 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould Demand Models Incorporate Competitor Prices? Oblivious Learning and Algorithmic Collusion
Jun 03, 2026On a platform with many sellers, should a pricing algorithm explicitly model competitors' prices when learning demand? Classical learning arguments suggest an affirmative answer: ignoring competitors induces model misspecification and inefficiency. In contrast, recent work on algorithmic collusion suggests that strategic obliviousness -- deliberately ignoring competitor prices -- may facilitate collusive outcomes and improve profits. We study this modeling choice in a stylized competitive market with unknown noisy demand, in which multiple sellers repeatedly set prices and estimate demand via iterated least squares, and either incorporate competitors' prices into their demand models (informed) or ignore them (oblivious). We first show that, relative to a monopolist, an oblivious seller in a competitive market must explore more aggressively to compensate for the loss of dynamic competitor information. Building on this insight, we characterize market dynamics when all sellers are oblivious and show that prices converge to the competitive outcome under sufficient exploration, while a continuum of pseudo-equilibria arises when exploration decays. Analyzing the resulting price trajectories, we uncover an excursion phenomenon that gives rise to transient collusive patterns that dissipate as learning progresses. In markets with both oblivious and informed sellers, the informed strictly out-earn the oblivious. Read as a strategy game, the modeling choice has a unique Nash equilibrium: the all-informed market, in which prices converge to the competitive outcome efficiently. Overall, our results indicate that collusive patterns are not robust and are not sustained by oblivious modeling; therefore, incorporating competitor information, together with sufficient price exploration, remains a reliable strategy for sellers in competitive markets.
Variance-Adaptive Optimal Algorithm for Reinforcement Learning with Multinomial Logit Function Approximation
May 27, 2026Reinforcement learning with multinomial logistic (MNL) function approximation has become an important framework due to its flexibility and broad applicability. While existing studies have established regret guarantees under worst-case analysis, they do not capture how performance depends on the variability of the interaction between the learner and the environment. In this paper, we develop a new theoretical analysis for MNL-based Markov decision processes that yields explicit variance-adaptive regret bounds. Our algorithm is computationally efficient and achieves the instance-wise optimal rate of regret, narrowing the gap between upper and lower bounds. Our numerical experiments validate that our method learns optimal policies more efficiently than conventional approaches.
The Cost of Learning under Multiple Change Points
Feb 11, 2026We consider an online learning problem in environments with multiple change points. In contrast to the single change point problem that is widely studied using classical "high confidence" detection schemes, the multiple change point environment presents new learning-theoretic and algorithmic challenges. Specifically, we show that classical methods may exhibit catastrophic failure (high regret) due to a phenomenon we refer to as endogenous confounding. To overcome this, we propose a new class of learning algorithms dubbed Anytime Tracking CUSUM (ATC). These are horizon-free online algorithms that implement a selective detection principle, balancing the need to ignore "small" (hard-to-detect) shifts, while reacting "quickly" to significant ones. We prove that the performance of a properly tuned ATC algorithm is nearly minimax-optimal; its regret is guaranteed to closely match a novel information-theoretic lower bound on the achievable performance of any learning algorithm in the multiple change point problem. Experiments on synthetic as well as real-world data validate the aforementioned theoretical findings.
A Broader View of Thompson Sampling
Oct 08, 2025Thompson Sampling is one of the most widely used and studied bandit algorithms, known for its simple structure, low regret performance, and solid theoretical guarantees. Yet, in stark contrast to most other families of bandit algorithms, the exact mechanism through which posterior sampling (as introduced by Thompson) is able to "properly" balance exploration and exploitation, remains a mystery. In this paper we show that the core insight to address this question stems from recasting Thompson Sampling as an online optimization algorithm. To distill this, a key conceptual tool is introduced, which we refer to as "faithful" stationarization of the regret formulation. Essentially, the finite horizon dynamic optimization problem is converted into a stationary counterpart which "closely resembles" the original objective (in contrast, the classical infinite horizon discounted formulation, that leads to the Gittins index, alters the problem and objective in too significant a manner). The newly crafted time invariant objective can be studied using Bellman's principle which leads to a time invariant optimal policy. When viewed through this lens, Thompson Sampling admits a simple online optimization form that mimics the structure of the Bellman-optimal policy, and where greediness is regularized by a measure of residual uncertainty based on point-biserial correlation. This answers the question of how Thompson Sampling balances exploration-exploitation, and moreover, provides a principled framework to study and further improve Thompson's original idea.
