novel scaffolding technique that effectively hides the biases of any given classifier by allowing an adversarial entity to craft an arbitrary desired explanation. Our approach can be used to scaffold any biased classifier in such a way that its predictions on the input data distribution still remain biased, but the post hoc explanations of the scaffolded classifier look innocuous. Using extensive evaluation with multiple real-world datasets (including COMPAS), we demonstrate how extremely biased (racist) classifiers crafted by our framework can easily fool popular explanation techniques such as LIME and SHAP into generating innocuous explanations which do not reflect the underlying biases.