Linear Bandits with Partially Observable Features
Feb 10, 2025We introduce a novel linear bandit problem with partially observable features, resulting in partial reward information and spurious estimates. Without proper address for latent part, regret possibly grows linearly in decision horizon $T$, as their influence on rewards are unknown. To tackle this, we propose a novel analysis to handle the latent features and an algorithm that achieves sublinear regret. The core of our algorithm involves (i) augmenting basis vectors orthogonal to the observed feature space, and (ii) introducing an efficient doubly robust estimator. Our approach achieves a regret bound of $\tilde{O}(\sqrt{(d + d_h)T})$, where $d$ is the dimension of observed features, and $d_h$ is the unknown dimension of the subspace of the unobserved features. Notably, our algorithm requires no prior knowledge of the unobserved feature space, which may expand as more features become hidden. Numerical experiments confirm that our algorithm outperforms both non-contextual multi-armed bandits and linear bandit algorithms depending solely on observed features.
A Doubly Robust Approach to Sparse Reinforcement Learning
Oct 23, 2023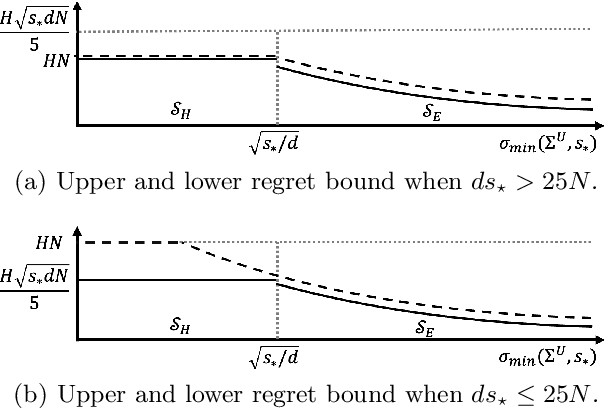
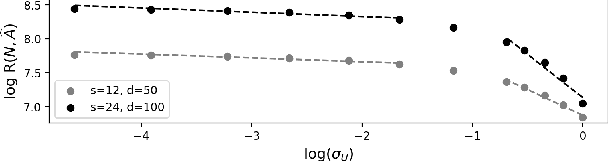
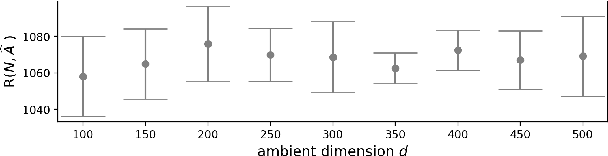
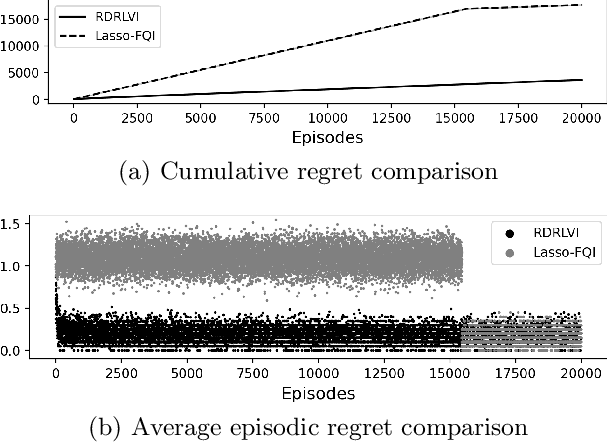
We propose a new regret minimization algorithm for episodic sparse linear Markov decision process (SMDP) where the state-transition distribution is a linear function of observed features. The only previously known algorithm for SMDP requires the knowledge of the sparsity parameter and oracle access to an unknown policy. We overcome these limitations by combining the doubly robust method that allows one to use feature vectors of \emph{all} actions with a novel analysis technique that enables the algorithm to use data from all periods in all episodes. The regret of the proposed algorithm is $\tilde{O}(\sigma^{-1}_{\min} s_{\star} H \sqrt{N})$, where $\sigma_{\min}$ denotes the restrictive the minimum eigenvalue of the average Gram matrix of feature vectors, $s_\star$ is the sparsity parameter, $H$ is the length of an episode, and $N$ is the number of rounds. We provide a lower regret bound that matches the upper bound up to logarithmic factors on a newly identified subclass of SMDPs. Our numerical experiments support our theoretical results and demonstrate the superior performance of our algorithm.
Bayesian Design Principles for Frequentist Sequential Learning
Oct 01, 2023



We develop a general theory to optimize the frequentist regret for sequential learning problems, where efficient bandit and reinforcement learning algorithms can be derived from unified Bayesian principles. We propose a novel optimization approach to generate "algorithmic beliefs" at each round, and use Bayesian posteriors to make decisions. The optimization objective to create "algorithmic beliefs," which we term "Algorithmic Information Ratio," represents an intrinsic complexity measure that effectively characterizes the frequentist regret of any algorithm. To the best of our knowledge, this is the first systematical approach to make Bayesian-type algorithms prior-free and applicable to adversarial settings, in a generic and optimal manner. Moreover, the algorithms are simple and often efficient to implement. As a major application, we present a novel algorithm for multi-armed bandits that achieves the "best-of-all-worlds" empirical performance in the stochastic, adversarial, and non-stationary environments. And we illustrate how these principles can be used in linear bandits, bandit convex optimization, and reinforcement learning.
Last Switch Dependent Bandits with Monotone Payoff Functions
Jun 01, 2023In a recent work, Laforgue et al. introduce the model of last switch dependent (LSD) bandits, in an attempt to capture nonstationary phenomena induced by the interaction between the player and the environment. Examples include satiation, where consecutive plays of the same action lead to decreased performance, or deprivation, where the payoff of an action increases after an interval of inactivity. In this work, we take a step towards understanding the approximability of planning LSD bandits, namely, the (NP-hard) problem of computing an optimal arm-pulling strategy under complete knowledge of the model. In particular, we design the first efficient constant approximation algorithm for the problem and show that, under a natural monotonicity assumption on the payoffs, its approximation guarantee (almost) matches the state-of-the-art for the special and well-studied class of recharging bandits (also known as delay-dependent). In this attempt, we develop new tools and insights for this class of problems, including a novel higher-dimensional relaxation and the technique of mirroring the evolution of virtual states. We believe that these novel elements could potentially be used for approaching richer classes of action-induced nonstationary bandits (e.g., special instances of restless bandits). In the case where the model parameters are initially unknown, we develop an online learning adaptation of our algorithm for which we provide sublinear regret guarantees against its full-information counterpart.
Pareto Front Identification with Regret Minimization
May 31, 2023



We consider Pareto front identification for linear bandits (PFILin) where the goal is to identify a set of arms whose reward vectors are not dominated by any of the others when the mean reward vector is a linear function of the context. PFILin includes the best arm identification problem and multi-objective active learning as special cases. The sample complexity of our proposed algorithm is $\tilde{O}(d/\Delta^2)$, where $d$ is the dimension of contexts and $\Delta$ is a measure of problem complexity. Our sample complexity is optimal up to a logarithmic factor. A novel feature of our algorithm is that it uses the contexts of all actions. In addition to efficiently identifying the Pareto front, our algorithm also guarantees $\tilde{O}(\sqrt{d/t})$ bound for instantaneous Pareto regret when the number of samples is larger than $\Omega(d\log dL)$ for $L$ dimensional vector rewards. By using the contexts of all arms, our proposed algorithm simultaneously provides efficient Pareto front identification and regret minimization. Numerical experiments demonstrate that the proposed algorithm successfully identifies the Pareto front while minimizing the regret.
Improved Algorithms for Multi-period Multi-class Packing Problems with~Bandit~Feedback
Jan 31, 2023We consider the linear contextual multi-class multi-period packing problem~(LMMP) where the goal is to pack items such that the total vector of consumption is below a given budget vector and the total value is as large as possible. We consider the setting where the reward and the consumption vector associated with each action is a class-dependent linear function of the context, and the decision-maker receives bandit feedback. LMMP includes linear contextual bandits with knapsacks and online revenue management as special cases. We establish a new more efficient estimator which guarantees a faster convergence rate, and consequently, a lower regret in such problems. We propose a bandit policy that is a closed-form function of said estimated parameters. When the contexts are non-degenerate, the regret of the proposed policy is sublinear in the context dimension, the number of classes, and the time horizon~$T$ when the budget grows at least as $\sqrt{T}$. We also resolve an open problem posed in Agrawal & Devanur (2016), and extend the result to a multi-class setting. Our numerical experiments clearly demonstrate that the performance of our policy is superior to other benchmarks in the literature.